



使用激光雷达传感器的多目标检测与跟踪及语义分割
摘要
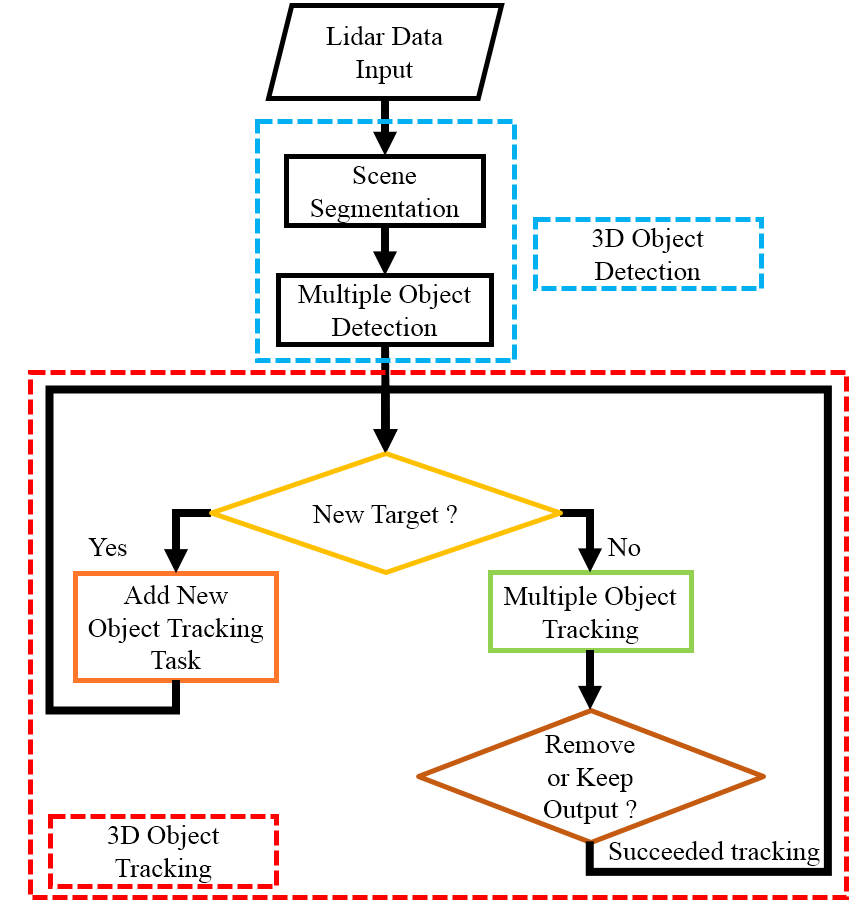
本文利用室外交通场景中激光雷达传感器采集的点云数据,构建了一个3D多目标语义分割、检测与跟踪框架。本文提出利用PointNet++的场景分割结果进行3D多目标检测,以改善点云数据转换到体素空间后提取空间特征时导致的点云数据丢失问题。空间特征和场景分割结果还通过鸟瞰图表示为2D数据,在该视图中交通场景中的物体不会重叠。由于检测系统的处理时间远慢于数据采集时间,因此在每个时间瞬间点云中检测到的目标将通过在预测区域内利用交并比的局部检测方法直接进行跟踪。
I. 引言
在自动驾驶领域,3D多目标检测、跟踪与预测是重要的研究课题。相机和激光雷达都是当前自动驾驶应用中的重要传感器,但激光雷达只能感知来自物体及其局部外观的点云数据。因此,本论文仅使用激光雷达作为输入数据源,实现对车辆的检测或跟踪。
近年来,3D多目标检测出现了不少方法,例如 MV3D[1], Frustum PointNet[2], 和 VoxelNet[3], 等。这些方法大致可分为三类:仅使用2D图像数据、仅使用3D点云数据,以及使用2D和3D混合数据。单独使用2D图像数据难以检测物体在3D空间中的精确位置。使用2D和3D混合数据的方法又可分为两类:分别从2D和3D数据中提取特征然后融合特征,或先进行2D检测再转换到3D空间进行检测。第一类方法相当于进行了两次数据处理,使得整个系统过于庞大;第二类方法仍然受限于2D图像,难以适应环境变化。因此,本文仅使用3D点云数据对室外交通场景中的多个目标进行检测与跟踪。
3D多目标检测通常使用3D卷积来提取空间特征。激光雷达感知的原始点云数据以等间隔形式转换为体素格式数据,可用于卷积神经网络(CNN)的3D卷积操作以提取空间特征。然而,由于激光雷达数据的特点是,空间中分布不均的点云并非等距数据。近程点云较密集,而远程点云较稀疏。近年来的3D多目标检测方法,如VeloFCN[4]和YOLO3D[5],均将3D点云转换到网格空间或体素空间,从而使数据转化为等距形式。这种转换会导致原始点云数据的丢失。因此,如何充分利用每一个点云数据是提高检测精度的重要问题。本文采用无需将点云转换为体素空间的PointNet++[6]架构,以在点云分布不均和数量不一的情况下提取其空间特征。
II. 多目标语义分割、检测与跟踪
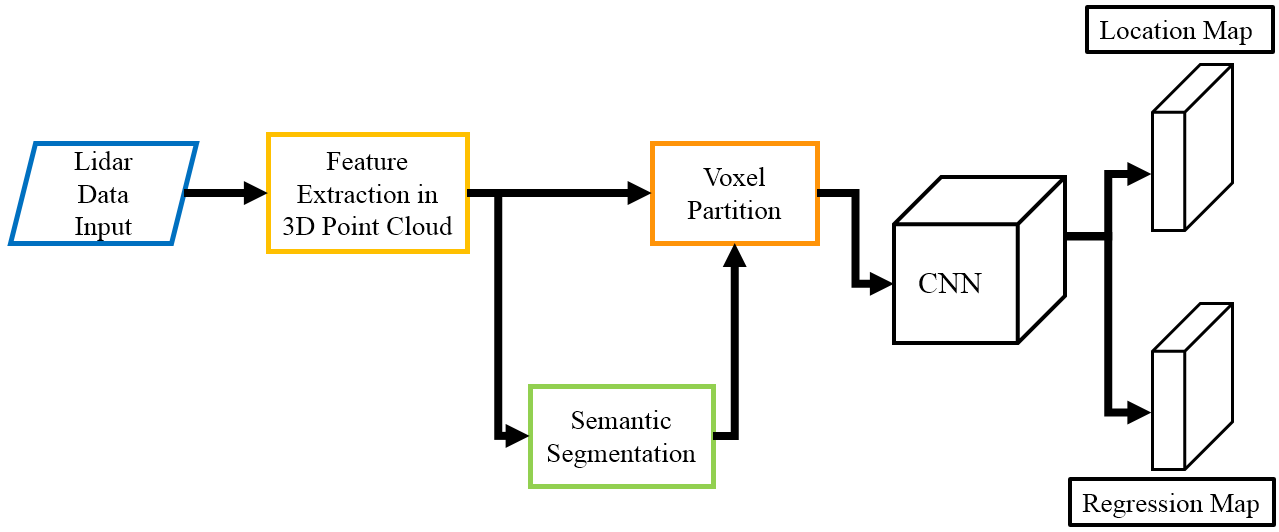

