






一、实验目的
- 掌握Hadoop伪分布式环境的搭建与配置
- 熟悉HDFS的基本操作
- 通过Java编程实践实现HDFS功能
- 理解Hadoop核心配置文件作用
- 培养问题分析与解决能力
二、实验环境
- 操作系统:CentOS 6
- JDK版本:1.7 (安装路径/usr/java/jdk1.7.0_67)
- Hadoop版本:2.6.5 (路径/opt/20223560)
- 开发工具:Eclipse Mars + Hadoop插件
- 辅助工具:Xftp/Xshell
三、实验内容
任务1:Linux虚拟机安装
-
BIOS设置
初始选择CentOS 8导致内核恐慌,后改用CentOS 6
- 网络配置
vi /etc/sysconfig/network-scripts/ifcfg-eth0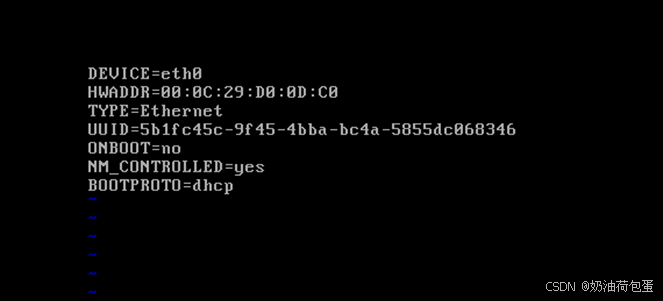
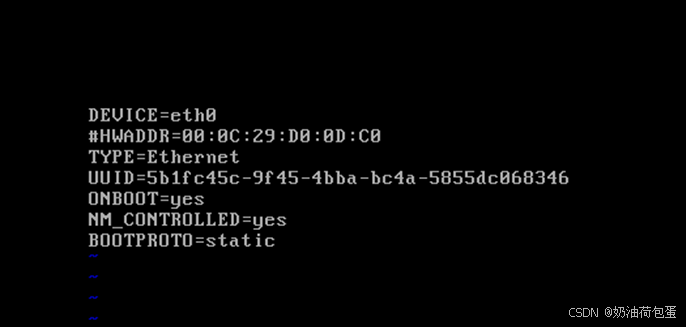
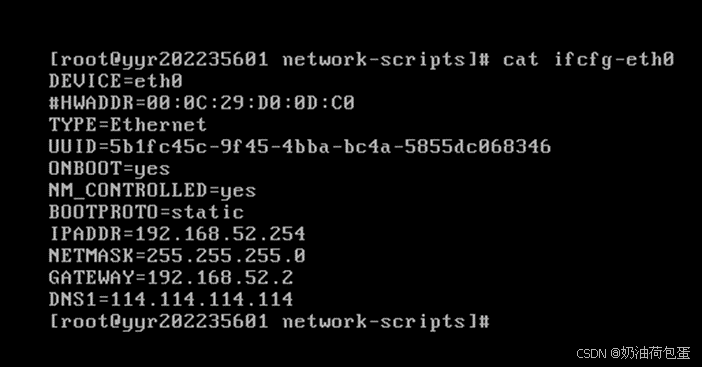
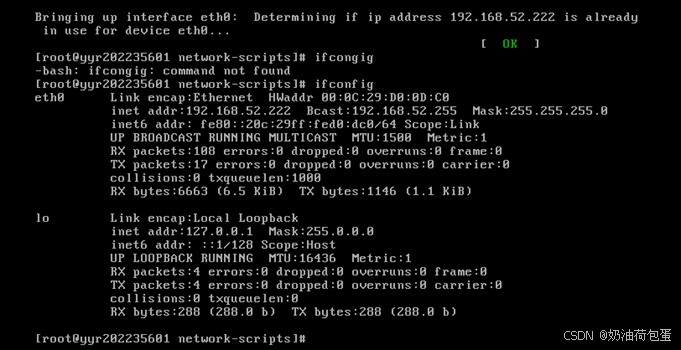
- 修改IP地址为静态分配
- 关闭防火墙
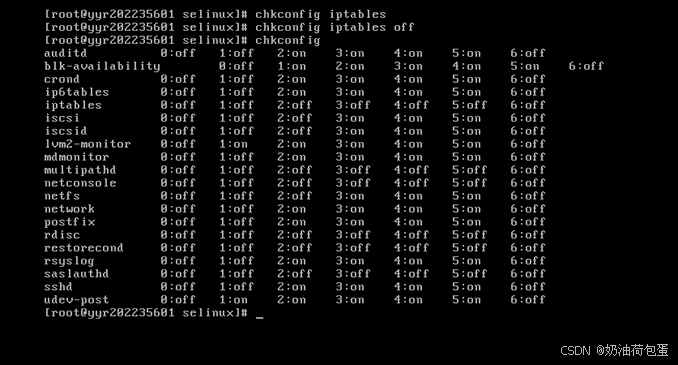
- 关闭防火墙
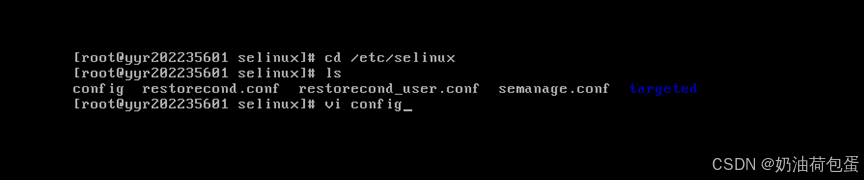
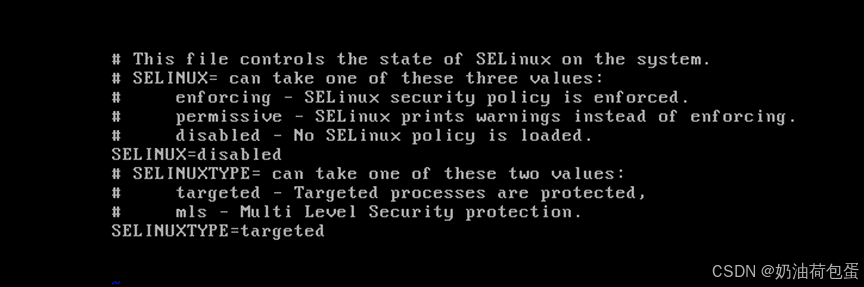
- 关闭selinux
vi /etc/selinux/config 修改配置项:SELINUX=disabled

删除/etc/udev/rules.d/70-persistent-net.rules
rm -f /etc/udev/rules.d/70-persistent-net.rules

将虚拟机重启,之后拍摄快照,克隆虚拟机

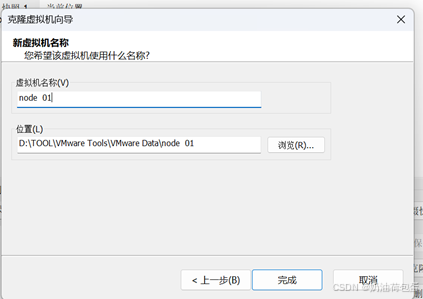
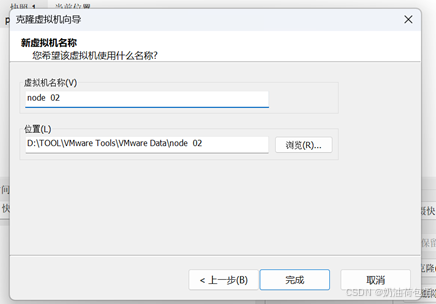
再此快照下进行克隆,我克隆了四台虚拟机,分别命名为 node1、node2、node3、node4.
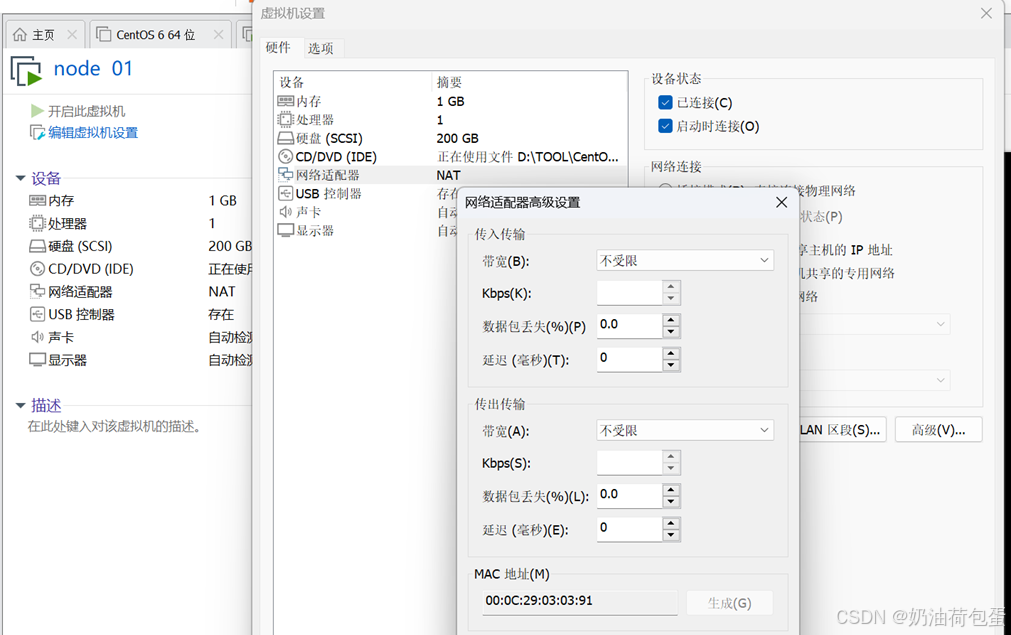
观察五台虚拟机的MAC地址并不相同
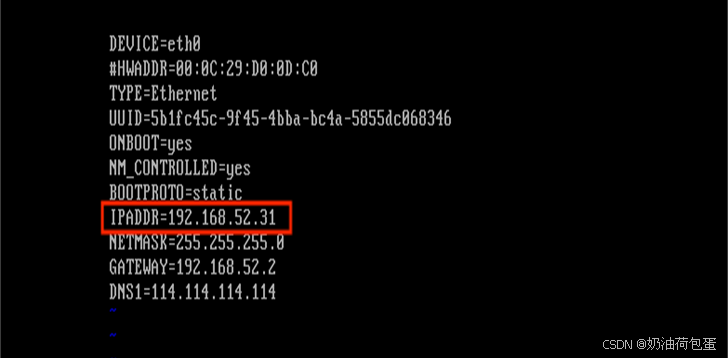
配置克隆虚拟机的IP vi/etc/sysconfig/network-scripts/ifcfg-eth0

