




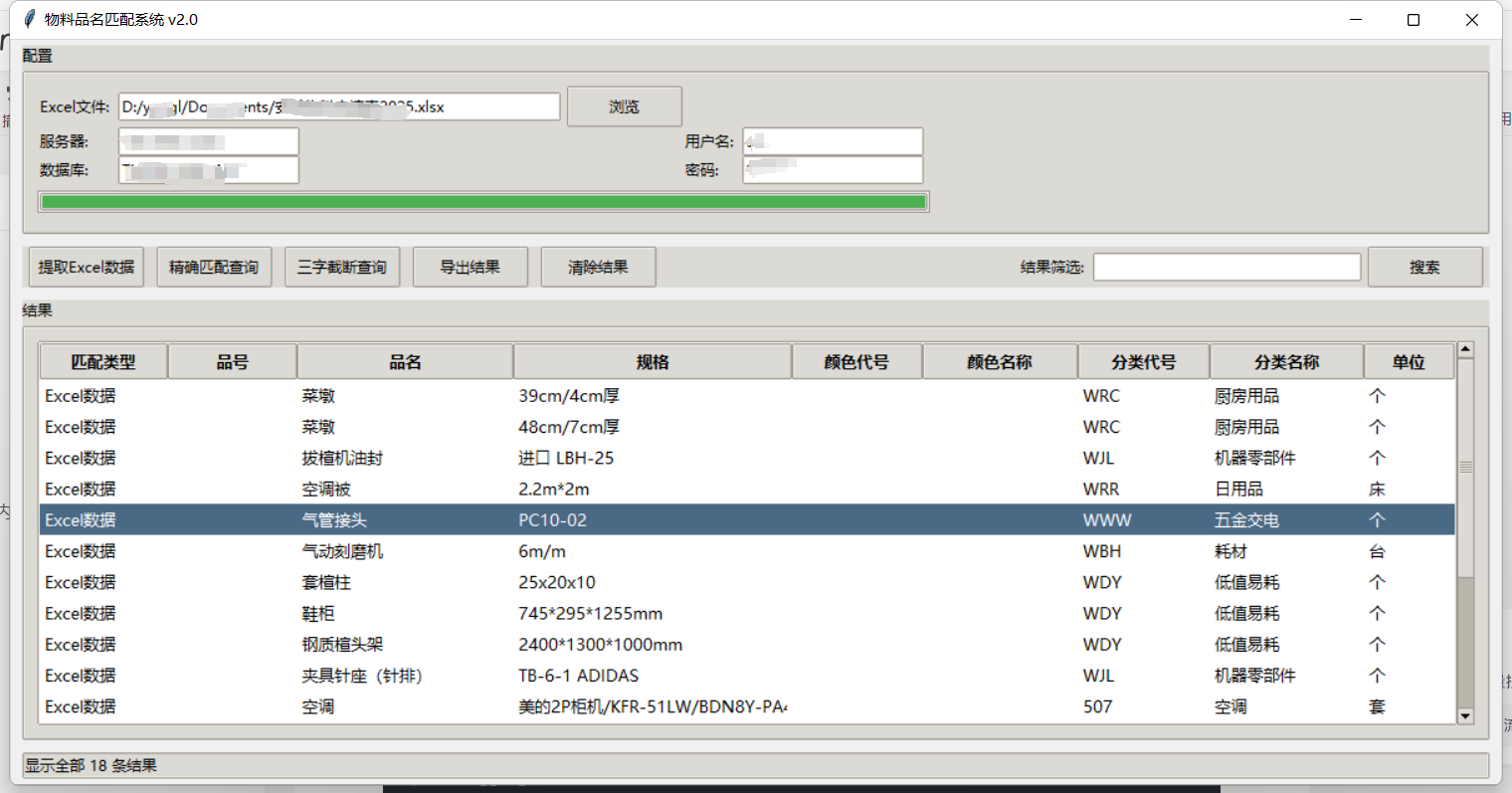
1、实现从excel表内提取内容显示出来。
2、通过提取出来的某列内容,查询数据库,找出相同或者类似字段内容的内容,显示出来。
3、可通过右击、双击某个内容进行复制内容到结果筛选框进行进一步搜索。
import pandas as pd
import pyodbc
from fuzzywuzzy import fuzz
import re
from typing import List, Dict, Any, Optional, Tuple
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import threading
import logging
import gc
from datetime import datetime
"""此版本优化了性能,美化了界面显示,增加按表头排序,导出结果功能"""
class ProductSearchApp:
def __init__(self, root):
self.root = root
self.root.title("物料品名匹配系统 v2.0")
self.root.geometry("1200x600")
# 初始化日志
logging.basicConfig(
filename='product_search.log',
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
self.logger = logging.getLogger()
# 数据库配置
self.db_config = {
"server": "IP",
"database": "DB",
"username": "admin",
"password": "admin",
"table_name": "test",
"search_columns": ["test002", "test003"]
}
# 存储所有结果数据
self.all_results = []
self.last_clicked_column = None
self.create_widgets()
self.setup_bindings()
# 初始化样式
self.setup_styles()
# 记录启动时间
self.logger.info("应用程序启动")
def setup_styles(self):
"""设置界面样式"""
style = ttk.Style()
style.theme_use('clam')
# 配置Treeview样式
style.configure("Treeview",
rowheight=25,
font=('Microsoft YaHei', 10))
style.configure("Treeview.Heading",
font=('Microsoft YaHei', 10, 'bold'))
# 配置按钮样式
style.configure('TButton', padding=5, font=('Microsoft YaHei', 9))
# 配置进度条样式
style.configure("Horizontal.TProgressbar",
thickness=20,
troughcolor='#f0f0f0',
background='#4caf50')
def create_widgets(self):
"""创建界面组件"""
# 顶部框架 - 文件选择和数据库配置
top_frame = ttk.LabelFrame(self.root, text="配置", padding=10)
top_frame.pack(fill=tk.X, padx=10, pady=5)
# 文件选择
ttk.Label(top_frame, text="Excel文件:").grid(row=0, column=0, sticky=tk.W)
self.file_entry = ttk.Entry(top_frame, width=50)
self.file_entry.grid(row=0, column=1, padx=5)
ttk.Button(top_frame, text="浏览", command=self.browse_file).grid(row=0, column=2)
# 数据库配置
ttk.Label(top_frame, text="服务器:").grid(row=1, column=0, sticky=tk.W)
self.server_entry = ttk.Entry(top_frame)
self.server_entry.insert(0, self.db_config["server"])
self.server_entry.grid(row=1, column=1, padx=5, sticky=tk.W)
ttk.Label(top_frame, text="数据库:").grid(row=2, column=0, sticky=tk.W)
self.db_entry = ttk.Entry(top_frame)
self.db_entry.insert(0, self.db_config["database"])
self.db_entry.grid(row=2, column=1, padx=5, sticky=tk.W)
ttk.Label(top_frame, text="用户名:").grid(row=1, column=3, sticky=tk.W)
self.user_entry = ttk.Entry(top_frame)
self.user_entry.insert(0, self.db_config["username"])
self.user_entry.grid(row=1, column=4, padx=5, sticky=tk.W)
ttk.Label(top_frame, text="密码:").grid(row=2, column=3, sticky=tk.W)
self.pwd_entry = ttk.Entry(top_frame, show="*")
self.pwd_entry.insert(0, self.db_config["password"])
self.pwd_entry.grid(row=2, column=4, padx=5, sticky=tk.W)
