




 本文深入解析JavaScript的基础数据类型、原型链、作用域、闭包、this关键字、new操作符及对象创建方式等核心概念,同时探讨了垃圾回收机制、事件循环、微任务与宏任务的区别。
本文深入解析JavaScript的基础数据类型、原型链、作用域、闭包、this关键字、new操作符及对象创建方式等核心概念,同时探讨了垃圾回收机制、事件循环、微任务与宏任务的区别。
JS的数据类型
最新的 ECMAScript 标准定义了 8 种数据类型:
7 种原始类型:
- Boolean
- Null Undefined
- Number
- BigInt
- String
- Symbol
和Object
原型链
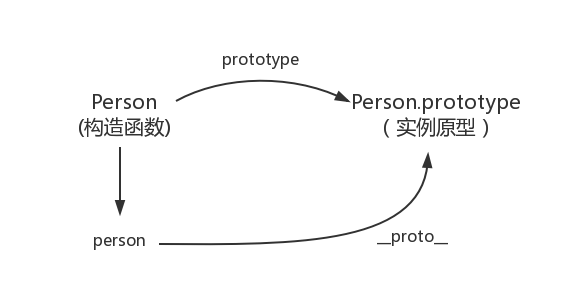
什么是原型(_proto_)呢?原型其实可以理解为JS中 对象与对象之间的关联关系,具体可以这样理解:每一个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型"继承"属性。
当访问某个对象属性的时候,首先会从对象自身查找该属性,如果查找不到,则继续从该对象的原型上查找,如果还查查不到,继续从原型的原型上查找,直到 Object.prototype 这样就形成了一个链,就是原型链。
两个属性:
_proto_
这是每一个JavaScript对象(除了 null )都具有的一个属性,叫__proto__,这个属性会指向该对象的原型,也就是生成该对象的构造函数的prototype属性。
比如:
const a = function(){};
const b = {};
const c = [];
a.__proto__ === Function.prototype;// true a的构造函数为Function 引用MDN的话:每个 JavaScript 函数实际上都是一个 Function 对象。运行 (function(){}).constructor === Function // true 便可以得到这个结论
b.__proto__ === Object.prototype;//true
c.__proto__ === Array.prototype;//true
prototype
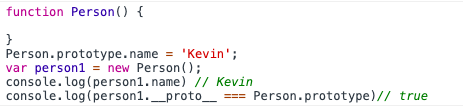
只有函数才有prototype属性,该 prototype 的值正是调用该构造函数而创建的实例的原型(也就是上面提到的 person1.__proto__)
作用域
一句话描述:
作用域是一套规则,规定了在何处 以及如何去查找变量
JavaScript 采用词法作用域(lexical scoping),也就是静态作用域,函数的作用域在定义的时候就决定了,而与之相对的是动态作用域,即:函数的作用域是在函数调用的时候才决定的。
执行上下文栈
JS引擎在遇到一段可执行代码(全局代码、函数代码、eval代码)时,就会创建一个执行上下文,可以理解为JS引擎执行当前代码的一个环境。
而执行上下文栈,就是用来管理执行上下文的,这是一种先入后出的数据结构
执行上下文的三种类型:
- 全局执行上下文
- 函数执行上下文
- eval执行上下文
执行上下文的三个重要内容:
- 变量对象(Variable object,VO)
- 作用域链(Scope chain)
- this
// 尝试分析如下代码中执行上下文栈的变化过程
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();
变量对象
变量对象是与执行上下文相关的数据作用域,存储了在上下文中定义的变量和函数声明。
在全局上下文中,变量对象就是全局对象。
在函数执行上下文中,我们用活动对象(activation object, AO)来表示变量对象。
注:它们其实都是同一个对象,只是处于执行上下文的不同生命周期