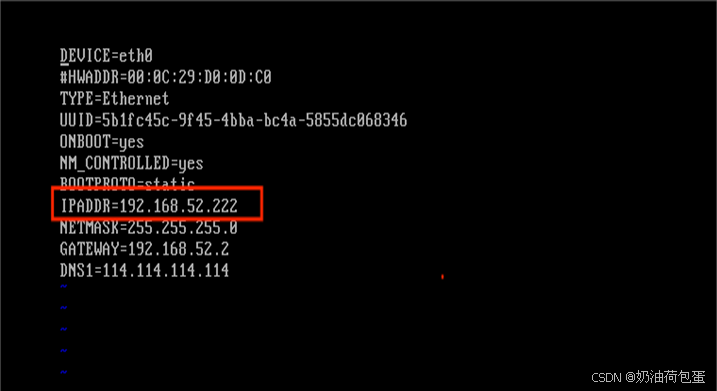
可以看到该文件中的IP地址为主虚拟机的IP地址,修改为192.168.52.31
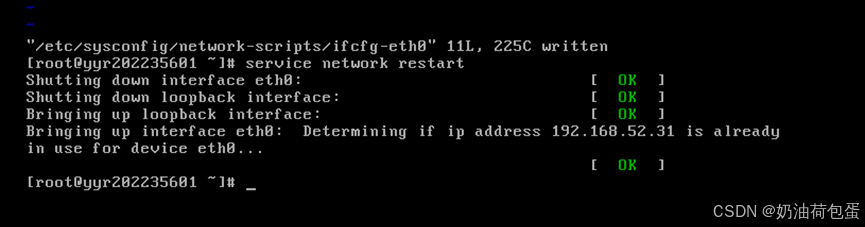
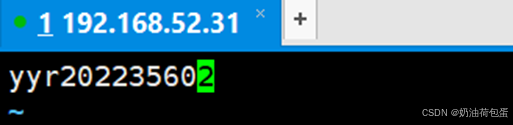
配置主机名(/etc/sysconfig/network)
将主机名改为yyr202235602 其中yyr是我名字缩写,20223560是学号,2为序号

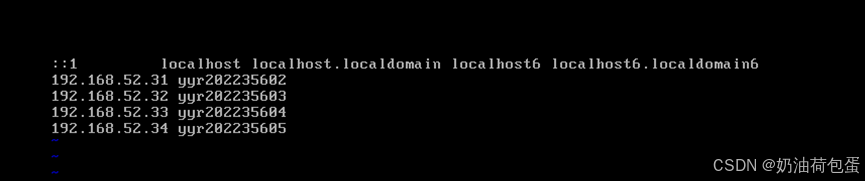
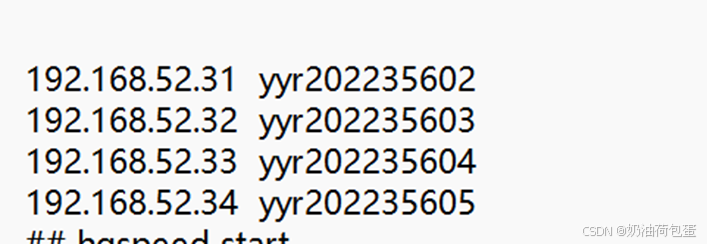
配置映射(/etc/hosts)
可以看到四个克隆出的虚拟机配置的IP和主机名
输入power off之后拍快照
打开node 01 可以看到用户名已经发生改变
配置克隆的第二台虚拟机,运行node 02,重复node 01虚拟机的配置过程,此处不再阐述
- 网络验证
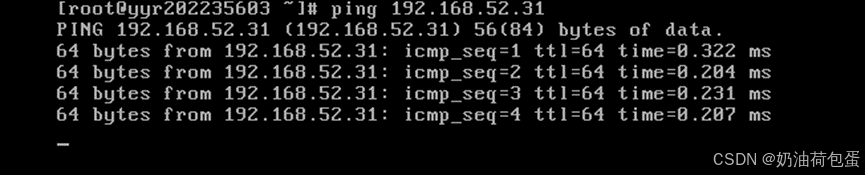
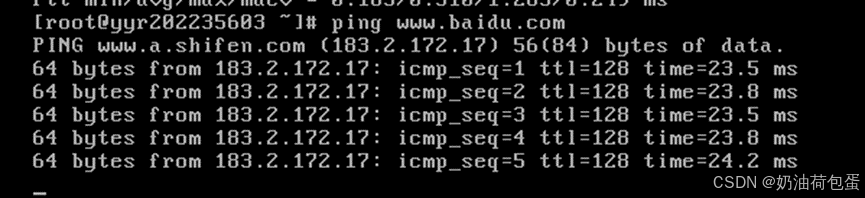
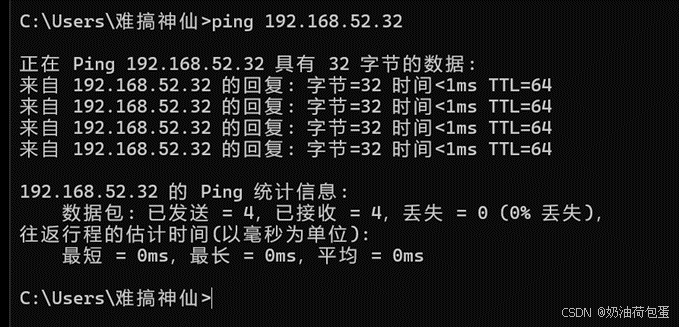
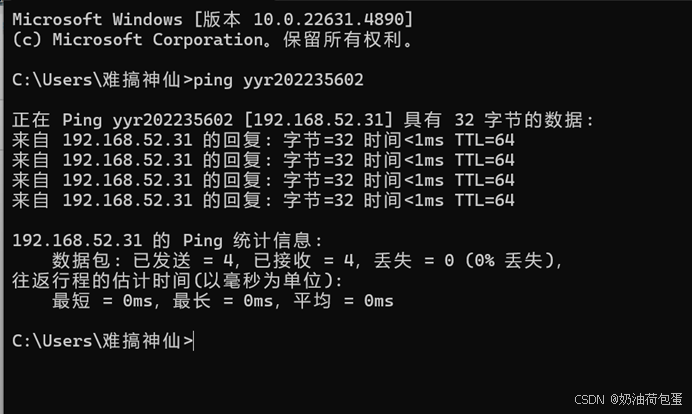
打开第二台克隆的主机 node 02,验证ping 192.168.52.31(IP地址),ping yyr202235602(主机名)以及外部网站

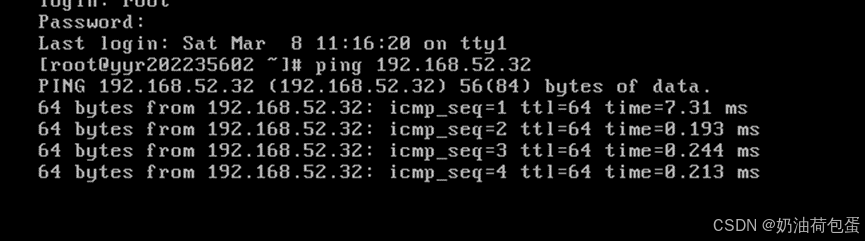
打开node 01
验证ping 192.168.52.32(IP地址),ping yyr202235603(主机名)以及外部网络
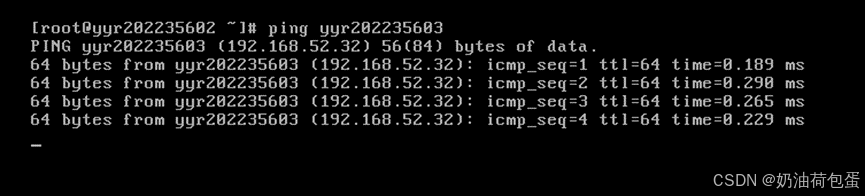

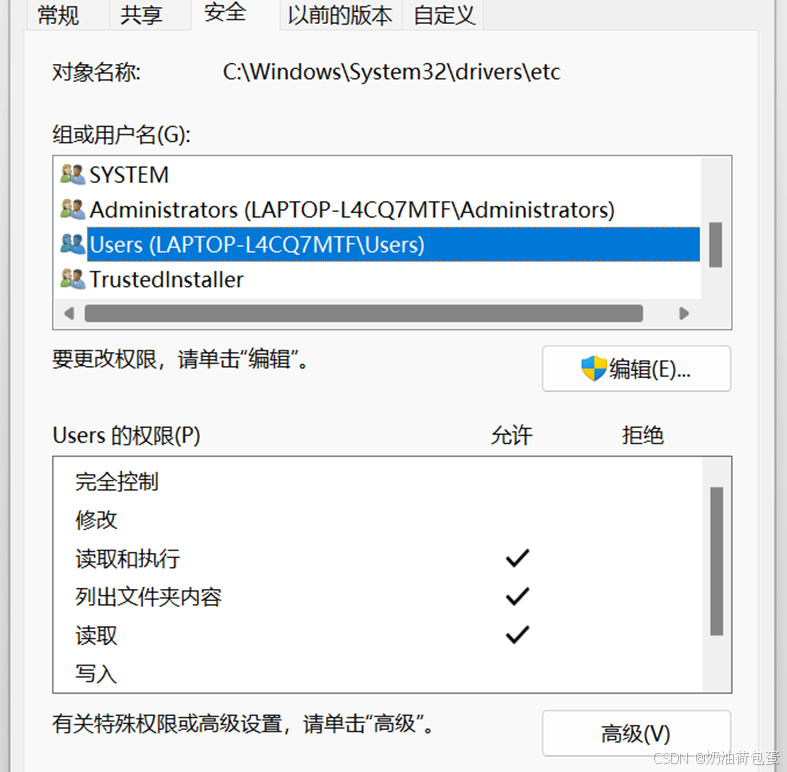
编辑 C:\WINDOWS\System32\drivers\etc\hosts //windows应用程序也可以访问主机名
保存时,发现没有权限修改,再进行权限编辑
任务2:Hadoop伪分布式搭建
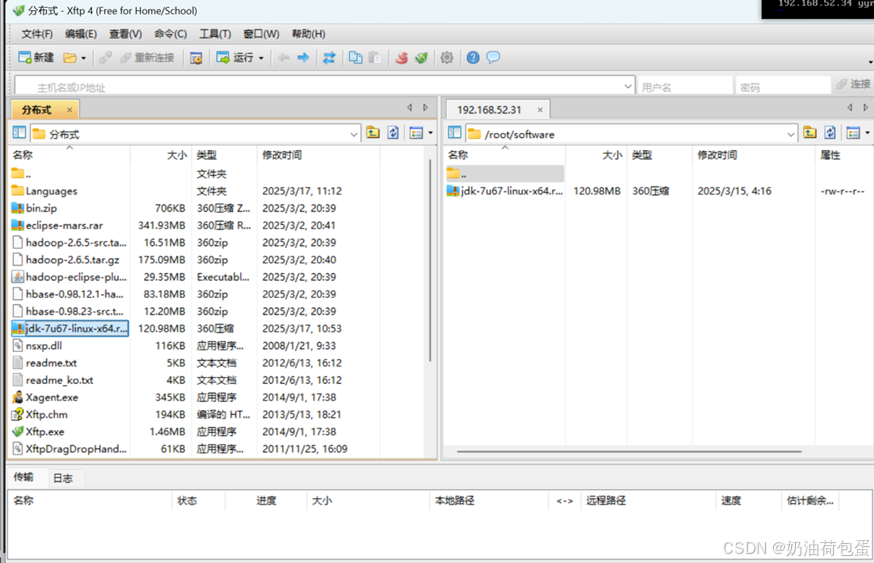
(1)打开Xffp软件,传输安装文件到/root/software/