# 进度条
self.progress = ttk.Progressbar(top_frame, orient=tk.HORIZONTAL,
length=200, mode='determinate',
style="Horizontal.TProgressbar")
self.progress.grid(row=3, column=0, columnspan=5, pady=5, sticky=tk.EW)
# 中间框架 - 操作按钮和搜索框
middle_frame = ttk.Frame(self.root)
middle_frame.pack(fill=tk.X, padx=10, pady=5)
# 操作按钮框架
btn_frame = ttk.Frame(middle_frame)
btn_frame.pack(side=tk.LEFT, fill=tk.X, expand=True)
ttk.Button(btn_frame, text="提取Excel数据", command=self.extract_data).pack(side=tk.LEFT, padx=5)
ttk.Button(btn_frame, text="精确匹配查询", command=self.run_normal_search).pack(side=tk.LEFT, padx=5)
ttk.Button(btn_frame, text="三字截断查询", command=self.run_truncated_search).pack(side=tk.LEFT, padx=5)
ttk.Button(btn_frame, text="导出结果", command=self.export_results).pack(side=tk.LEFT, padx=5)
ttk.Button(btn_frame, text="清除结果", command=self.clear_results).pack(side=tk.LEFT, padx=5)
# 结果搜索框架
search_frame = ttk.Frame(middle_frame)
search_frame.pack(side=tk.RIGHT, fill=tk.X, padx=5)
ttk.Label(search_frame, text="结果筛选:").pack(side=tk.LEFT)
self.result_search_entry = ttk.Entry(search_frame, width=30)
self.result_search_entry.pack(side=tk.LEFT, padx=5)
self.result_search_entry.bind("<Return>", lambda event: self.filter_results())
ttk.Button(search_frame, text="搜索", command=self.filter_results).pack(side=tk.LEFT)
# 底部框架 - 结果显示
result_frame = ttk.LabelFrame(self.root, text="结果", padding=10)
result_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
# 树状视图显示结果
self.tree = ttk.Treeview(result_frame, columns=(
"type", "code", "name", "spec", "color_code", "color_name",
"category_code", "category_name", "unit"), show="headings")
# 设置列标题和宽度
columns = [
("type", "匹配类型", 80),
("code", "品号", 80),
("name", "品名", 150),
("spec", "规格", 200),
("color_code", "颜色代号", 80),
("color_name", "颜色名称", 100),
("category_code", "分类代号", 80),
("category_name", "分类名称", 100),
("unit", "单位", 50)
]
for col_id, col_text, width in columns:
self.tree.heading(col_id, text=col_text,
command=lambda c=col_id: self.treeview_sort_column(c, False))
self.tree.column(col_id, width=width, anchor=tk.W)
# 添加滚动条
scrollbar = ttk.Scrollbar(result_frame, orient=tk.VERTICAL, command=self.tree.yview)
self.tree.configure(yscroll=scrollbar.set)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.tree.pack(fill=tk.BOTH, expand=True)
# 状态栏
self.status_var = tk.StringVar() # 状态栏文本变量
self.status_var.set("就绪")
ttk.Label(self.root, textvariable=self.status_var, relief=tk.SUNKEN).pack(fill=tk.X, padx=10, pady=5)
def setup_bindings(self):
"""设置事件绑定"""
# 绑定Ctrl+C复制功能
self.tree.bind("<Control-c>", self.copy_selection)
self.tree.bind("<Control-C>", self.copy_selection)
# 绑定双击事件
self.tree.bind("<Double-1>", self.copy_selection)
# 右键菜单
self.context_menu = tk.Menu(self.root, tearoff=0)