检测系统如图2所示。首先,采用PointNet++[6]的网络架构来提取三维空间特征。然后将三维空间特征回传给每个点云,以执行场景分割并识别每个点云的类别。
在理解场景后,第二部分是整合语义分割的结果,将3D点云数据格式转换为鸟瞰图下的体素空间。随后利用二维卷积神经网络(CNN)来综合空间特征,并估计物体的边界框,如图3所示。
III. 实验结果
实验结果包括性能使用KITTI视觉基准对多目标检测和多目标跟踪进行评估。由于KITTI数据集的测试数据中没有真实标签,我们采用与Mono3D[7]相同的评估方法,将训练数据划分为3712帧训练数据和3769帧验证数据。
首先,我们评估多目标检测的性能。KITTI数据集的评估将检测难度分为简单、中等和困难三类。车辆目标的AP(平均精度)是在检测结果与真实标签之间的IOU(交并比)为0.5的情况下计算的。表1展示了我们的方法与其他方法在性能评估上的对比。Mono3D[7]和3DOP[8]使用KITTI数据集中的2D图像数据进行车辆检测,而VeloFCN[4]还利用了KITTI数据集中的激光雷达数据。可以看出,我们的方法在三维多车辆目标检测中表现优于其他方法。
然后,表2给出了多目标跟踪的评估结果。我们的跟踪结果与使用IOU匹配准则或匈牙利算法的多目标跟踪器进行了比较。尽管它们的跟踪性能优于我们的方法,但这两种方法都依赖于多目标检测结果。由于激光雷达数据的3D多目标检测速度较慢,这两种跟踪方法无法在线实现实时性能。
表1. 3D车辆检测的AP评估。(IOU=0.5)
| 方法 | 数据 | 简单 | 中等 | 困难 |
|---|---|---|---|---|
| Mono3D | Mono | 25.19 | 18.2 | 15.52 |
| 3DOP | 立体 | 46.04 | 34.63 | 30.09 |
| VeloFCN | 激光雷达 | 67.92 | 57.65 | 52.56 |
| Our | 激光雷达 | 76.404 | 69.179 | 63.643 |
表2. 多目标跟踪评估。
| Method | MOTA | MOTP | MT | PT | ML |
|---|---|---|---|---|---|
| IOU | 44.255 | 71.403 | 42.476 | 37.524 | 20.0 |
| 匈牙利 | 44.210 | 71.403 | 28.191 | 48.952 | 20.0 |
| Our | 31.35 | 70.192 | — | — | 22.857 |


















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