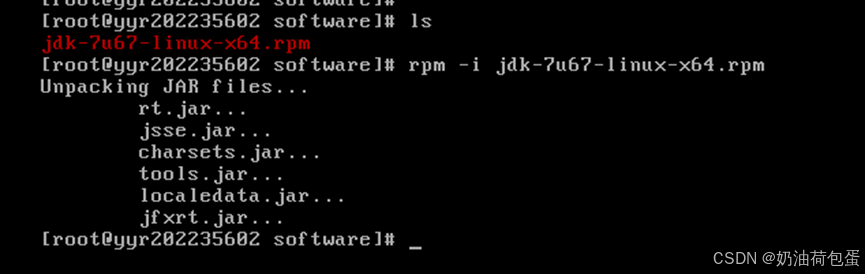
解压 rpm -i jdk-7u67-linux-x64.rpm

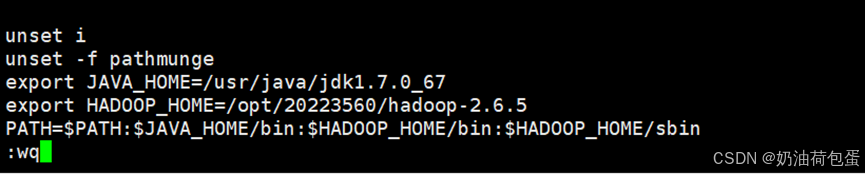
(2)配置环境变量
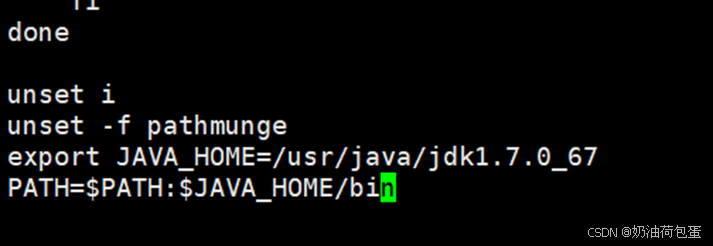
打开/etc/profile文件,配置如下:
export JAVA_HOME=/usr/java/jdk1.7.0_67
PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin


(3)设置ssh免密钥登录
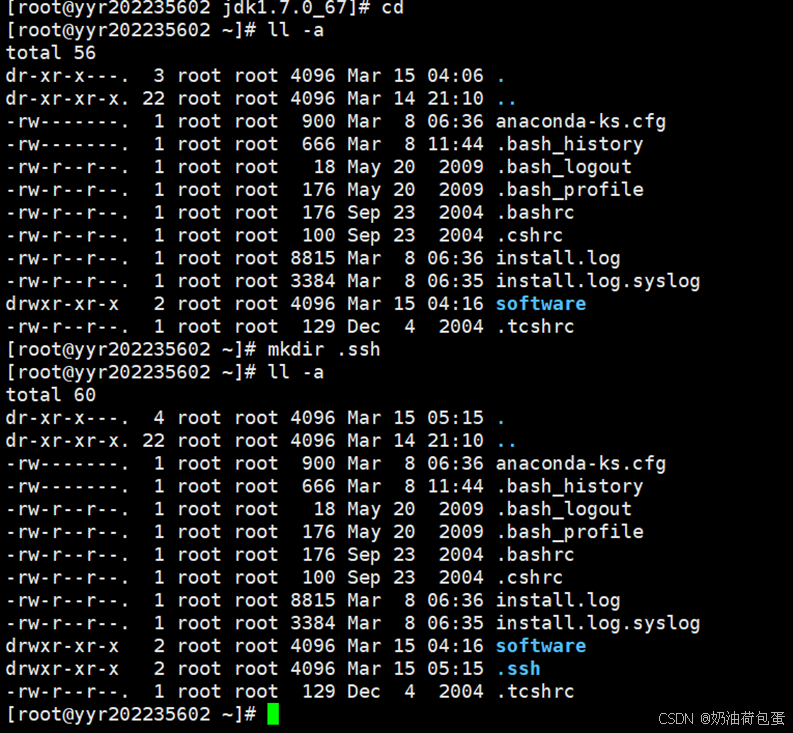
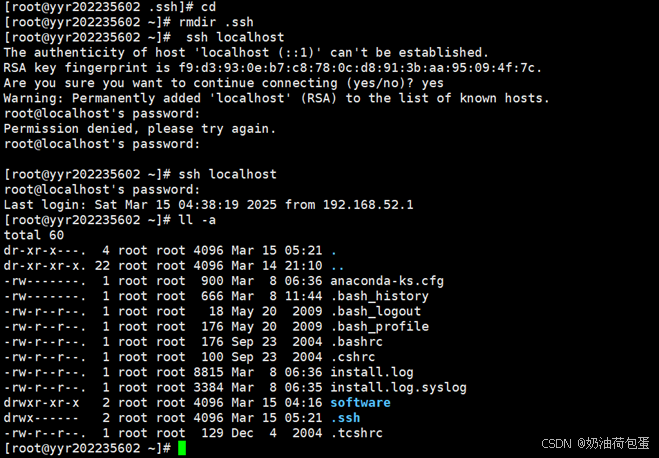
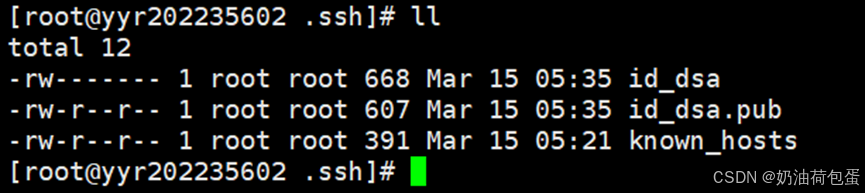
3.1 查看目录,发现没有.ssh目录,之后我采用了一个错误做法,创建.ssh目录,正确做法是登录localhost自动产生
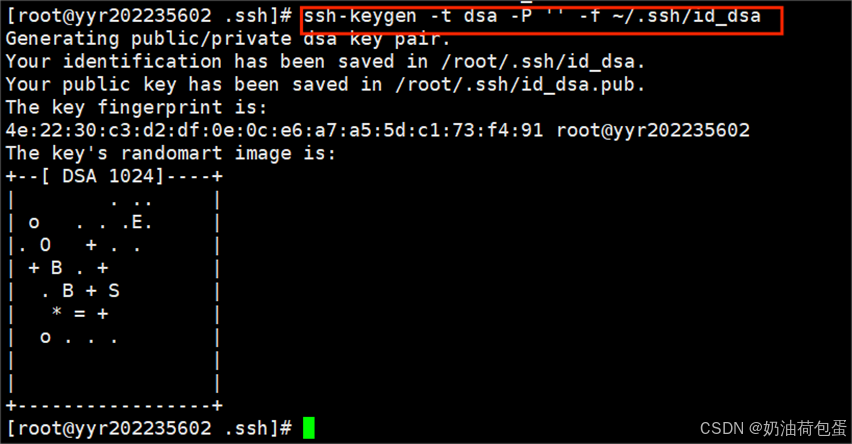
3.2 输入 ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa 生成SSH密钥
3.3 输入 cat id_dsa.pub >> authorized_keys 将id_dsa.pub公钥文件追加到验证文件authorized_keys
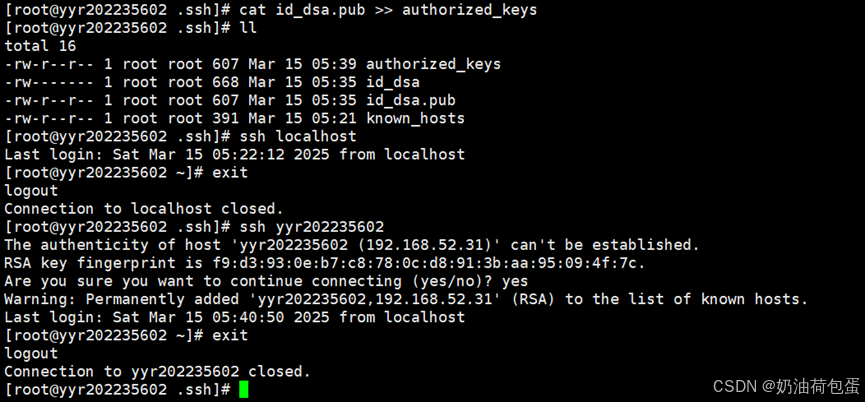
(4)安装Hadoop
4.1 用 Xftp软件传输Hadoop安装文件到/root/software
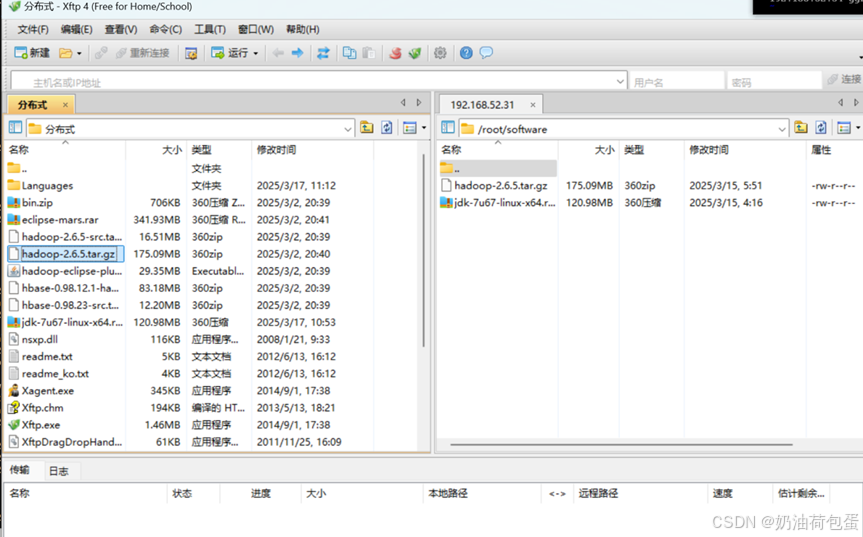