self.context_menu.add_command(label="复制单元格",
command=lambda: self.copy_selection(is_context_menu=True))
self.tree.bind("<Button-3>", self.show_context_menu)
def show_context_menu(self, event):
"""显示右键菜单"""
# 获取鼠标点击位置对应的树形结构中的行ID
row_id = self.tree.identify_row(event.y)
# 获取鼠标点击位置对应的树形结构中的列ID
column_id = self.tree.identify_column(event.x)
# 如果row_id存在,则表示有特定的行需要被选中
if row_id:
# 设置树视图中特定行被选中
self.tree.selection_set(row_id)
# 记录最后一次点击的列ID,以便后续操作使用
self.last_clicked_column = column_id
# 在鼠标点击位置弹出上下文菜单
self.context_menu.post(event.x_root, event.y_root)
def copy_selection(self, event=None, is_context_menu=False):
"""复制选中单元格内容"""
selected_items = self.tree.selection()
if not selected_items:
return
# 获取当前列
if event and hasattr(event, "x") and hasattr(event, "y"):
column_id = self.tree.identify_column(event.x)
elif is_context_menu and hasattr(self, 'last_clicked_column'):
column_id = self.last_clicked_column
else:
column_id = "#1"
if not column_id:
return
col_index = int(column_id[1:]) - 1
copied_text = ""
for item in selected_items:
item_values = self.tree.item(item, "values")
if 0 <= col_index < len(item_values):
copied_text += str(item_values[col_index]) + "\n"
copied_text = copied_text.strip()
# 复制到剪贴板
self.root.clipboard_clear()
self.root.clipboard_append(copied_text)
# 自动填充搜索框
if (event and hasattr(event, "num") and event.num == 1) or is_context_menu:
first_item = self.tree.item(selected_items[0], "values")
if 0 <= col_index < len(first_item):
search_text = str(first_item[col_index])
if search_text:
self.result_search_entry.delete(0, tk.END)
self.result_search_entry.insert(0, search_text)
self.filter_results()
def treeview_sort_column(self, col, reverse):
"""树状视图列排序"""
data = [(self.tree.set(child, col), child) for child in self.tree.get_children('')]
data.sort(reverse=reverse)
for index, (val, child) in enumerate(data):
self.tree.move(child, '', index)
self.tree.heading(col, command=lambda: self.treeview_sort_column(col, not reverse))
def browse_file(self):
"""浏览文件"""
filename = filedialog.askopenfilename(
filetypes=[("Excel文件", "*.xlsx *.xls"), ("所有文件", "*.*")],
title="选择Excel文件"
)
if filename:
self.file_entry.delete(0, tk.END) # 清空输入框
self.file_entry.insert(0, filename) # 插入文件名
self.logger.info(f"选择文件: {filename}") # 记录日志
def update_status(self, message):
"""
更新状态栏
此函数接受一个消息参数,并用它来更新应用程序的状态栏显示
同时,该消息会被记录到日志中,以便于跟踪和调试
参数:
message (str): 要显示和记录的消息
返回:
无
"""
# 设置状态变量的值为传入的消息,以更新状态栏的显示
self.status_var.set(message)
# 更新根窗口,确保状态栏的显示变化能够及时反映在界面上
self.root.update()
# 记录状态更新的消息到日志,以便于后续的跟踪和调试
self.logger.info(f"状态更新: {message}")
def clear_results(self):
"""清除结果"""
for item in self.tree.get_children():
self.tree.delete(item)
self.all_results = []
self.update_status("结果已清除")
self.progress["value"] = 0
gc.collect()
def filter_results(self):
"""筛选结果"""
