



一种融合网络流量成本的安卓应用推荐方法
摘要
当前应用市场为终端用户提供大量且多样化的移动应用。现有的移动应用市场通常通过推荐最流行的移动应用来帮助用户进行合适的选择。然而,这些应用通常会产生网络流量,消耗用户的移动数据套餐,甚至可能引发潜在的安全问题。因此,越来越多的移动用户对应用市场所推荐的应用表现出犹豫甚至抵触情绪。为了弥补这一关键缺口,我们提出了一种移动应用推荐方法,能够在推荐过程中同时考虑应用流行度及其流量成本。为实现该目标,我们首先基于二分图估算应用程序的网络流量得分;然后,提出一种基于 Benefit-Cost analysis的灵活方法,可在应用流行度与流量成本之间保持平衡,从而实现应用推荐。最后,我们在从谷歌商店收集的大规模数据集上进行了大量实验以评估所提方法。实验结果明确验证了该方法的有效性和高效性。
1 引言
近年来,随着智能手机和平板电脑数量的激增,移动应用(应用程序)的流行度和数量也显著增长。然而,移动应用之间差异较大,且人们对其与网络流量使用相关的活动和功能往往了解甚少。此外,一些恶意软件或第三方广告(ad)库可能会收集隐私信息并发送至远程服务器[1],这可能导致用户面临潜在的安全问题。因此,开发一种能够感知网络流量使用的移动应用推荐系统,对于移动应用行业的健康发展至关重要。
最近,针对移动应用的网络流量分析以及移动应用推荐已有一些研究。一些先前的研究工作专注于移动应用识别[2]或对移动应用进行网络流量特征刻画[3]。然而,关于移动应用运行时的网络流量使用情况的研究还较少,而这一点对于合理使用移动数据套餐以及保障安全和隐私都具有重要意义。同时,在移动应用推荐领域,一些先前的研究探讨了个性化应用推荐方法[4,5],Appolicious则利用评论、好友推荐以及终端用户当前已安装的应用列表来对移动应用进行排名和推荐。
为了解决这些局限性,我们提出了一种融合网络流量成本的移动应用推荐方法。首先,该方法通过分析产生的网络流量,基于随机游走正则化和应用-主机二分图来度量每个移动应用的网络流量成本,从而能够自动学习移动应用的流量成本,而无需依赖任何预定义的流量成本函数。然后,基于现代投资组合理论,我们开发了一种灵活优化方法,在推荐应用程序时同时考虑应用程序的流行度和用户对流量成本的关注。最后,我们在从谷歌商店收集的真实数据集上进行了大量实验,以评估我们的移动应用推荐方法,该数据集包含2,200个安卓应用程序。实验结果在不同评估指标下明确验证了我们方法的有效性和高效性。
总之,本工作的主要贡献如下:
– 我们提出并实现了一种移动应用推荐系统,该系统可根据三种不同标准推荐移动应用:应用流行度、流量成本和混合方法。
– 我们提出了一种方法,可准确估计每个移动应用的网络流量成本分数,用于排序,且不依赖于任何预定义流量成本函数。
– 我们在真实世界数据集上通过大量实验对推荐系统进行了评估,实验结果表明,我们的推荐系统不仅能够基于应用流行度或流量成本单独进行推荐,还能够同时结合这两个标准进行推荐。
本文其余部分组织如下。第2节介绍推荐系统的框架。第3节描述流量成本分数估计。第4节讨论移动应用排序的细节。在第5节中,我们使用真实世界的移动流量轨迹评估我们的方法。我们在第6节总结相关工作,并在第7节中得出结论。