4.2 建立解压目的目录 mkdir -p /opt/20223560
4.3 解压文件 tar xf hadoop-2.6.5.tar.gz -C /opt/20223560/

4.4 配置环境变量 //sbin目录存放系统级别脚本,bin目录存放一般命令

(5)修改配置文件
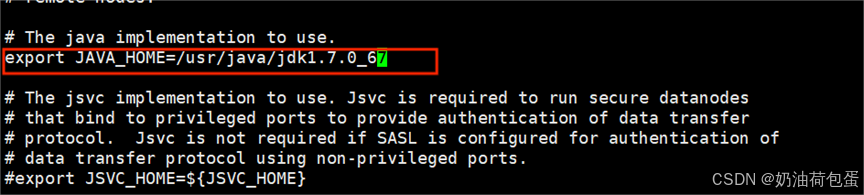
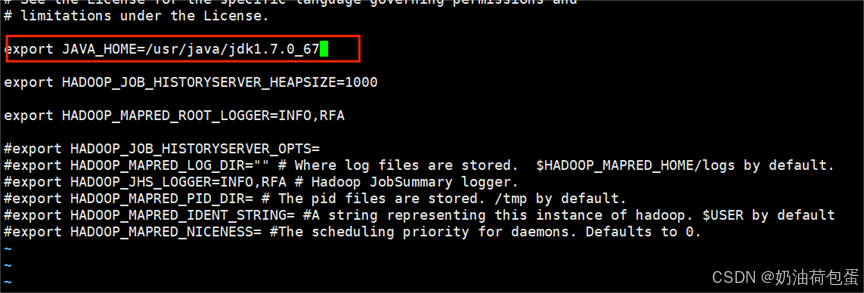
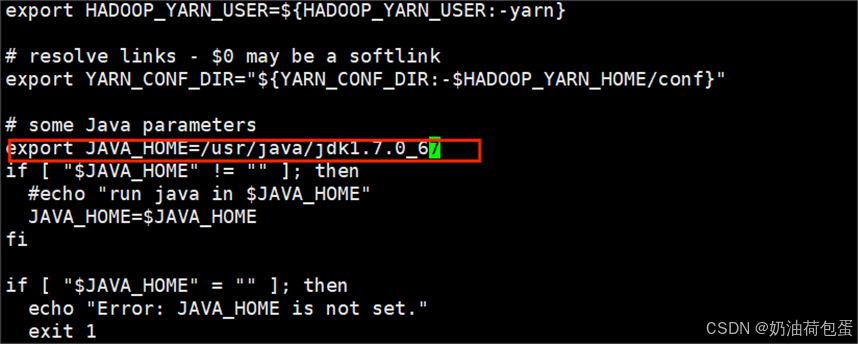
5.1 修改hadoop-env.sh,mapred-env.sh,yarn-env.sh
修改内容为export JAVA_HOME=/usr/java/jdk1.7.0_67



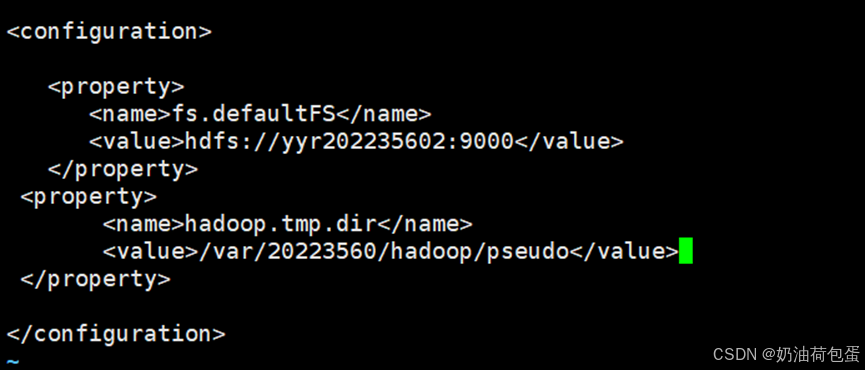
5.2修改core-site.xml

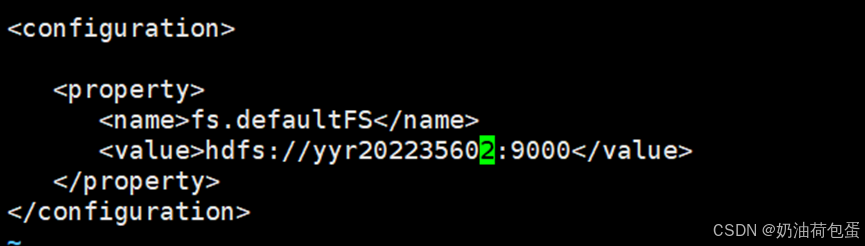
5.3修改hdfs-site.xml

5.4 slaves 节点信息

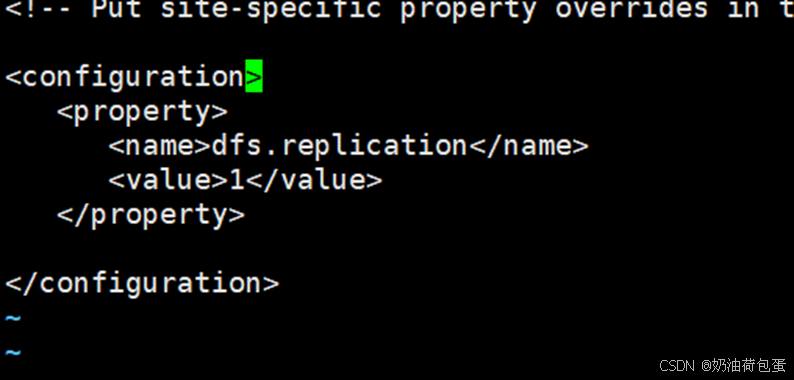
5.5修改hdfs-site.xml

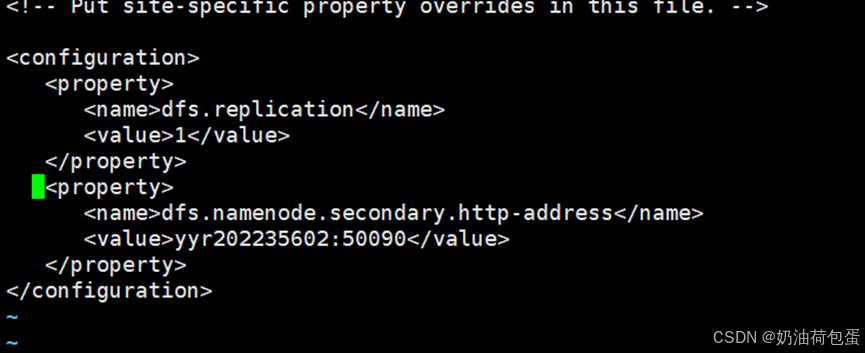 5.6 修改core-site.xml
5.6 修改core-site.xml
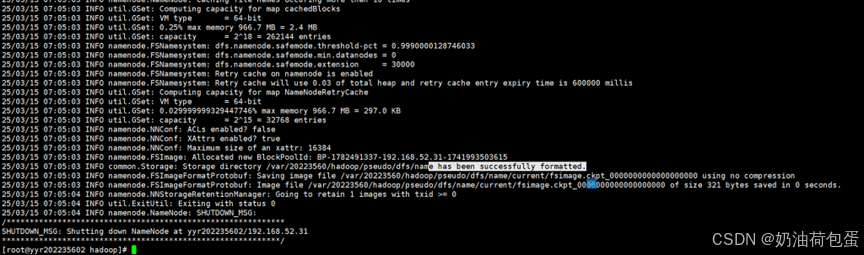
(6) 格式化
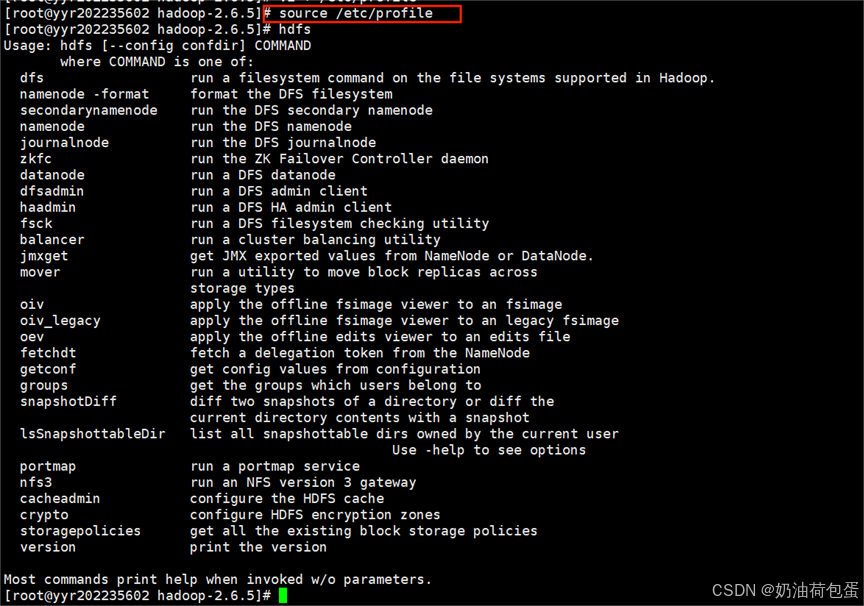
hdfs namenode -format
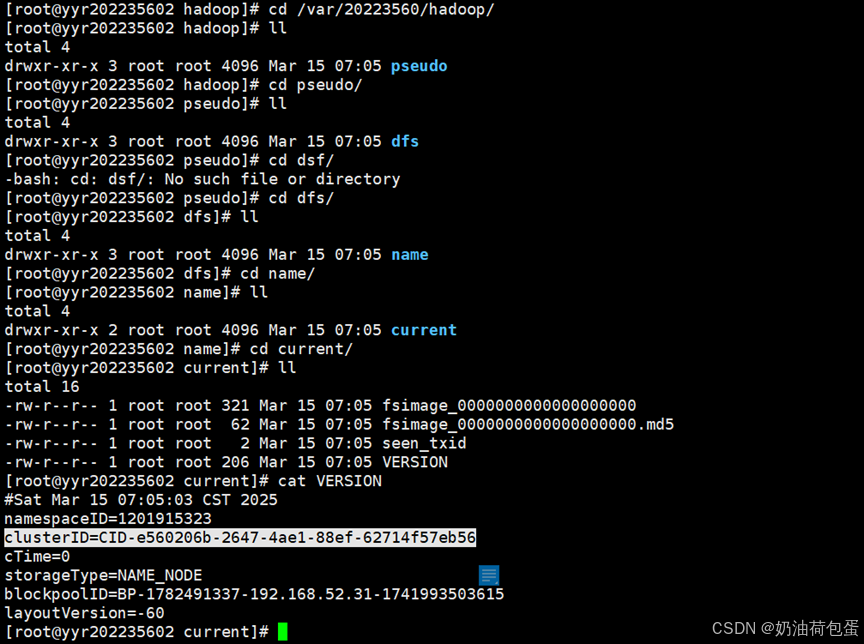
查看current
cat VERSION clusterID(集群ID)查看集群ID
任务3:HDFS Shell操作
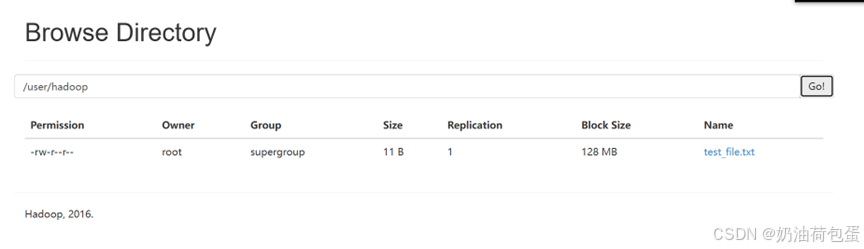
(1)向hdfs上传文本文件
创建本地文本文件 echo “Hello HDFS” > test_file.txt
上传到HDFS的/user/hadoop/目录 hdfs dfs -put test_file.txt /user/hadoop/
创建目录 hdfs dfs -mkdir -p /user/hadoop/