search_term = self.result_search_entry.get().strip()
if not search_term:
self.display_all_results()
return
filtered_results = []
for result in self.all_results:
if any(search_term.lower() in str(value).lower() for value in result):
filtered_results.append(result)
for item in self.tree.get_children():
self.tree.delete(item)
for result in filtered_results:
self.tree.insert("", tk.END, values=result)
self.update_status(f"找到 {len(filtered_results)} 条匹配结果")
def display_all_results(self):
"""显示所有结果"""
for item in self.tree.get_children():
self.tree.delete(item)
for result in self.all_results:
self.tree.insert("", tk.END, values=result)
self.update_status(f"显示全部 {len(self.all_results)} 条结果")
def extract_data(self):
"""从Excel提取数据"""
file_path = self.file_entry.get()
if not file_path:
messagebox.showerror("错误", "请先选择Excel文件")
return
try:
self.update_status("正在提取Excel数据...")
self.progress["value"] = 0
extracted_data = self.extract_data_from_excel(file_path)
if extracted_data:
self.clear_results()
for data in extracted_data:
self.tree.insert("", tk.END, values=("Excel数据", "", *data))
self.all_results.append(("Excel数据", "", *data))
self.update_status(f"成功提取 {len(extracted_data)} 条数据")
self.progress["value"] = 100
else:
messagebox.showwarning("警告", "没有提取到数据")
self.update_status("没有提取到数据")
except Exception as e:
messagebox.showerror("错误", f"提取数据失败: {str(e)}")
self.update_status(f"提取错误: {str(e)}")
self.logger.error(f"提取数据失败: {str(e)}", exc_info=True)
finally:
gc.collect()
def run_normal_search(self):
"""执行精确匹配查询"""
self.run_search(truncate=False)
def run_truncated_search(self):
"""执行三字截断查询"""
self.run_search(truncate=True)
def run_search(self, truncate=False):
"""执行查询"""
file_path = self.file_entry.get()
if not file_path:
messagebox.showerror("错误", "请先选择Excel文件")
return
# 更新数据库配置
self.db_config.update({
"server": self.server_entry.get(),
"database": self.db_entry.get(),
"username": self.user_entry.get(),
"password": self.pwd_entry.get()
})
# 在后台线程中执行搜索
threading.Thread(
target=self.perform_search,
args=(file_path, truncate),
daemon=True
).start()
def perform_search(self, file_path, truncate):
"""执行搜索操作"""
try:
self.progress["value"] = 0
self.progress["maximum"] = 4
self.update_status("正在提取品名..." if not truncate else "正在提取并处理品名...")
extracted_data = self.extract_data_from_excel(file_path)
self.progress["value"] = 1
if not extracted_data:
messagebox.showwarning("警告", "没有提取到数据")
self.update_status("没有提取到数据")
return
product_names = [data[0] for data in extracted_data]
self.progress["value"] = 2
if truncate:
truncated_names = []
for name in product_names:
if len(name) >= 3:
truncated_names.append(name[:2])
truncated_names.append(name[-2:])
truncated_names.append(name)
product_names = list(set(truncated_names))
self.update_status("正在连接数据库...")