2 系统概述
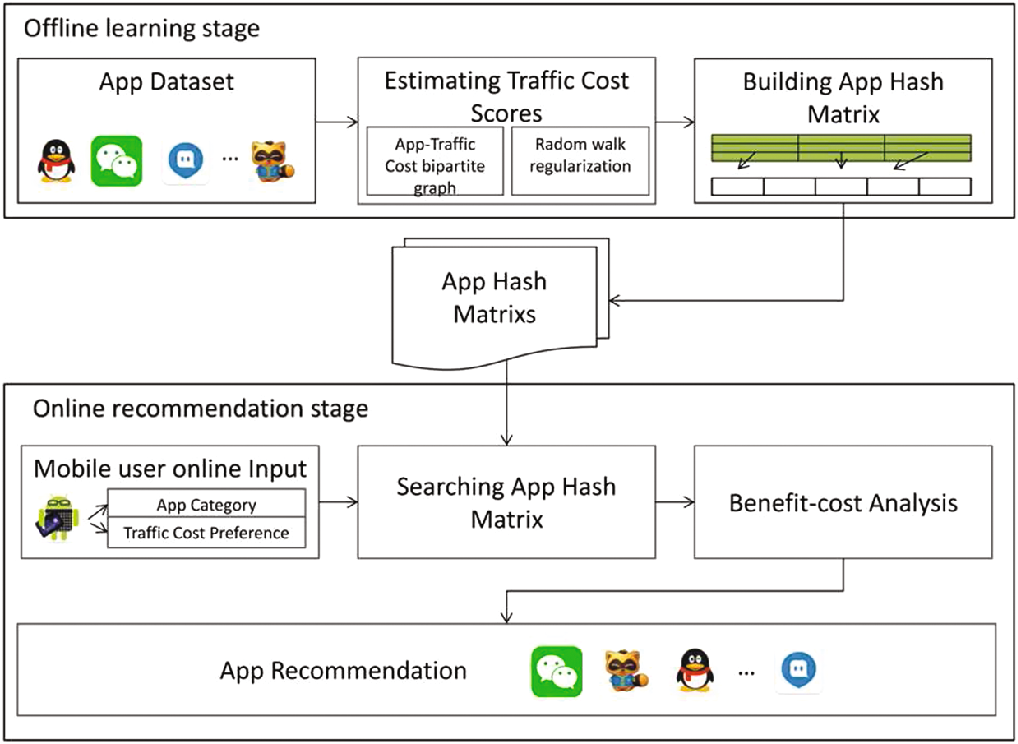
图1显示了所提出的推荐框架,该框架包含两个阶段。其中,离线学习阶段通过利用随机游走正则化和应用-主机二分图,自动学习应用程序的流量成本评分,并从应用数据集构建应用哈希矩阵,以高效管理应用程序。在线推荐阶段根据应用哈希矩阵匹配给定的流量成本和应用类别,并结合应用程序的流行度和流量成本,利用成本效益分析对候选应用进行排序以生成推荐。
3 流量成本评分估计
在本节中,我们将解释如何估算移动应用的流量成本分数,该分数反映了移动应用的流量成本等级。分数越小,表示应用程序的成本越低。我们可知流量成本本质上是由应用程序生成的流量及其访问的不同来源引起的,例如原始流量或CDN+云流量。其中一些流量由第三方库甚至恶意代码引起,而这些对应用程序并非必需。因此,衡量应用程序流量成本的一种直观方法是直接检查它们在访问时每种宿主的流量大小。
3.1 应用-流量成本二分图
本文提出了一种基于二分图的正则化方法[6],该方法能够自动学习移动应用的流量成本,而无需依赖任何预定义流量成本函数。具体而言,我们构建了一个应用-流量成本二分图,用于建立应用程序与流量成本之间的连接,其定义如下。
该图可以表示为 G={V, E, W}。V={Va, Vt}是节点集,其中 Va={a1,…, aM}表示应用程序集合,Vh={h1,…, hN}表示应用程序访问的不同类型宿主的集合。E是边集,其中当且仅当 ai在执行过程中访问 hj 时,eij ∈ E存在。W是边权重集,其中每个 wij ∈ W表示 eij 的权重,并表示 ai在执行过程中访问 hj 的概率。
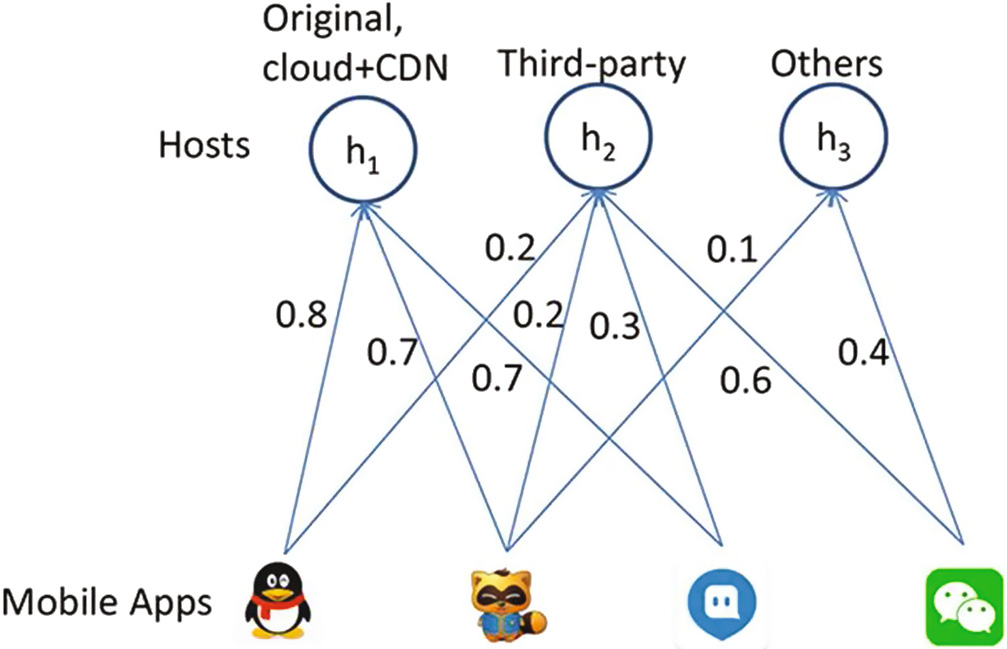
图2显示了一个应用-流量成本二分图的示例。直观上,权重 wij可以通过 ai所属类别中所有应用程序的流量记录来估计。由于应用程序访问的每种宿主的流量大小不同。具体而言,我们可以通过以下方式计算权重:
$$
w_{ij} = \frac{f_{ij}}{\sum_{e_{ik} \in E} f_{ik}} \times T, \quad T = \frac{\text{Trafficsize}
{a_i,h_j}}{\sum
{i=1}^{N} \text{Trafficsize}_{a_i,h_j}}, \quad (j = 1,…, M)
$$
其中,fij 是类别 c(ai∈c)中访问宿主 hj 的应用程序数量,参数 T 表示类别 c 中每个应用程序访问宿主 hj 产生的流量大小与该类别中所有应用程序访问宿主 hj 产生的总流量大小之比。此外,我们可以将每个应用程序 aj 和访问的主机 hj 分别表示为向量 ai= wi1,…, wiN 和 hj= w1j,…, wMj。相应地,我们通过余弦距离定义应用程序 ai 和 aj 之间的潜在相似度。
$$
s_{ia_j} = \text{Cos}(a_i, a_j) = \frac{a_i \cdot a_j}{|a_i| \cdot |a_j|}
$$
