







在当今大数据与高速度分析的时代,时间序列数据库如InfluxDB已成为企业监控实时指标、分析历史数据和生成决策洞察的核心基础设施。然而,随着数据量的爆炸式增长,如何有效管理这些数据成为了一个关键挑战。在InfluxDB OSS v2版本中,数据保留和降采样策略的实现方式发生了重大变化。旧版的保留策略(Retention Policy)和连续查询(Continuous Query)已被新的数据生命周期管理和Task功能所取代。本文将全面介绍如何在InfluxDB OSS v2中使用Task实现数据保留和降采样,通过实际案例和代码示例,帮助您构建高效的数据管理方案。
一、为什么数据保留与降采样至关重要?
1.1 存储成本爆炸式增长
想象一下,一个物联网平台每天产生1TB的传感器数据,一年就是365TB。按照当前云存储价格(约$0.02/GB/月),一年的存储成本就高达:
# 计算年存储成本
daily_data_gb = 1024 # 1TB = 1024GB
annual_data_gb = daily_data_gb * 365
cost_per_gb_month = 0.02 # 美元
annual_cost = annual_data_gb * cost_per_gb_month * 12
print(f"年存储成本: ${annual_cost:.2f}")
输出结果:
年存储成本: $89856.00
这仅仅是存储成本,还不包括备份、索引和检索的费用。合理的数据保留策略可以显著降低这些成本。
1.2 查询性能影响
随着数据量增加,查询性能会急剧下降。我们来看一个简单的查询性能对比:
-- 查询最近1小时的高分辨率数据(假设每秒一个数据点)
SELECT * FROM sensor_data WHERE time > now() - 1h;
-- 查询最近1年的高分辨率数据
SELECT * FROM sensor_data WHERE time > now() - 1y;
后者可能需要数分钟甚至更长时间才能返回结果,严重影响用户体验。
1.3 合规性要求
许多行业法规对数据保留有严格要求:
- GDPR要求个人数据在不再需要时必须删除
- HIPAA要求医疗数据保留至少6年
- 金融行业通常需要保留交易数据7年
不遵守这些规定可能导致巨额罚款。

二、InfluxDB数据保留策略详解
2.1 保留策略基础
InfluxDB的保留策略(Retention Policy, RP)决定了数据在数据库中保留多长时间。一个RP包含以下要素:
- 名称:唯一标识符
- 持续时间:数据保留时间
- 复制因子:数据副本数量
- 分片组持续时间:影响存储和查询性能
2.2 创建与管理保留策略
下面是V1版本实现,后面提供V2版本进行对比。
创建新RP:
-- 创建一个名为"one_week"的RP,保留7天数据,复制因子为1
CREATE RETENTION POLICY "one_week" ON "iot_db"
DURATION 7d REPLICATION 1 DEFAULT;
修改现有RP:
-- 将"one_week" RP的保留时间改为30天
ALTER RETENTION POLICY "one_week" ON "iot_db" DURATION 30d;
删除RP(谨慎使用):
-- 删除"one_week" RP
DROP RETENTION POLICY "one_week" ON "iot_db";
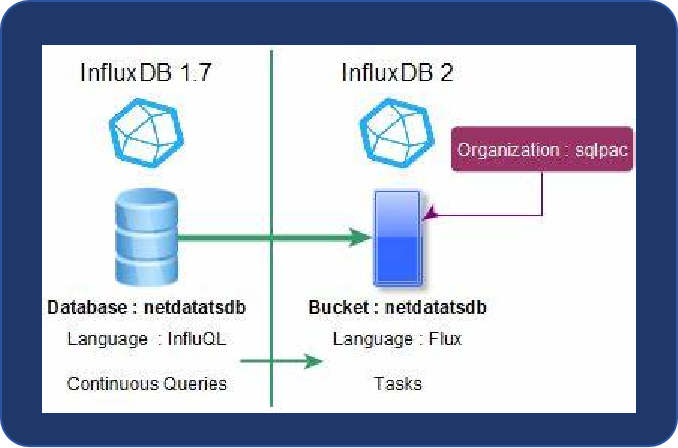
在v2中,数据保留通过bucket的retentionRules配置:
# 创建一个名为"iot_data"的bucket,保留30天数据
influx bucket create \
--name iot_data \
--retention 30d \
--org my-org
查看Bucket的保留规则:
influx bucket find --name iot_data
修改Bucket的保留规则:
# 将"iot_data" bucket的保留时间改为90天
influx bucket update \
--id <bucket-id> \
--retention 90d \
--org my-org
2.3 实际案例:分层存储策略
让我们设计一个分层存储方案,平衡实时分析和历史分析的需求:
-
热数据层(hot_data_rp):保留7天,高粒度,用于实时监控和告警
CREATE RETENTION POLICY "hot_data_rp" ON "iot_db" DURATION 7d REPLICATION 1 DEFAULT; -
温数据层(warm_data_rp):保留30天,每小时聚合,用于日常分析
CREATE RETENTION POLICY "warm_data_rp" ON "iot_db" DURATION 30d REPLICATION 1; -
冷数据层(cold_data_rp):保留1年,每天聚合,用于长期趋势分析
CREATE RETENTION POLICY "cold_data_rp" ON "iot_db" DURATION 1y REPLICATION 1;
虽然v2没有直接的"分层存储"概念,但可以通过多个Bucket和Task组合实现类似效果:
-
热数据Bucket(hot_bucket):保留7天,高粒度
influx bucket create --name hot_bucket --retention 7d --org my-org -