conn = self.connect_to_sql_server()
if not conn:
return
self.progress["value"] = 3
self.update_status("正在查询数据库...")
results = self.find_similar_products(conn, product_names)
self.progress["value"] = 4
self.clear_results()
if results:
match_count = 0
for result in results:
for match in result["matches"]:
match_type = "三字截断匹配" if truncate else "精确匹配"
item_values = (
match_type,
match.get("MB001", ""),
match.get("MB002", ""),
match.get("MB003", ""),
"", "", "", "", ""
)
self.tree.insert("", tk.END, values=item_values)
self.all_results.append(item_values)
match_count += 1
self.update_status(f"找到 {match_count} 个匹配结果")
else:
self.update_status("没有找到匹配结果")
except Exception as e:
messagebox.showerror("错误", f"查询失败: {str(e)}")
self.update_status(f"查询错误: {str(e)}")
self.logger.error(f"查询失败: {str(e)}", exc_info=True)
finally:
if 'conn' in locals():
conn.close()
self.progress["value"] = 0
gc.collect()
def extract_data_from_excel(self, file_path: str) -> List[tuple]:
"""从Excel提取数据"""
try:
self.update_status("正在分析Excel文件结构...")
# 使用openpyxl引擎提高大文件读取性能
excel_file = pd.ExcelFile(file_path, engine='openpyxl')
sheet_names = excel_file.sheet_names
# 初始化变量
target_sheet = None
start_row = 1
found_columns = {}
# 定义需要查找的列及其可能的名称变体
required_columns = {
"name": ["品名"],
"spec": ["规格"],
"color_code": ["颜色代号", "颜色\n代号", "代号\n颜色"],
"color_name": ["颜色名称", "颜色\n名称", "名称\n颜色"],
"category_code": ["分类代号", "分类\n代号", "代号\n分类"],
"category_name": ["分类名称", "分类\n名称", "名称\n分类"],
"unit": ["单位"]
}
# 查找目标sheet(优先查找"物料申请表")
for sheet in [s for s in sheet_names if s == "物料申请表"] + [s for s in reversed(sheet_names) if
s != "物料申请表"]:
try:
df = pd.read_excel(file_path, sheet_name=sheet, header=None, nrows=15, engine='openpyxl')
except Exception as e:
self.logger.warning(f"读取工作表 {sheet} 失败: {str(e)}")
continue
# 检测列名所在行
for row_idx in range(min(15, len(df))):
current_row_found = {}
for col_idx in range(min(20, len(df.columns))):
cell_value = str(df.iloc[row_idx, col_idx]).strip()
for field, names in required_columns.items():
if field not in current_row_found:
for name in names:
if name in cell_value:
current_row_found[field] = col_idx
break
if "name" in current_row_found:
target_sheet = sheet
start_row = row_idx + 1
found_columns = current_row_found
break
if target_sheet is not None:
break
if target_sheet is None:
raise ValueError("未找到包含'品名'列的工作表")
if "name" not in found_columns:
raise ValueError("工作表中未找到'品名'列")
# 读取目标sheet的全部数据
df = pd.read_excel(file_path, sheet_name=target_sheet, header=None, engine='openpyxl')
self.update_status(f"正在提取数据,共{len(df) - start_row}行...")