未进入执行阶段之前,变量对象(VO)中的属性都不能访问!但是进入执行阶段之后,变量对象(VO)转变为了活动对象(AO),里面的属性都能被访问了,然后开始进行执行阶段的操作。
执行过程
代码的执行可以分为两个阶段:
- 代码分析(进入执行上下文)
- 代码执行
在代码分析时,VO 包含:
- 函数形参
- 函数声明(注意函数提升)
- 由名称和对应值(函数对象(function-object))组成一个变量对象的属性被创建
- 如果变量对象已经存在相同名称的属性,则完全替换这个属性
- 变量声明(注意变量提升,但这时候变量的值是undefined)
在代码执行阶段,会顺序执行代码,根据代码,修改变量对象的值
⚠️注意:
在进入执行上下文时,首先会处理函数声明,其次会处理变量声明,如果如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性。
console.log(foo);
function foo(){
console.log("foo");
}
var foo = 1;
// 打印结果为 foo 函数
作用域链
一句话描述:
由多个执行上下文的变量对象构成的链表就叫做作用域链
注意:作用域链是在代码执行前,初始化执行上下文的时候,最终确定的。他是根据当前可执行上下文中的AO,以及在编译过程中,为函数生成的[[scope]]属性,来最终确定的
当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做作用域链。
作用域链的创建和生成流程:
在源代码中当你定义(书写)一个函数的时候(并未调用),js引擎也能根据你函数书写的位置,函数嵌套的位置,给你生成一个[[scope]],作为该函数的属性存在(这个属性属于函数的)。即使函数不调用,所以说基于词法作用域(静态作用域)(可以理解 [[scope]] 就是所有父变量对象的层级链,但是注意:[[scope]]并不代表完整的作用域链,因为下面讲到,还有当前被执行函数的活动对象,即AO)。
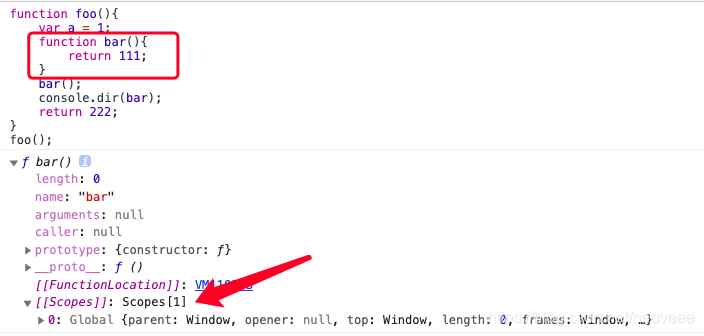
// 理解函数的[[scope]]属性
function foo() {
function bar() {
...
}
}
// 在函数创建后,各自的[[scope]]为
foo.[[scope]] = [
globalContext.VO
];
bar.[[scope]] = [
fooContext.AO,// 这里为什么是AO呢?
globalContext.VO
];
需要注意的是,bar中必须访问了foo中的某个变量,才会将foo的变量对象推入bar的作用域链中(这可能是V8引擎的优化)
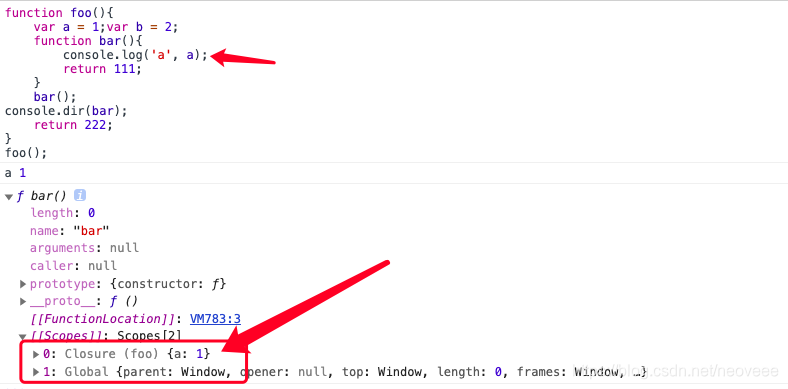
然后进入函数执行阶段,生成执行上下文,执行上下文你可以宏观的看成一个对象,(包含vo,scope,this),此时,执行上下文里的scope和之前属于函数的那个[[scope]]不是同一个,执行上下文里的scope,是在之前函数的[[scope]]的基础上,又新增一个当前的AO对象构成的。
函数定义时候的[[scope]]和函数执行时候的scope,前者作为函数的属性,后者作为函数执行上下文的属性。
this
- this指向调用者这个关系一定要清楚
- 要知道改变this指向的几种方式(call, bind, apply)
- 箭头函数中this的特殊性要能讲清楚
箭头函数中的this 在函数声明之后就被唯一确定了,不会随着函数的调用方式和所处的环境而改变,当执行箭头函数,初始化执行上下文的时候,js引擎会从声明该箭头函数的词法作用域中确定this的指向
闭包
闭包,在形式看是一个函数嵌套着一个函数,并且内部函数访问了外部函数的变量。当内部函数函数执行过程中,即使外部函数的执行上下文被销毁,但是被访问的这部分变量仍然会常驻内存,并且内部函数可以顺着自己的作用域链,访问到该变量。
MDN 对闭包的定义为:
闭包是指那些能够访问自由变量的函数。
那什么是自由变量呢?