类似地,我们将访问的主机 hi 和 hj 之间的潜在相似度定义为 $ s_{ih_j} = \text{Cos}(h_i, h_j) $。
3.2 流量成本评分估计
为了利用应用-流量成本二分图估算应用流量成本分数,我们首先为节点 ai∈Va 和 hj ∈Vh,分别定义两个流量成本评分 Cost(ai)和 Cost(hj)。直观上,Cost(ai) 是目标应用流量成本分数,而 Cost(hj) 是全局宿主成本分数。其次,我们通过在二分图上对上述两个评分的平滑性进行正则化,构建一个正则化框架。
我们将 Cost(ai)表示为 Cia,将 Cost(hj)表示为 Chj,并定义如下成本函数:
$$
\mathcal{L}(a, h) = \frac{\lambda}{2} \cdot \left{ \sum_i | C_{a_i} - \tilde{C}
{a_i} |^2 + \sum_j | C
{h_j} - \tilde{C}
{h_j} |^2 \right}
+ \frac{\mu}{2} \cdot \left{ \sum
{i,j} s_{ia_j} | C_{a_i} - C_{a_j} |^2 + \sum_{i,j} s_{ih_j} | C_{h_i} - C_{h_j} |^2 \right} + \frac{1}{2} \cdot \sum_{i,j} w_{ij} | C_{a_i} - C_{h_j} |^2
$$
其中 λ 和 μ 是正则化参数,$\tilde{C} {a_i}$ 和 $\tilde{C} {h_j}$ 是从外部知识中获得的先验流量成本评分。
直观上,该成本函数由三部分构成。第一部分由 λ 控制,定义了两个流量成本分数应符合先验知识的约束。第二部分由 μ 控制,定义了优化后的流量成本评分在整个图上的全局一致性。具体而言,若两个应用程序及其访问的主机具有较高的潜在相似度,则它们的流量成本分数应相近。第三部分是应用程序与访问的主机之间的平滑约束,保证如果一个应用程序高概率访问某一类宿主,则它们的流量成本分数应相似。因此,估计流量成本分数的问题转化为寻找最优的 Cai 和 Chj 以最小化成本函数 $\mathcal{L}$ 的优化问题。本文中,我们采用经典的梯度下降法来解决此问题。具体而言,我们首先为 $ C_{a_i} = \frac{1}{M} $ 和 $ C_{h_j} = \frac{1}{N} $ 赋值,并通过将以下微分结果设为零来迭代更新它们。
$$
\frac{\partial \mathcal{L}}{\partial a_i} = \lambda(C_{a_i} - \tilde{C}
{a_i}) + \mu \sum_j s
{ia_j}(C_{a_i} - C_{a_j}) + \sum_j w_{ij}(C_{a_i} - C_{h_j}),
$$
$$
C_{a_i} = \frac{\lambda \tilde{C}
{a_i} + \mu \sum_j s
{ia_j} C_{a_j} + \sum_j w_{ij} C_{h_j}}{\lambda + \mu \sum_j s_{ia_j} + \sum_j w_{ij}}.