# 提取数据
extracted_data = []
for row_idx in range(start_row, len(df)):
name = str(df.iloc[row_idx, found_columns["name"]]).strip()
if not name or name == "nan" or name.isdigit():
continue
clean_name = re.sub(r'[\s\u3000]+', ' ', name)
spec = ""
if "spec" in found_columns and found_columns["spec"] < len(df.columns):
spec_value = df.iloc[row_idx, found_columns["spec"]]
if pd.notna(spec_value):
spec = str(spec_value).strip()
spec = re.sub(r'[\s\u3000]+', ' ', spec)
color_code = ""
if "color_code" in found_columns and found_columns["color_code"] < len(df.columns):
color_code_value = df.iloc[row_idx, found_columns["color_code"]]
if pd.notna(color_code_value):
color_code = str(color_code_value).strip()
color_name = ""
if "color_name" in found_columns and found_columns["color_name"] < len(df.columns):
color_name_value = df.iloc[row_idx, found_columns["color_name"]]
if pd.notna(color_name_value):
color_name = str(color_name_value).strip()
category_code = ""
if "category_code" in found_columns and found_columns["category_code"] < len(df.columns):
category_code_value = df.iloc[row_idx, found_columns["category_code"]]
if pd.notna(category_code_value):
category_code = str(category_code_value).strip()
category_name = ""
if "category_name" in found_columns and found_columns["category_name"] < len(df.columns):
category_name_value = df.iloc[row_idx, found_columns["category_name"]]
if pd.notna(category_name_value):
category_name = str(category_name_value).strip()
unit = ""
if "unit" in found_columns and found_columns["unit"] < len(df.columns):
unit_value = df.iloc[row_idx, found_columns["unit"]]
if pd.notna(unit_value):
unit = str(unit_value).strip()
unit = re.sub(r'[\s\u3000]+', '', unit)
extracted_data.append((
clean_name, spec, color_code, color_name,
category_code, category_name, unit
))
return extracted_data
except Exception as e:
raise Exception(f"Excel提取错误: {str(e)}")
def connect_to_sql_server(self) -> Optional[pyodbc.Connection]:
"""连接SQL Server数据库"""
try:
conn_str = (
f"DRIVER={{ODBC Driver 17 for SQL Server}};"
f"SERVER={self.db_config['server']};"
f"DATABASE={self.db_config['database']};"
f"UID={self.db_config['username']};"
f"PWD={self.db_config['password']};"
"TrustServerCertificate=yes;"
"Encrypt=yes;"
"Connection Timeout=15;"
"MultipleActiveResultSets=True;"
)
conn = pyodbc.connect(conn_str, autocommit=True)
self.logger.info("数据库连接成功")
return conn
except pyodbc.Error as e:
messagebox.showerror("数据库错误", f"连接失败: {str(e)}")
self.update_status(f"数据库连接失败: {str(e)}")
self.logger.error(f"数据库连接失败: {str(e)}", exc_info=True)
return None
def find_similar_products(self, conn: pyodbc.Connection, product_names: List[str]) -> List[Dict[str, Any]]:
"""查找相似产品"""
try:
cursor = conn.cursor()
results = []
unique_names = list(set(product_names))
# 批量查询优化
query = f"""
SELECT MB001, MB002, MB003, MB004
FROM {self.db_config['table_name']}
WHERE MB002 LIKE ? OR MB003 LIKE ?
ORDER BY LEN(MB002)
"""
for name in unique_names:
clean_name = re.sub(r'[^\w\u4e00-\u9fff]', '', str(name))
params = [f"%{clean_name}%", f"%{clean_name}%"]
cursor.execute(query, *params)
rows = cursor.fetchall()
# 如果没有结果,尝试模糊匹配
if not rows:
fuzzy_query = f"""
SELECT TOP 10 MB001, MB002, MB003, MB004
FROM {self.db_config['table_name']}
WHERE DIFFERENCE(MB002, ?) >= 3
ORDER BY DIFFERENCE(MB002, ?) DESC
"""
cursor.execute(fuzzy_query, (clean_name, clean_name))
rows = cursor.fetchall()
if rows:
results.append({
'search_term': name,
'matches': [dict(zip([column[0] for column in cursor.description], row)) for row in rows]
})
return results
except Exception as e:
raise Exception(f"查询错误: {e}")
finally:
cursor.close()
def export_results(self):
"""导出结果到Excel"""
if not self.all_results:
messagebox.showwarning("警告", "没有可导出的数据")
return
default_filename = f"物料匹配结果_{datetime.now().strftime('%Y%m%d_%H%M%S')}.xlsx"
file_path = filedialog.asksaveasfilename(
defaultextension=".xlsx",
filetypes=[("Excel文件", "*.xlsx"), ("所有文件", "*.*")],
initialfile=default_filename,
title="保存结果文件"
)
if file_path:
try:
df = pd.DataFrame(self.all_results, columns=[
"匹配类型", "品号", "品名", "规格",
"颜色代号", "颜色名称", "分类代号", "分类名称", "单位"
])
df.to_excel(file_path, index=False, engine='openpyxl')
messagebox.showinfo("成功", f"数据已成功导出到 {file_path}")
self.logger.info(f"结果已导出到 {file_path}")
except Exception as e:
messagebox.showerror("错误", f"导出失败: {str(e)}")
self.logger.error(f"导出失败: {str(e)}", exc_info=True)
if __name__ == "__main__":
root = tk.Tk()
app = ProductSearchApp(root)
root.mainloop()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









