




1.手动下载chrome
下载地址:https://npm.taobao.org/mirrors/chromium-browser-snapshots/Win_x64/650583/
下载完成之后,找个地方保存并解压。
2.找到requests_html运行chrome的路径
进入python安装目录下的\Lib\site-packages\pyppeteer 打开chromium_downloader.py文件,可以看到不同系统执行chromium的路径如下图所示
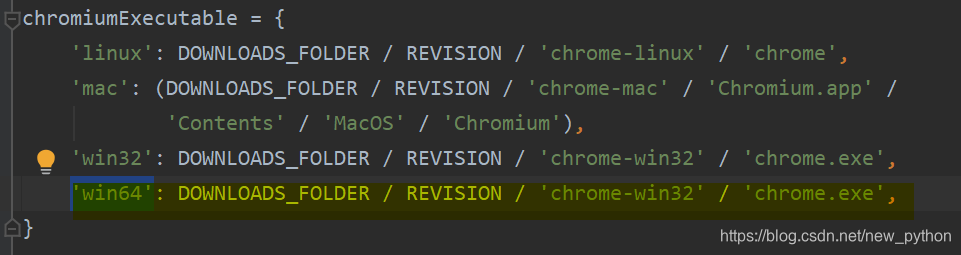 其中黄色为笔者的64 位windows操作系统(以该操作系统为例),可以看到在该操作系统下,chromium的执行路径为DOWNLOADS_FOLDER / REVISION / ‘chrome-win32’ / ‘chrome.exe’
其中黄色为笔者的64 位windows操作系统(以该操作系统为例),可以看到在该操作系统下,chromium的执行路径为DOWNLOADS_FOLDER / REVISION / ‘chrome-win32’ / ‘chrome.exe’
我们继续往前找DOWNLOADS_FOLDER、REVISION 发现他们的路径依赖于__chromium_revision__,和__pyppeteer_home__,而这两个属性在这个文件中已经被导入了。


 重点
重点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1070
1070




 到【灌水乐园】发言
到【灌水乐园】发言