温数据Bucket(warm_bucket):保留30天,降采样后数据
influx bucket create --name warm_bucket --retention 30d --org my-org -
冷数据Bucket(cold_bucket):保留1年,进一步降采样后数据
influx bucket create --name cold_bucket --retention 1y --org my-org
2.4 自动化备份策略
虽然RP会自动删除旧数据,但我们仍需要保留历史数据用于合规。可以使用InfluxDB的备份功能:
# 备份整个数据库
influxd backup -database iot_db /backup/iot_db_$(date +%Y%m%d)
# 备份特定RP
influxd backup -database iot_db -retention hot_data_rp /backup/iot_db_hot_$(date +%Y%m%d)
三、连续查询实现高效降采样
3.1 为什么需要降采样?
假设我们有一个传感器每秒记录一次温度数据:
- 1天 = 86400个数据点
- 1年 = 3.15亿个数据点
直接存储这样的高分辨率数据会导致:
- 存储成本急剧增加
- 查询性能显著下降
- 难以进行长期趋势分析
降采样可以将这些数据聚合为更粗的时间粒度,如每小时平均值,从而:
- 减少存储需求99%以上
- 提高查询性能
- 保留足够的信息用于趋势分析
3.2 连续查询基础
连续查询(Continuous Query, CQ)是InfluxDB中自动运行的预定义查询,非常适合降采样。其基本语法:
CREATE CONTINUOUS QUERY cq_name ON database_name
BEGIN
SELECT aggregation_function(field) INTO target_measurement
FROM source_measurement
GROUP BY time(interval), [tag_key]
END
3.3 实际案例:温度传感器数据降采样
假设我们有一个温度传感器数据表sensor_temperature,每秒记录一次温度:
-- 原始数据示例
SELECT * FROM sensor_temperature
WHERE time > now() - 1h LIMIT 5;
步骤1:创建温数据RP
CREATE RETENTION POLICY "warm_data_rp" ON "iot_db"
DURATION 30d REPLICATION 1;
步骤2:创建每小时平均温度的CQ
CREATE CONTINUOUS QUERY "cq_hourly_avg" ON "iot_db"
BEGIN
SELECT mean("temperature") AS "avg_temperature"
INTO "warm_data_rp"."hourly_avg_temperature"
FROM "sensor_temperature"
GROUP BY time(1h), "sensor_id"
END
步骤3:创建每天最大/最小温度的CQ
CREATE CONTINUOUS QUERY "cq_daily_extremes" ON "iot_db"
BEGIN
SELECT
max("temperature") AS "max_temperature",
min("temperature") AS "min_temperature"
INTO "warm_data_rp"."daily_extremes"
FROM "sensor_temperature"
GROUP BY time(1d), "sensor_id"
END
3.4 多维度降采样案例
对于更复杂的场景,我们可以同时计算多个聚合指标:
CREATE CONTINUOUS QUERY "cq_hourly_stats" ON "iot_db"
BEGIN
SELECT
mean("temperature") AS "avg_temperature",
max("temperature") AS "max_temperature",
min("temperature") AS "min_temperature",
count("temperature") AS "readings_count"
INTO "warm_data_rp"."hourly_stats"
FROM "sensor_temperature"
GROUP BY time(1h), "sensor_id", "location"
END
3.5 降采样策略最佳实践
-
选择合适的聚合函数:
- 对于温度、湿度等连续值:
mean()、max()、min() - 对于计数事件:
sum()、count()
- 对于温度、湿度等连续值:
-
优化时间间隔:
- 实时监控:1分钟或更细粒度
- 日常分析:1小时或1天
- 长期趋势:1周或1月
-
考虑标签维度:
- 按传感器ID、位置等分组,保留多维分析能力
-
测试与验证:
-- 测试CQ在历史数据上的效果 SELECT mean("temperature") AS "avg_temperature" FROM "sensor_temperature" WHERE time > now() - 1d GROUP BY time(1h), "sensor_id"; -
监控CQ性能:
- 使用