验证是否成功

(2)从hdfs下载文件
下载到当前本地目录
hdfs dfs -get /user/hadoop/test_file.txt ./downloaded_file.txt

ls -l downloaded_file.txt 检查本地文件是否存在

(3)将hdfs指定文件的内容输出到终端
hdfs dfs -cat /user/hadoop/test_file.txt

(4)显示指定文件的详细信息
hdfs dfs -ls -h /user/hadoop/test_file.txt

(5)提供一个hdfs文件的路径,对该文件进行创建和删除操作
创建空文件 hdfs dfs -touchz /user/hadoop/empty_file.txt

删除文件:
hdfs dfs -rm /user/hadoop/empty_file.txt

验证删除:
hdfs dfs -ls /user/hadoop/empty_file.txt # 应提示文件不存在

(6)将hdfs文件从源路径移动到目的路径
hdfs dfs -mv /user/hadoop/test_file.txt /user/hadoop/backup/ 移动到backup目录

hdfs dfs -ls /user/hadoop/backup/test_file.txt 验证

(7) 创建一个约1.6M大小的文件(文件内容为10万行的 hello jsxy), 然后设置块大小(1048576)上传文件
for i in {1…100000}; do echo “hello jsxy”; done > bigfile.txt

验证文件大小 ls -lh bigfile.txt

在已有10万行基础上追加更多行 for i in {1…50000}; do echo “hello jsxy”; done >> bigfile.txt

设置块大小上传到HDFS:hdfs dfs -D dfs.blocksize=1048576 -put bigfile.txt /user/hadoop/

验证块大小:hdfs fsck /user/hadoop/bigfile.txt -files -blocks
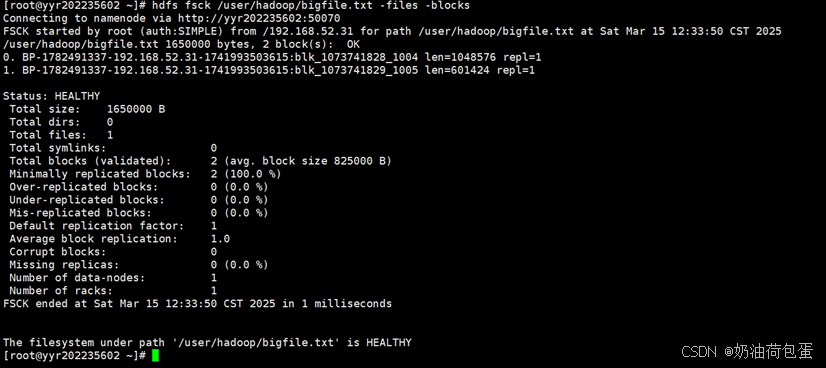
任务4:HDFS编程实践
(1)配置eclipse编程环境
① Hadoop已集群启动