$$
$$
\frac{\partial \mathcal{L}}{\partial h_j} = \lambda(C_{h_j} - \tilde{C}
{h_j}) + \mu \sum_j s
{ih_j}(C_{h_j} - C_{h_i}) + \sum_j w_{ij}(C_{h_j} - C_{a_i}),
$$
$$
C_{h_j} = \frac{\lambda \tilde{C}
{h_i} + \mu \sum_j s
{ih_j} C_{h_j} + \sum_j w_{ij} C_{a_i}}{\lambda + \mu \sum_j s_{ih_j} + \sum_j w_{ij}}.
$$
每次迭代后,Cai 和 Chj 的所有值将再次归一化,即 ‖Ca‖₁ = 1 和 ‖Ch‖₁ = 1。最终,当结果收敛后,我们可以得到最优的流量成本评分。
根据上述公式3、4和5,我们注意到,估计流量成本分数的关键在于如何从外部知识中分配先验流量成本评分 $\tilde{C} {a_i}$ 和 $\tilde{C} {h_j}$。实际上,一些直观的解决方案包括邀请领域专家来分配流量成本评分,或构建流量监控通过外部流量数据报告,或利用相关领域中的先进流量模型。在本文中,作为一种尝试,我们利用Dempster-Shafer理论来完成此任务。
Dempster-Shafer理论(DST)使用一种称为“置信度”的概率推广形式来表征支持某一假设的证据的可信程度。根据移动应用生成的流量,可将其分为四种类型:原始流量、CDN+云流量、第三方流量以及其他流量。我们将移动应用产生的每种流量视为DST中的一条证据,并将DS中的识别框架设为 Θ={original, CDN+Cloudtraffic, third-partytraffic, othertraffic},其基本概率分配(bpa)定义为 mΘ : 2Θ →[0, 1]。基于 Θ和 bpa,DST的置信函数定义为
$$
\text{For } x \subseteq \Theta, \quad \text{Bel}(x) = \sum m_\Theta(x)
$$
其中 x 是 Θ 的一个真子集,且 m 表示为主观概率分配给 Θ 的所有子集。因此,宿主 hj 的流量成本评分可由 $ \tilde{C}_{h_j} = m(x) $ where x∈Θ 进行估计。
DST 具有一种组合方法,其目的是将来自多个独立源的关于某一假设的证据进行合并,并计算该假设的整体置信度[7]。通常我们采用以下组合规则,即 Dempster规则。
$$
\text{Bel}(A) = m_i(A) = \frac{1}{1 - K} \cdot \sum_{A_1 \cap … \cap A_n = A \neq \emptyset} m_1(A_1)m_2(A_2)…m_n(A_n)
$$
$$
K = \sum_{A_1 \cap … \cap A_n = \emptyset} m_1(A_1)m_2(A_2)…m_n(A_n)
$$
其中 K 是衡量两个 m 集合之间冲突程度的指标。因此,应用程序 ai 的流量成本评分可通过 $ C_{a_i} = m_{1,2,3}(A) $ 进行估计。需要注意的是,在学习我们的正则化框架之前,Chj 和 $\tilde{C}_{a_i}$ 均已归一化。尽管DST是一种直观的方法,无法解决前述所有挑战,但其在应用程序流量成本排序方面的有效性已得到充分证明。因此,在我们的正则化框架中使用DST作为先验知识是合适的。
4 移动应用排名
在本节中,我们计划基于混合标准对移动应用进行排序,并构建应用哈希矩阵以实现移动应用搜索。为实现这一目标,我们首先估算每个移动应用的流量成本等级。然后,我们解释如何根据应用流行度和网络流量成本对移动应用进行排序。
4.1 流量成本等级估计