SHOW CONTINUOUS QUERIES查看所有CQ - 监控InfluxDB的系统指标,确保CQ不会过度消耗资源
- 使用
四、使用Task实现降采样
3.1 Task基础
Task是InfluxDB v2中执行定期数据处理操作的核心功能,可以:
- 执行Flux查询
- 将结果写入其他Bucket
- 设置执行频率
3.2 创建降采样Task示例
场景:将原始传感器数据(每秒记录)降采样为每小时平均值,存储到温数据Bucket
步骤1:创建Flux查询
// 降采样查询:计算每小时平均温度
from(bucket: "hot_bucket")
|> range(start: -1h) // 处理过去1小时的数据
|> filter(fn: (r) => r._measurement == "sensor_temperature")
|> filter(fn: (r) => r._field == "temperature")
|> aggregateWindow(every: 1h, fn: mean) // 按小时聚合
|> to(bucket: "warm_bucket", org: "my-org") // 写入温数据Bucket
步骤2:创建Task
influx task create \
--name hourly_avg_temperature \
--flux 'from(bucket: "hot_bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_temperature")
|> filter(fn: (r) => r._field == "temperature")
|> aggregateWindow(every: 1h, fn: mean)
|> to(bucket: "warm_bucket", org: "my-org")' \
--every 1h \ # 每小时执行一次
--org my-org
查看Task状态:
influx task find --name hourly_avg_temperature
3.3 多维度降采样Task
场景:同时计算每小时的平均值、最大值和最小值
from(bucket: "hot_bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_temperature")
|> filter(fn: (r) => r._field == "temperature")
|> aggregateWindow(every: 1h, fn: [mean, max, min]) // 同时计算多个聚合
|> to(bucket: "warm_bucket", org: "my-org")
3.4 复杂降采样场景
场景:按传感器ID和位置分组降采样
from(bucket: "hot_bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "sensor_temperature")
|> filter(fn: (r) => r._field == "temperature")
|> group(columns: ["sensor_id", "location"]) // 按传感器ID和位置分组
|> aggregateWindow(every: 1h, fn: mean)
|> to(bucket: "warm_bucket", org: "my-org")
五、平衡存储与粒度:决策框架
4.1 数据价值评估矩阵
| 数据类型 | 保留期限 | 粒度 | 用途 |
|---|---|---|---|
| 实时监控数据 | 7天 | 秒级 | 告警、实时分析 |
| 日常分析数据 | 30天 | 小时级 | 日常报告、趋势分析 |
| 长期趋势数据 | 1年 | 天级 | 季度/年度报告、长期预测 |
| 合规数据 | 7年 | 原始粒度 | 法规合规 |
4.2 成本效益分析模型
def calculate_cost_benefit(high_res_data_gb, downsampled_data_gb,
query_freq_high, query_freq_down,
cost_per_gb_month):
"""
计算降采样前后的成本效益
参数:
high_res_data_gb: 高分辨率数据大小(GB)
downsampled_data_gb: 降采样后数据大小(GB)
query_freq_high: 高分辨率查询频率(次/月)
query_freq_down: 降采样查询频率(次/月)
cost_per_gb_month: 每GB每月成本(美元)
返回:
成本节约和性能提升的评估
"""
# 存储成本
high_res_cost = high_res_data_gb * cost_per_gb_month
downsampled_cost = downsampled_data_gb * cost_per_gb_month
# 查询成本(简化模型,假设查询时间与数据量成正比)
high_res_query_cost = query_freq_high * 0.01 # 假设每次高分辨率查询成本$0.01
downsampled_query_cost = query_freq_down * 0.001 # 假设每次降采样查询成本$0.001
total_high_res_cost = high_res_cost + high_res_query_cost