② api客户端设置
2.1 解压hadoop-2.6.5.tar.gz ,hadoop-2.6.5-src.tar.gz 两个压缩文件到D:\hadoop\usr
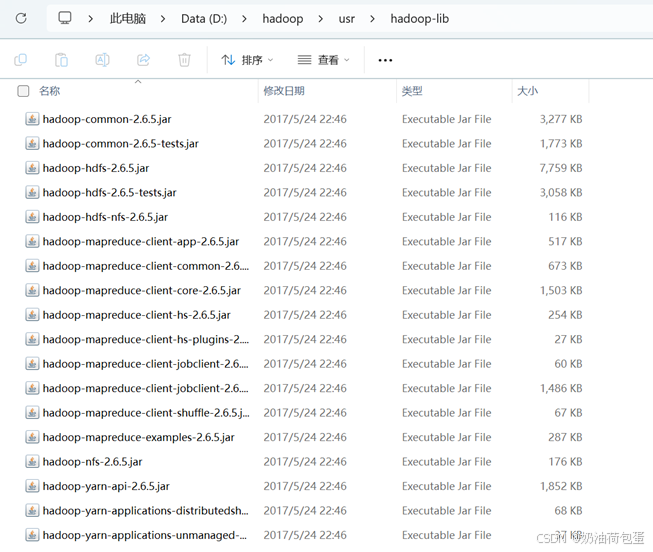
2.2 再创建hadoop-lib目录,将hadoop-2.6.5/share/hadoop各个目录里的jar包拷贝至这里(httpfs,kms除外)
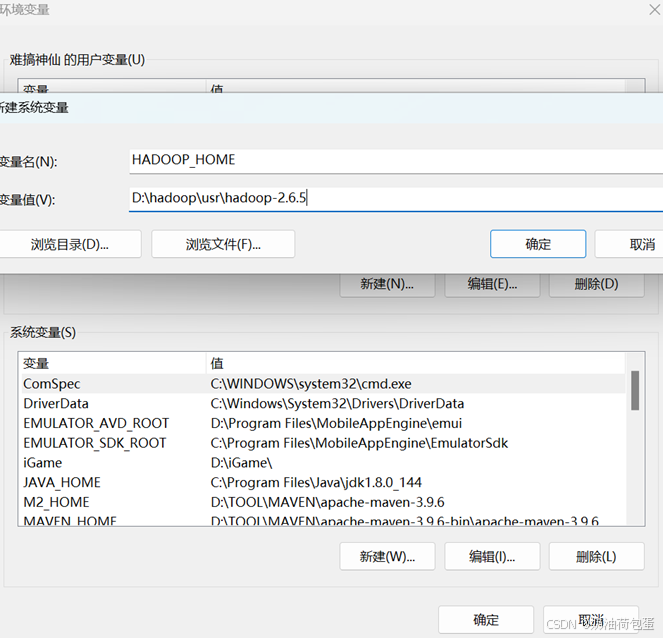
2.3 配置windows环境变量 :
配置 HADOOP_HOME 变量
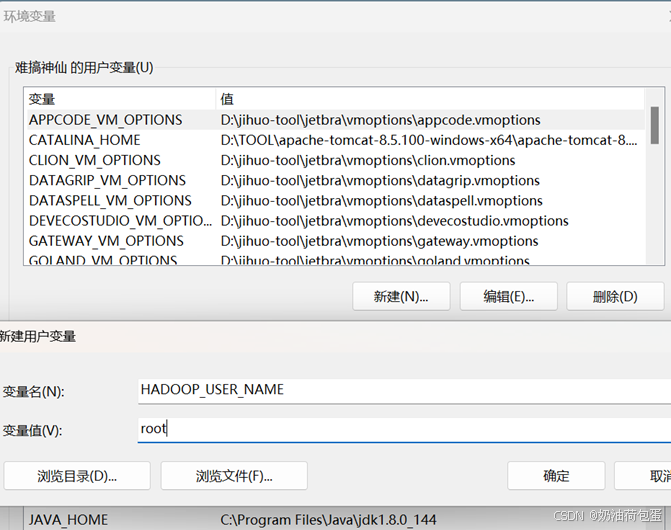
2.4 配置 HADOOP_USER_NAME 变量
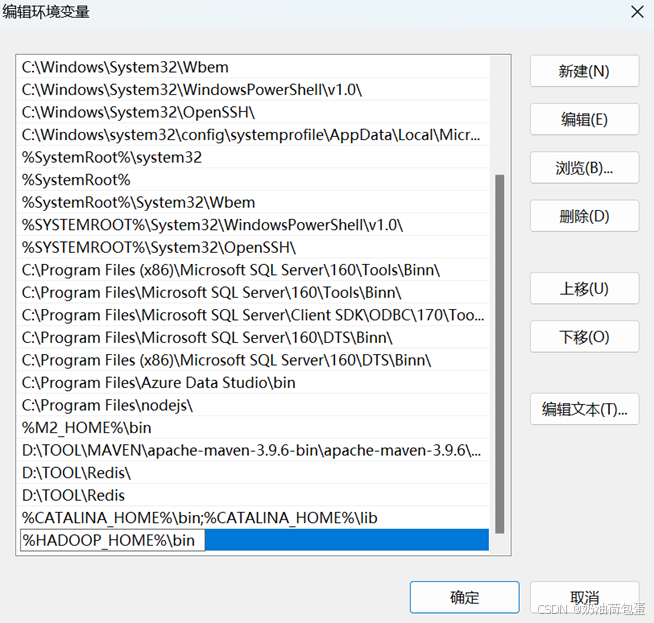
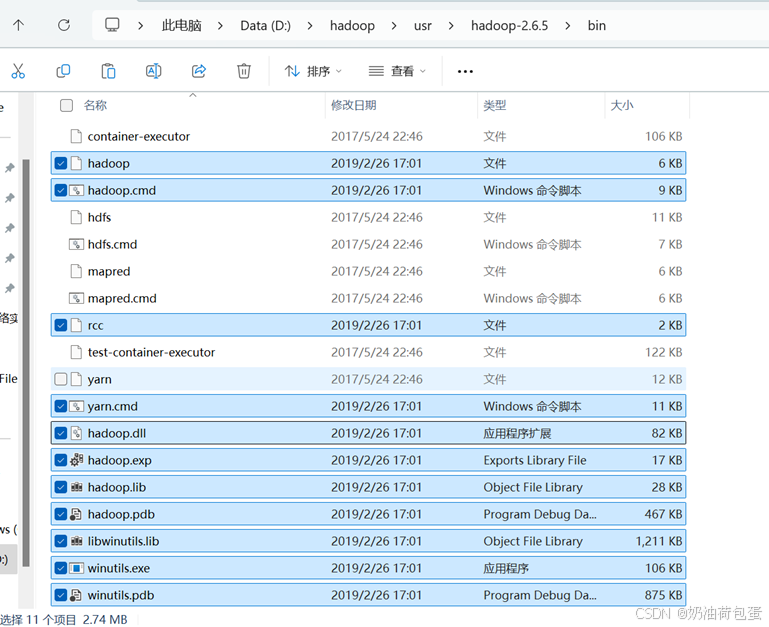
2.5 将老师提供的bin目录的文件复制到d:\hadoop\usr\hadoop-2.6.5\bin
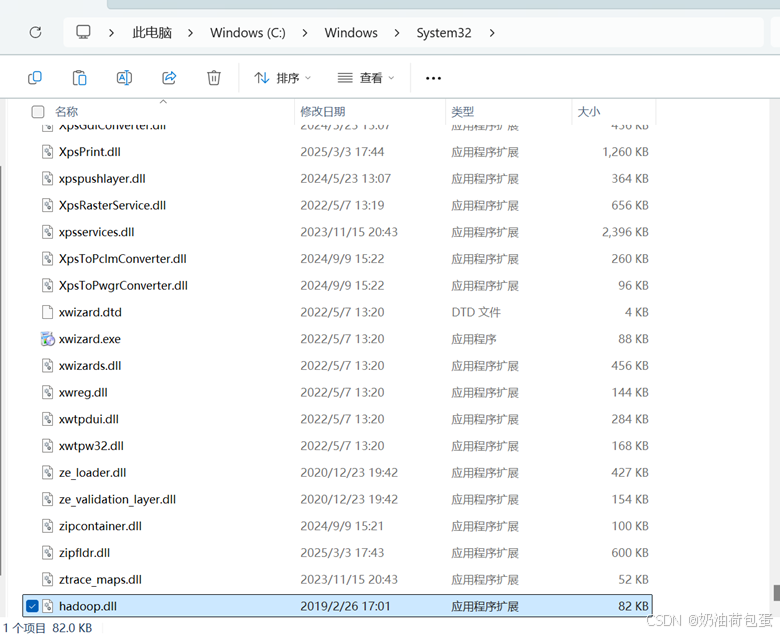
2.6 将bin里的hadoop.dll拷贝到c:\windows\System32
2.7 解压 eclipse-mars.rar,将hadoop-eclipse-plugin-2.6.0.jar(可视化插件)拷贝到d:\eclipse-mars\mars\plugins
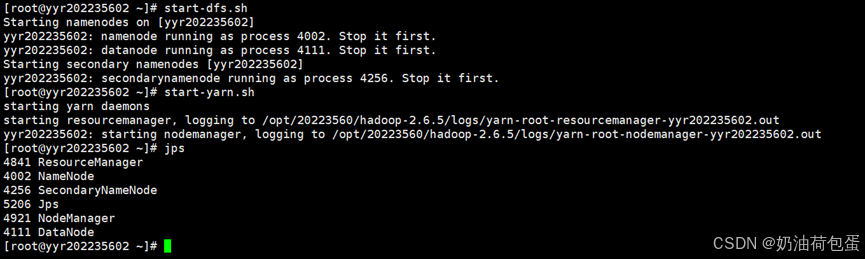
2.8 启动hadoop
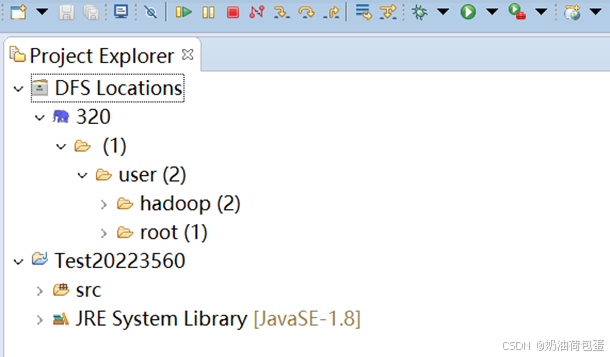
2.9 启动eclipse,project Explorer里有DFS Locations
③配置eclipse:
3.1 点击Window-preferences-Hadoop Map/Reduce
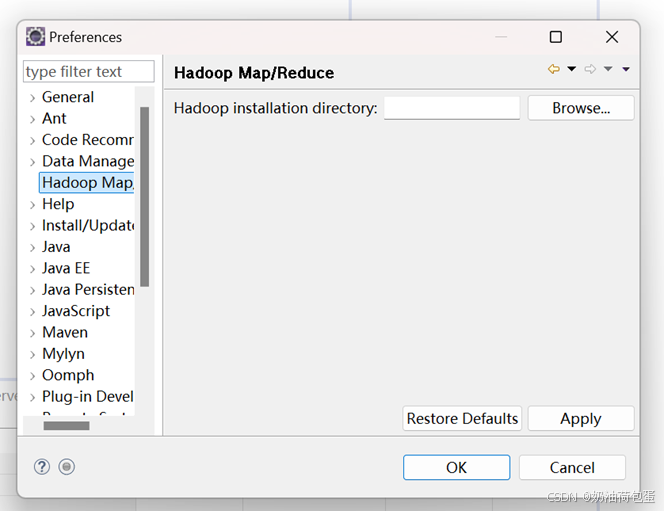
Hadoop installation directory:D:\hadoop\usr\hadoop-2.6.5
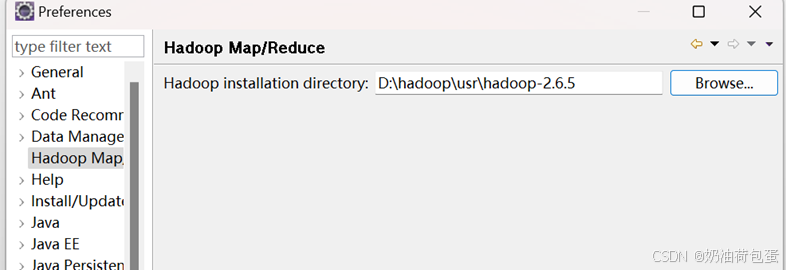