在估算每个移动应用的流量成本分数后,我们可以根据其流量成本评分按升序对应用程序进行排名以进行应用推荐。此外,如果某些应用程序具有相同的流量成本评分,则将进一步根据其流行度分数(例如总体评分)进行排序。然而,在现实世界的应用推荐服务中,用户可能难以清晰地了解已排名应用程序的流量成本。一种帮助用户理解应用程序不同流量成本的有效方法是将流量成本划分为离散等级(例如低、中、高)。因此,由于缺乏适当的划分标准,我们提出了一种基于变异系数(CV)的方法,以获得关于流量成本评分的应用程序的准确且合适的划分。我们假设在全球排名列表中,两个相邻应用程序的流量成本评分存在较大差异,这种差异可以通过它们流量成本评分的变异系数(CV),例如 variation/mean,来捕捉。
4.2 基于混合标准的应用排名
现在,我们可以为用户推荐应用程序。直观上,应用推荐有两种类型的排序标准。
–
流行度标准
:我们首先根据应用候选的流行度分数(例如总体评分)按降序排列,具有相同流行度分数的应用将根据流量成本分数进一步排序。
–
流量成本标准
:我们首先根据应用候选的流量成本分数按升序排列,具有相同分数的应用将根据流行度分数(例如总体评分)进一步排序。
此外,我们需要在用户的流量成本偏好与应用程序的流行度之间取得平衡以进行推荐。为了实现这种平衡,我们还提出了一种基于成本效益分析的混合标准用于应用推荐[8]。该方法是一种通过比较活动的经济效益与经济成本来评估项目或投资的技术。在本文中,我们将一个项目视为一个应用程序,项目的成本和收益可分别视为应用程序的流量成本和流行度。例如,政府投资一个项目应能带来最大效益并造成最小成本。具体而言,一个项目 ρ 可以表示为一组 n 移动应用,并为每个应用分配相应的权重 wi。根据讨论,[9],该权重 wi 表示推荐系统希望目标用户对应用程序的关注程度 ai。因此,我们首先将一个应用的效益定义为 B(a),可通过以下方式计算
$$
B(a) = \sum_{i} w_i \cdot \frac{-1}{1 + r_i}
$$
其中 i 是应用 ai 在基于流行度的排序列表 Λ(Pop) 中的排名,ri 表示应用 ai 排名的波动比率。此外,我们将应用的成本定义为 C(ρ),可通过以下函数[10],计算
$$
C(a) = \sum_i \left( w_i^2 \nabla^{-2}
i + 2 \sum
{j=i+1}^{n} w_i w_j \nabla^{-1}
j J
{ij} \right)
$$
其中 ∇i 是应用程序 ai 在基于流量成本的排序列表 Λ(trafficcost) 中的排名,Jij 是应用程序 ai 和 aj 之间的流量成本相关性。在本文中,我们根据生成的流量的相似度来估计 Jij。对于任意两个应用程序,它们生成的共同类型的流量越多,其流量成本相似度就越高。我们通过使用应用程序 ai 和 aj 之间的杰卡德系数来计算 Jij。
$$
J_{ij} = \frac{N_{ij}}{N_i + N_j - N_{ij}}
$$
其中 Ni 是应用程序 ai 访问的不同类型的主机数量,Nij 是两个应用程序 ai 和 aj 访问的共同主机数量。
基于混合标准的推荐目标是学习一个最大净收益(MNP),以最大化收益并最小化由推荐候选(应用候选)组成的应用的成本。根据上述定义,我们可以正式定义 MNP 推荐问题如下。
给定一个应用程序集合 ai,其收益为 B(a),成本为 C(a)。MNP 推荐问题的目标是推荐一个具有最大净收益的应用集合,即
$$
\arg\max G(a) = B(a) - C(a)
$$
上述优化问题可以通过基于有效前沿的应用方法来解决,该方法在[9]中介绍。具体而言,我们可以通过获得最优权重来获得最大净收益 w* 通过
$$
w^
= \frac{
\begin{vmatrix}
1 & 1^T \Sigma^{-1} E \
E^
& E^T \Sigma^{-1} E \
\end{vmatrix}
\Sigma^{-1} 1 +
\begin{vmatrix}
1^T \Sigma^{-1} 1 & 1 \
E^T \Sigma^{-1} 1 & E^*
\end{vmatrix}
\Sigma^{-1} E
}{
\begin{vmatrix}