自由变量是指在函数中使用的,但既不是函数参数也不是函数的局部变量的变量。
由此,我们可以看出闭包共有两部分组成:
闭包 = 函数 + 函数能够访问的自由变量
必刷题:
var data = [];
// 虽然函数内部访问了变量i,但是i存在于全局执行上下文的变量对象中,所以其实没有形成闭包的形式
for (var i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0]();//3
data[1]();//3
data[2]();//3
var data = [];
// let 创建了一个块作用域,可以查看babel编译后的代码,其实是形成了一种闭包:函数嵌套函数
for (let i = 0; i < 3; i++) {
data[i] = function () {
console.log(i);
};
}
data[0]();//0
data[1]();//1
data[2]();//2
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = (function (i) {
return function(){
console.log(i);
}
})(i);
}
data[0]();//0
data[1]();//1
data[2]();//2
new
function Person(name) {
this.name = name
}
const bob = new Person('bob')
// new调用构造函数的过程
1. 首先新建一个对象
2. 然后将对象的原型 bob.__proto__ 指向Person.prototype
3. 然后 Person.apply(obj)
4. 返回这个对象
JS创建对象的几种方式
- Object 构造函数
- 对象字面量
- 工厂函数
- 构造函数模式
- 原型模式()
- 组合模式
JS继承的几种方式
可以列举如下的几种方式 手写代码并说出各自的优缺点
- 原型链继承
- 借用构造函数继承(经典继承)
- 组合继承(原型链继承和经典继承双剑合璧)
- 原型式继承(Object.create)
- 寄生组合式继承(重要)
变量提升
Event Loop
JS中的任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务会在调用栈中按照顺序等待主线程依次执行,异步任务会在异步任务有了结果后,将注册的回调函数放入任务队列中等待主线程空闲的时候(调用栈被清空),被读取到栈内等待主线程的执行。这个过程是不断循环往复的,就形成了一种事件循环
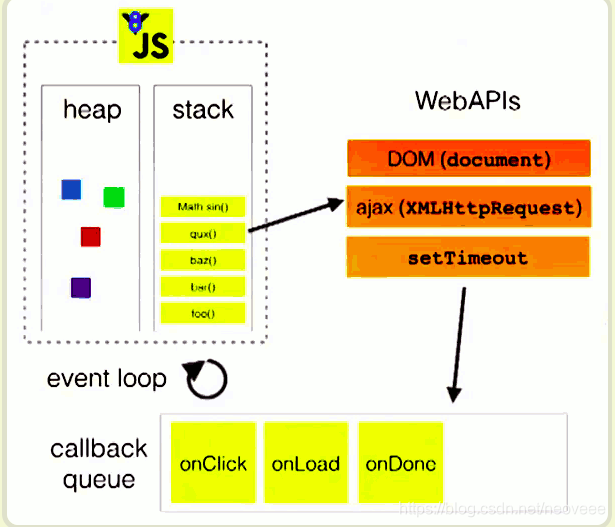
主线程运行的时候,产生堆(heap)和栈(stack),栈中的代码调用各种外部API,它们在"任务队列"中加入各种事件(click,load,done)(注意:为DOM注册的事件回调,在触发时,也是先要被推入任务队列,等等主线程空闲的时候读取 执行)。只要栈中的代码执行完毕,主线程就会去读取"任务队列",依次执行那些事件所对应的回调函数(这里其实还分为微任务队列和宏任务队列,下面会有提到)
任务队列
是一种先进先出的数据结构,排在前面的事件,优先被主线程读取。
- 微任务队列
- 宏任务队列
引申点:
- 微任务:Promise MutationObserver
- 宏任务: setTimeout、setInterval、setImmediate(浏览器暂时不支持,只有IE10支持,具体可见MDN)、I/O、UI Rendering
执行栈在执行完同步任务后,查看执行栈是否为空,如果执行栈为空,就会去检查微任务(microTask)队列是否为空,如果为空的话,就执行Task(宏任务),否则就一次性执行完所有微任务。
每次单个宏任务执行完毕后,检查微任务(microTask)队列是否为空,如果不为空的话,会按照先入先出的规则全部执行完微任务(microTask)后,设置微任务(microTask)队列为null,然后再执行宏任务,如此循环。
对于全部执行完微任务的潜在风险:

setTimeout(_ => console.log(4))
new Promise(resolve => {
resolve()
console.log(1)
}).then(_ => {
console.log(3)
})
console.log(2)
// 1 2 3 4
垃圾回收
两种方式(实现思路以及各自的优缺点)
- 引用计数垃圾收集
- 标记清除算法
Map & Set
参考资料:
- https://github.com/mqyqingfeng/Blog/issues/6

















 4444
4444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