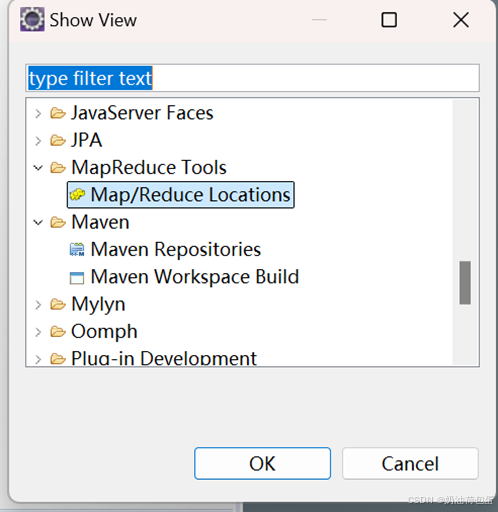
3.2 在 Show View中点击Map/Reduce Locations
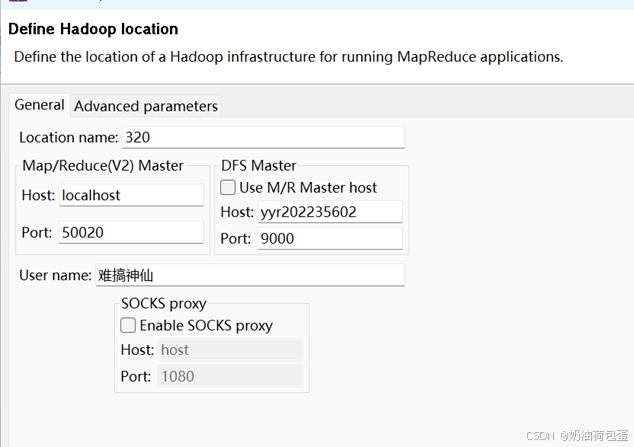
设置如下:
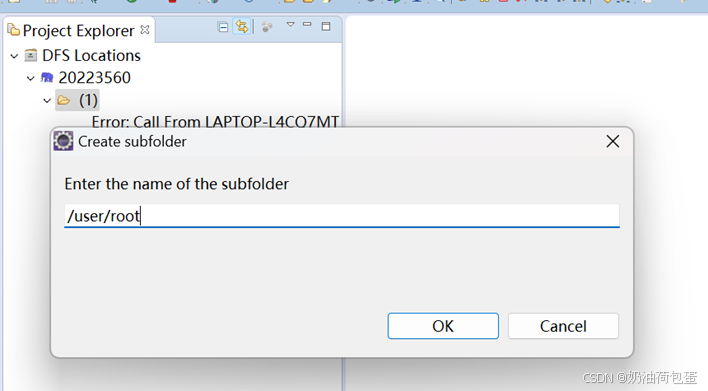
3.3 创建一个目录/user/root
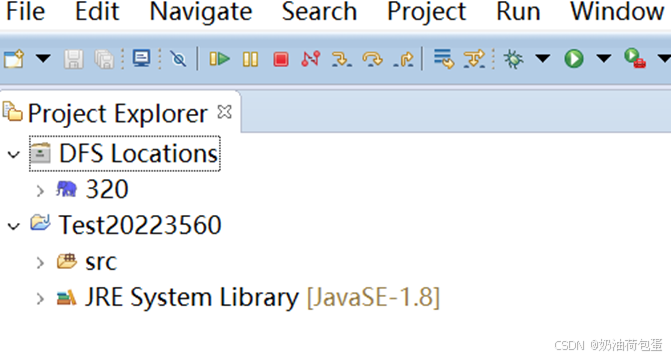
3.4 新建一个Java项目
3.5 导入Jar包:
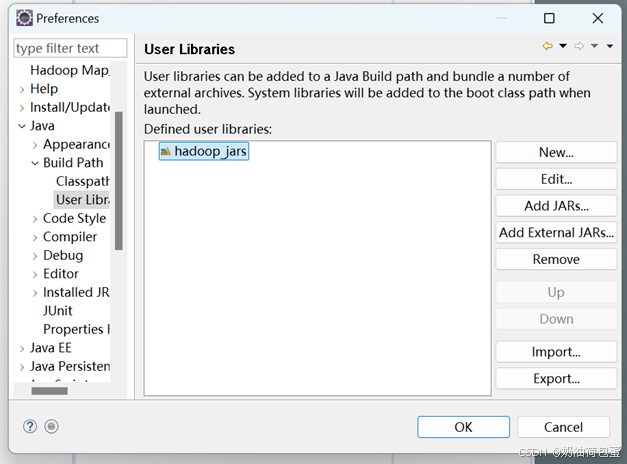
点击 window-preferences-java-build path-user libraries
自定义一个jar包:hadoop_jars
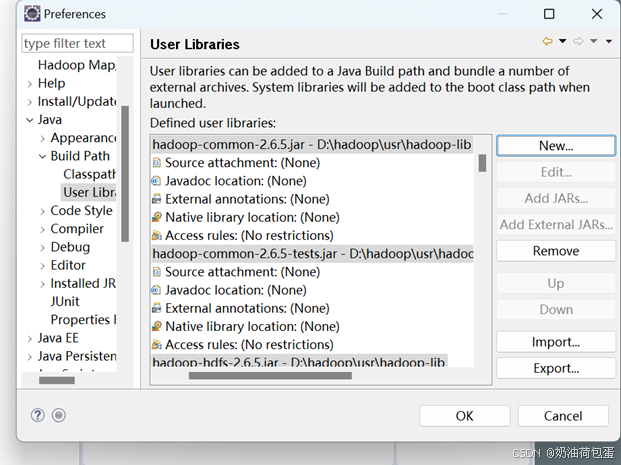
在菜单中点击 add external JARS
选择D:\hadoop\usr\hadoop-lib所有jar包
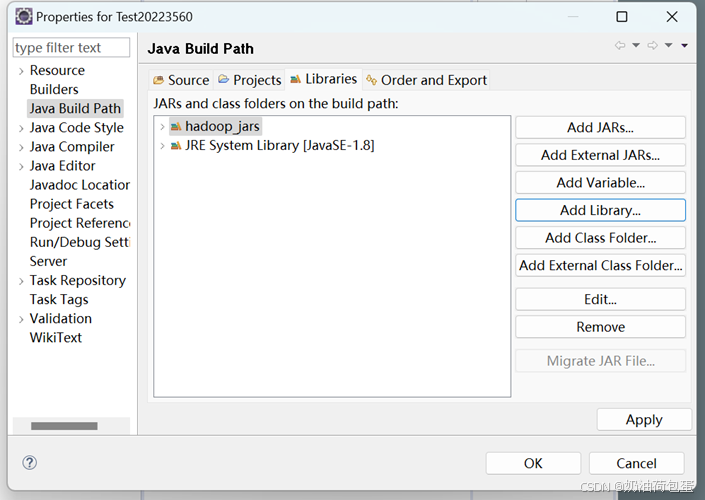
项目里导入hadoop_jars包 右击项目名-build path-configure build path-java build path-libraries-add library-use library-hadoop_jars
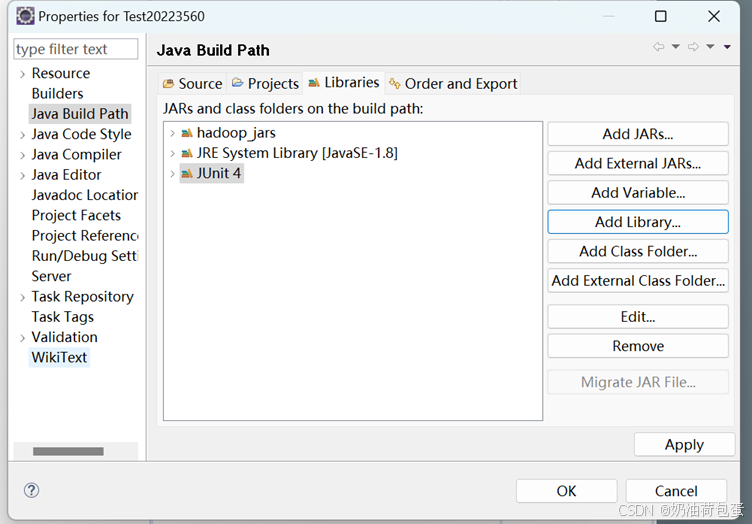
项目里导入jUnit 4 右击项目名-build path-configure build path-java build path-libraries-add library-jUnit 4
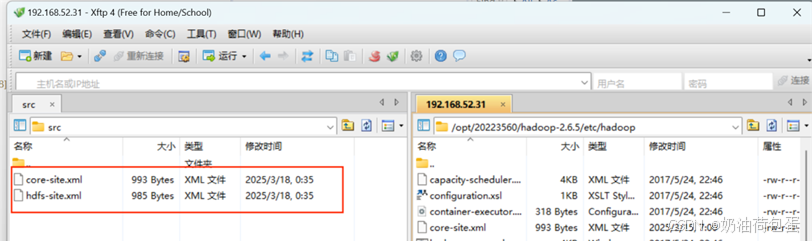
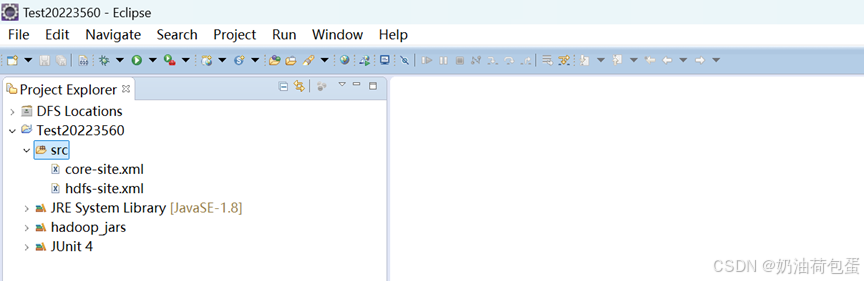
3.6 导入hdfs-site.xml,core-site.xml配置文件到项目的src目录,使用xftp传输
3.7 新建一个class
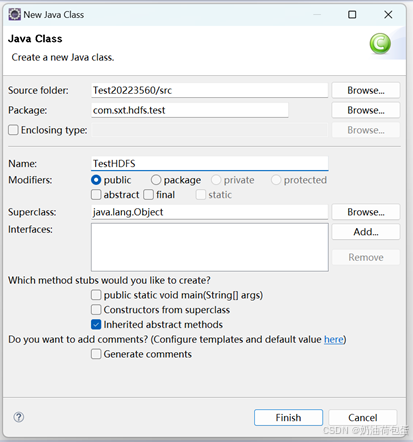
(2)编程实现创建目录、上传文件、显示文件块信息、读取文件部分内容等功能
使用mkdir程序创建目录