1^T \Sigma^{-1} 1 & 1^T \Sigma^{-1} E \
E^T \Sigma^{-1} 1 & E^T \Sigma^{-1} E \
\end{vmatrix}
}
$$
其中 $\Sigma_{ij} = \nabla^{-1} i \nabla^{-1}_j J {ij}$, $E = (\Lambda^{-1}_1, …, \Lambda^{-1}_n)^T$,且 E* 可通过以下方式计算
$$
E^* = \frac{(xz - y^2)^2 - 2b(xE - y1)^T \Sigma^{-1} (z1 - yE)}{2b(xE - y1)^T \Sigma^{-1} (xE - y1)}
$$
其中 x = 1^T Σ⁻¹ 1, y = 1^T Σ⁻¹ E, 和 z = E^T Σ⁻¹ E。
5 评估
5.1 数据集
实验移动应用数据集是从谷歌商店2012年12月到2013年1月期间收集的。我们下载了100个最流行(100个最高评分)得分来自22个最流行类别的移动应用,这些类别涵盖了谷歌商店中定义的大部分应用类别,例如游戏、图书等。我们选择每个类别中前100个应用的原因如下。在Petsas等人[11]的研究中,作者证明了应用流行度分布遵循典型的帕累托原则,即10%的应用占据了总下载量的70%至90%。这一现象表明,少量热门应用通常被大多数用户下载。
5.2 应用排名结果
我们根据执行移动应用的情况,手动标注了100个低流量成本的移动应用和100个高流量成本的移动应用作为训练数据。对于每个应用,我们使用其类别、apk包名和流量成本作为特征来学习排序模型。我们还选择了RankNet[12]、RankBoost[13]、ListNet[14],并将我们的方法与这些方法进行比较。图3展示了NDCG@K、Precision@K和ERR@K在K值从1到100时的比较结果。我们发现,基于流量成本的移动推荐(MRTC)在不同K值下始终优于先前方法。特别地,我们观察到MRTC在NDCG和ERR上优于其他三种方法。在NDCG方面,与RankNet、RankBoost和ListNet相比,MRTC平均分别提升了6.01%、1.96%和6.68%。在ERR方面,MRTC相比RankNet、RankBoost和ListNet分别提升了4.63%、17.74%和5.26%。表1显示了MRTC与其他三种排序方法在MAP指标上的比较结果。我们发现,我们的方法在MAP指标上能够取得比其他三种排序方法更高的值。基于这四个指标的结果,我们发现我们的方法能够实现更好的排序性能,同时也是估算移动应用流量成本的一种合适方法。
(a) NDCG@K
(b) Precision@K
(c) ERR@K
表1. 评估实验中使用的流量轨迹摘要
| Metric | RankNet | RankBoost | ListNet | MRTC |
|---|---|---|---|---|
| MAP | 0.4472 | 0.3962 | 0.4405 | 0.4673 |
5.3 移动应用推荐结果
整体性能。 由于没有真实数据可供评估哪些推荐结果能满足用户需求,本次评估的目标是检验我们的推荐方法是否能够在移动应用流行度和用户流量成本偏好之间实现平衡。为实现此目标,我们仍然选择NDCG作为评估指标来评价我们推荐方法的性能。具体而言,我们的推荐方法中包含三种不同的排序标准,即流行度、流量成本和混合标准。给定一个应用数据集和流量成本等级,每种标准均可生成一个排序的应用列表作为推荐结果。在此评估中,我们使用两种类型的NDCG来评估每个推荐结果的性能。NDCG_Pop 表示基于应用流行度的推荐结果,NDCG_TC 表示基于应用流量成本的推荐结果。如果某个推荐结果具有更高的NDCG_Pop(NDCG_TC),意味着该结果更侧重于应用流行度(应用流量成本)。图4展示了基于三种不同排序标准在三个不同流量成本等级上的推荐性能。等级1包含流量成本最高的移动应用,等级3包含流量成本中等的应用,等级5包含流量成本最低的应用。从结果中我们可以得出三点观察:第一,按流行度推荐的结果在每一级中的NDCG_Pop均高于NDCG_TC;第二,按流量成本推荐的结果在每一级中的NDCG_TC均高于NDCG_Pop;第三,混合推荐方法能够在流行度和流量成本之间实现权衡。
