







广告位招租!
知识无价,人有情,无偿分享知识,希望本条信息对你有用!
本爬虫基于以下博文代码修改所得:
 https://blog.youkuaiyun.com/ncutyb123/article/details/139269693?spm=1001.2014.3001.5501
https://blog.youkuaiyun.com/ncutyb123/article/details/139269693?spm=1001.2014.3001.5501支持搜索词中包含空格以及中文搜索词
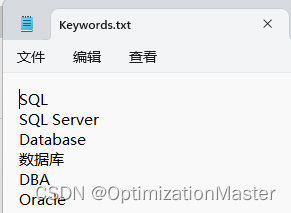
搜索词文件示例
可运行的Python爬虫代码
记得替换成你自己的检索词文件路径和文件名
# -*- coding: utf-8 -*-
import time
import requests
import execjs
import random
import pymysql
db_config = {
'host': '127.0.0.1',
'user': 'root',
'password': '12345678',
'database': 'work_data',
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
'''
def read_js_code():
f = open('/Users/shareit/workspace/chart_show/demo.js', encoding='utf-8')
txt = f.read()
js_code = exe 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