使用uploadFile程序上传文件

在远端上传root/test.txt hdfs dfs -D dfs.blocksize=1048576 -put test.txt
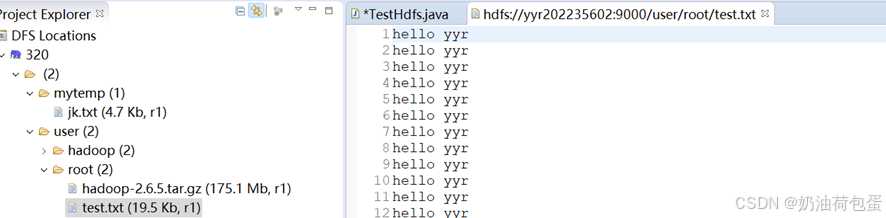

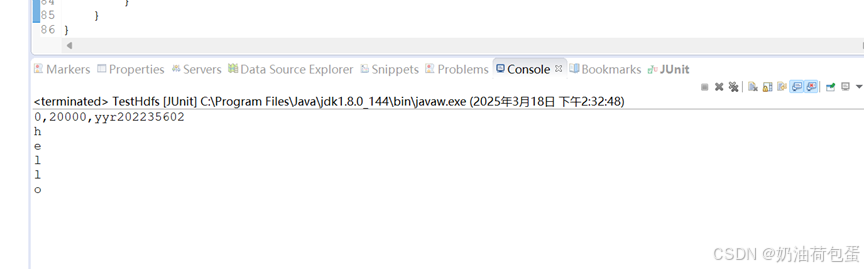
使用readFile程序获取节点信息
四、出现的问题及解决方案
1.CentOS版本选择错误,在本次实验中最先选择CentOS 8版本,配置打开后产生内核恐慌,后重新配置选择CentOS 6版本
2.端口号以及名称设置错误,不断提示错误导致软件卡死,后来重新定义。
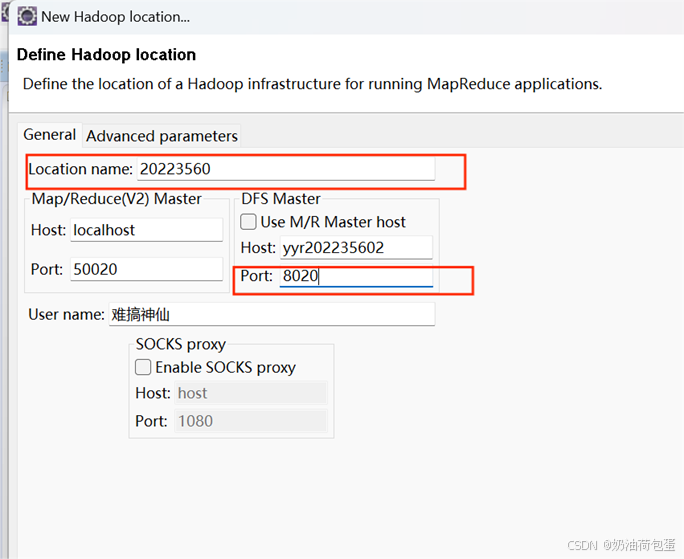
3.java代码运行阶段产生这类错误,原因是jar包覆盖时,没有完全拷贝过来,后重新完全拷贝过来。
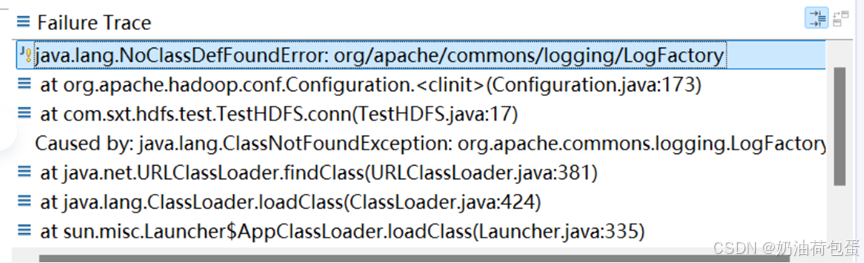
五、实验结果
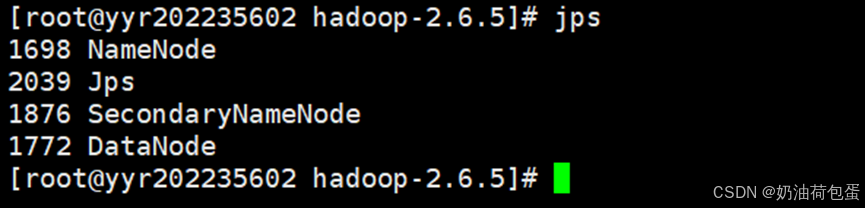
(1)启动集群 start-dfs.sh
jps 查看启动哪些进程

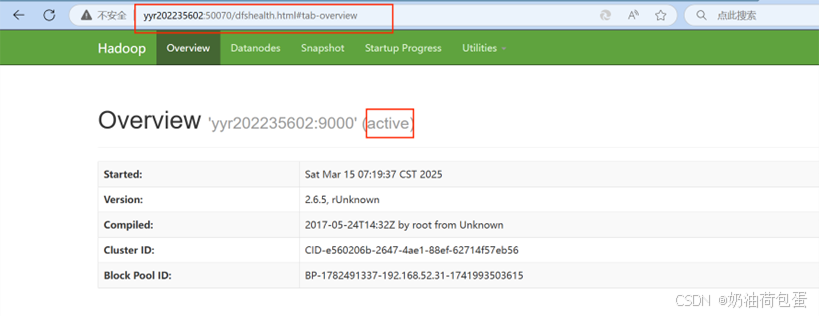
(2)通过浏览器查看信息
ss -nal 查看通讯端口

在浏览器输入yyr202235602:50070,前提是要在windows下的c:/windows/system32/drivers/etc/hosts文件添加IP节点映射
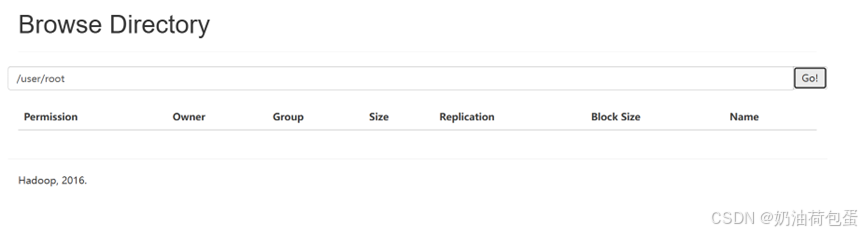
(3)上传文件
创建路径
hdfs dfs -mkdir -p /user/root

hdfs dfs -ls /

此时浏览器中目录显示为空
cd ~/software
ls -lh ./ 查看文件大小
上传文件 hdfs dfs -put hadoop-2.6.5.tar.gz /user/root

在浏览器查看
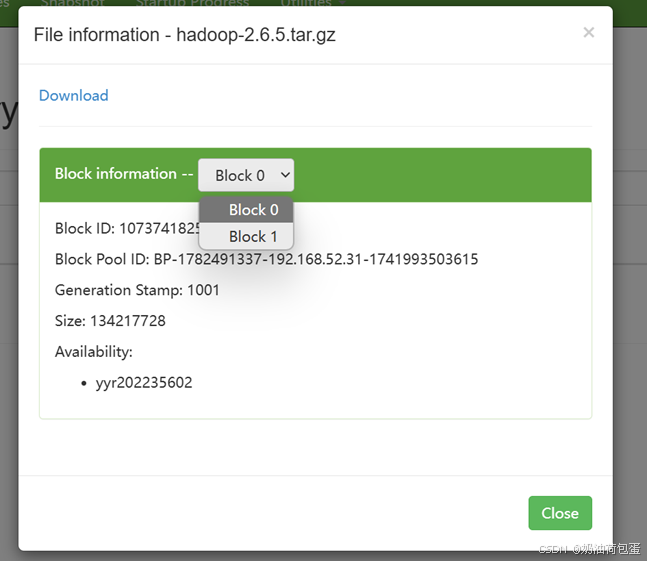
该文件生成两个块,块大小默认128MB
package com.sxt.hdfs.test;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.junit.*;
public class TestHdfs {
private Configuration conf = null;
private FileSystem fs = null;
@Before
public void conn() throws IOException {
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://yyr202235602:9000");
fs = FileSystem.get(conf);
}
@Test
public void mkdir() throws IOException {
Path path = new Path("/mytemp");
if (fs.exists(path)) {
fs.delete(path, true);
}
fs.mkdirs(path);
}
@Test
public void uploadFile() throws IOException {
Path path = new Path("/mytemp/jk.txt");
try (FSDataOutputStream fdos = fs.create(path);
InputStream is = new BufferedInputStream(new FileInputStream("D:\\hadoop.txt"))) {
IOUtils.copyBytes(is, fdos, conf, true);
}
}
@Test
public void readFile() throws IOException {
Path path = new Path("/user/root/test.txt");
// 检查文件是否存在
if (!fs.exists(path)) {
System.out.println("File does not exist, attempting to upload...");
Path localFilePath = new Path("D:\\hadoop.txt");
fs.copyFromLocalFile(localFilePath, path);
System.out.println("File uploaded successfully.");
}
FileStatus fileStatus = fs.getFileStatus(path);
BlockLocation[] blockLocations = fs.getFileBlockLocations(fileStatus, 0, fileStatus.getLen());
// 打印文件块位置信息
for (BlockLocation blk : blockLocations) {
System.out.println(blk);
}
// 逐字节读取并打印前5个字符
try (FSDataInputStream fdis = fs.open(path)) {
for (int i = 0; i < 5; i++) {
int byteValue = fdis.readByte();
if (byteValue == -1) {
System.out.println("End of file reached before reading 5 bytes.");
break;
}
System.out.println((char) byteValue);
}
}
}
@After
public void close() {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
六、实验思考题
1. 安装linux时,如何配置网络?
在网络配置过程中,可以选择自动获取IP地址或手动设置静态IP地址。对于大多数用户和场景,如个人虚拟机或动态IP环境,选择“自动配置网络”选项是最简便的方法。该选项通过DHCP自动分配包括IP地址、子网掩码和网关在内的所有必要网络参数,确保快速且无误的网络连接。然而,在某些情况下,例如服务器部署或集群节点配置中,需要使用固定的IP地址以保证稳定性和可访问性。这时,你需要在安装界面中选择“手动配置网络”,并输入具体的网络参数。这包括指定一个不与局域网内其他设备冲突的IP地址(如192.168.1.101),对应的子网掩码(如255.255.255.0表示/24网段),默认网关(通常是路由器的IP地址,如192.168.1.1),以及DNS服务器地址(可以是公共DNS如8.8.8.8或是本地运营商提供的DNS)。通过这种方式,你可以确保网络配置完全符合特定需求,为后续的应用和服务提供稳定的网络支持。
2. 为什么要删除/etc/udev/rules.d/70-persistent-net.rules?
虚拟机克隆会导致MAC地址冲突,该文件记录了网络接口的MAC地址与接口名的绑定关系。当克隆虚拟机时,新虚拟机的MAC地址会变化,但系统仍尝试使用原接口名,导致网络服务启动失败。
3. 为什么要设置ssh免密钥登录?如何设置?
Hadoop集群需主节点通过SSH无密码远程启停从节点服务,免密登录提升自动化操作效率及安全性。生成密钥对:ssh-keygen -t rsa -b 4096,将公钥id_rsa.pub内容复制到目标节点的~/.ssh/authorized_keys文件中,或使用ssh-copy-id user@host一键分发。
4. 搭建hadoop时,为什么要配置hadoop.tmp.dir?
该参数定义Hadoop临时文件存储路径(如/opt/hadoop/tmp),避免默认使用/tmp目录(系统重启可能清空数据)。需确保目录存在且权限正确,否则NameNode、DataNode等组件可能因无法读写临时文件而启动失败。
5. 端口号9000和50070的区别?
9000是HDFS NameNode的RPC端口,用于客户端(如Java程序)执行元数据操作(文件增删查改);50070(Hadoop 2.x)或9870(Hadoop 3.x)是NameNode的Web UI端口,通过浏览器访问可查看集群状态、存储报告及日志。两者分别服务于程序通信和人工监控,需在防火墙中开放。
6. 启动过程中如果发现某个datanode出现问题,如何处理?
首先查看日志(logs/hadoop-*-datanode-*.log),常见原因包括磁盘空间不足、hadoop.tmp.dir权限错误、端口冲突或网络不通。检查磁盘使用(df -h)、目录权限(ls -ld)、与NameNode的网络连通性(ping、telnet namenode 9000)。修复后重启DataNode:hdfs --daemon stop datanode && hdfs --daemon start datanode。若问题持续,可尝试重新格式化HDFS。


















 2017
2017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