(a)等级1
(b)等级3
(c) 等级5
相似功能移动应用推荐。 众所周知,谷歌商店为用户提供海量的安卓应用程序可供下载。其中有许多并不知名的应用程序,例如卸载工具应用等,用户并不清楚应选择哪个具体的应用程序来实现所需的功能。此外,根据我们的观察,这些具有相似功能的应用程序在运行时产生的流量成本各不相同。为了进一步研究并评估我们方法的推荐性能,我们选择具有相似功能的移动应用作为案例研究。我们选择了6个应用程序具有相似功能,它们分别是Easy Uninstaller(U1)、BatchUninstall(U2)、Uninstaller(U3)、GoUninstaller(U4)、AppUninstaller CacheCleaner(U5)、UninstallMaster(U6)。然后,我们分别基于应用流行度(例如评分、下载次数)、流量成本以及混合方法对这6个应用程序进行排序。推荐结果如表2所示。
表2. 基于不同推荐标准的应用推荐
| 准则 | 推荐 |
|---|---|
| 流行度 | 易卸载, 卸载工具, 快速卸载, 卸载大师 批量卸载,应用卸载与缓存清理 |
| 流量成本 | 应用卸载与缓存清理,卸载工具,卸载大师, 批量卸载,快速卸载,易卸载 |
| 混合方法 | 卸载工具,应用卸载与缓存清理,卸载大师, 易卸载,快速卸载,批量卸载 |
在表2中,流行度代表基于应用流行度(例如平均评分、下载次数)的移动应用推荐,流量成本代表基于应用程序流量成本(例如流量成本评分)的移动应用推荐,混合方法代表基于我们方法的应用推荐。从这些结果可以看出,基于流行度的方法将易卸载排在首位,而该应用程序在6个应用程序中具有最高的流量成本分数。基于流量成本的方法会将一些不受欢迎的应用程序(例如评分或下载次数较低)排在较高位置,这种推荐结果不能最好地满足用户需求。最后,基于混合方法的推荐将卸载工具排在第一位,该应用程序不仅具有较高的流行度,而且产生较低的流量成本分数。这一结果表明,我们的方法能够在移动应用推荐中实现流行度与流量成本之间的某种平衡。
6 相关工作
在移动应用推荐方面已有一些前期工作,旨在帮助移动用户更明智地选择应用程序。在[15]中,作者提出了一种基于张量分解的针对隐式反馈数据的新型上下文感知协同过滤算法。他们在缺乏用户显式反馈信息的情况下构建偏好模型,并将真实的上下文信息整合到单一推荐模型中。在[16]中,作者提出了AppTrends,该方法在Android操作系统环境中采用基于图的技术进行应用推荐。他们提出了一种新颖的方法,将用户的使用模式表示为一个图,其中节点是用户安装的应用程序,边是两个相连应用程序之间的距离。在[17]中,作者提出了一种基于功能的推荐架构,能够通过分析用户的功能需求提供更准确、更多样化的应用推荐。在[18]中,作者从富含上下文的设备日志中提取个性化的上下文感知偏好,并利用这些识别出的偏好来构建个性化的上下文感知推荐系统。在[19]中,作者提出了一种新颖的框架,该框架将从版本描述中提炼出的特征融入应用推荐中。该框架利用一种半监督的LDA变体,结合文本和元数据,将版本特征表征为一组潜在主题。
7 结论
本文提出了一种融合网络流量成本的应用推荐研究。具体而言,我们首先提出了一种新的推荐方法,以在移动应用的流行度和流量成本之间实现平衡。我们的方法具有可扩展性,并能自动估计移动应用的流量成本,而无需依赖任何预定义流量成本函数。此外,我们从谷歌商店爬取了一个真实世界的数据集,并使用该数据集评估我们的方法。评估结果表明,与先前方法相比,我们的方法实现了性能提升。这表明在移动应用推荐中考虑移动应用的网络流量成本是十分重要的。

















 34
34

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