total_downsampled_cost = downsampled_cost + downsampled_query_cost
cost_saving = total_high_res_cost - total_downsampled_cost
performance_improvement = (high_res_query_cost - downsampled_query_cost) / high_res_query_cost * 100
return {
"storage_saving": high_res_cost - downsampled_cost,
"query_saving": high_res_query_cost - downsampled_query_cost,
"total_saving": cost_saving,
"performance_improvement_percent": performance_improvement
}
# 示例计算
result = calculate_cost_benefit(
high_res_data_gb=1024, # 1TB
downsampled_data_gb=10, # 降采样后10GB
query_freq_high=1000, # 每月1000次高分辨率查询
query_freq_down=5000, # 每月5000次降采样查询
cost_per_gb_month=0.02
)
print("成本效益分析结果:")
for k, v in result.items():
print(f"{k}: {v:.2f}")
输出结果:
成本效益分析结果:
storage_saving: 1014.00
query_saving: 5.00
total_saving: 1019.00
performance_improvement_percent: 80.00
4.3 决策流程图
六、高级技巧与优化
5.1 动态保留策略
根据数据年龄自动调整保留策略:
-- 创建一个函数来动态调整RP(需要InfluxDB企业版或自定义解决方案)
-- 这是一个概念示例,实际实现可能需要外部脚本
5.2 数据生命周期管理
结合外部工具实现更复杂的数据生命周期:
# 使用InfluxDB的备份和恢复功能实现数据归档
influxd backup -database iot_db -retention cold_data_rp /archive/iot_db_cold_$(date +%Y%m%d)
5.3 监控与告警
设置监控来跟踪数据保留和降采样的效果:
-- 监控RP中的数据量
SELECT sum("bytes") FROM "_internal"."database"
WHERE "name" = 'iot_db' AND "retention_policy" = 'hot_data_rp';
-- 监控CQ的执行情况
SHOW CONTINUOUS QUERIES;
5.4 动态Task调度
虽然v2没有内置的动态调度功能,但可以通过外部系统(如Kubernetes CronJob)控制Task的启用/禁用:
# 启用Task
influx task update --id <task-id> --status active
# 禁用Task
influx task update --id <task-id> --status inactive
5.5 数据生命周期管理增强
结合外部工具实现更复杂的数据归档:
# 将冷数据Bucket的数据导出到对象存储
influx export -b cold_bucket -o my-org -f csv -p /archive/cold_data_$(date +%Y%m%d).csv
5.6 Task监控与告警
设置监控来跟踪Task执行和数据保留情况:
# 查看Task执行状态
influx task find --name hourly_avg_temperature
# 查看Bucket数据量
influx bucket find --name warm_bucket
七、总结与行动建议
数据保留与降采样是InfluxDB管理的核心组成部分,直接影响存储成本、查询性能和业务价值。通过本文的策略和案例,您可以:
- 建立分层存储体系:根据数据价值和使用频率设置不同的RP
- 实施智能降采样:使用CQ自动创建多粒度的数据视图
- 平衡成本与效益:通过分析确定最优的保留和降采样策略
- 持续优化:定期审查和调整策略以适应业务变化
立即行动:
- 审查您现有的RP设置,确保它们符合业务需求
- 为关键数据流设计降采样方案
- 设置监控来跟踪数据保留和降采样的效果
- 制定定期审查机制,确保策略保持最优
记住,在数据管理中,没有"一刀切"的解决方案。根据您的具体业务需求、数据特性和合规要求,调整这些策略以达到最佳效果。通过精心设计的数据保留和降采样策略,您可以将InfluxDB转变为一个高效、经济且合规的数据管理平台,为您的业务决策提供强大支持。
互动讨论:
- 您在数据保留和降采样方面遇到过哪些挑战?
- 您的组织如何平衡数据保留成本与分析需求?
- 欢迎分享您的成功案例或遇到的问题,让我们共同探讨解决方案!
通过本文的深入探讨和实用指南,希望您能够掌握InfluxDB数据保留与降采样的艺术,构建高效、经济且合规的时间序列数据管理方案。

















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









