



Apscheduler运行时提示到达最大实例导致程序异常
背景
做了个定时同步数据的任务,每隔10秒运行一次任务,部署后程序正常运行,但是某天发现程序停了,log提示:
skipped: maximum number of running instances reached (2)
思考
- 这种问题首先想到的当然是上网寻找解决办法,百度,G都试过了,方案无非就是把参数 max_instances 设置得大些,但是即使加到100,运行一段时间后,还是会出现这个错误,而且错误不是固定发生的,有时1天,有时几天才出现
scheduler.add_job(task_run, 'interval', id='data_sync', name='同步数据', seconds=10, max_instances=2, misfire_grace_time=30, replace_existing=True) - 项目使用Supervisor部署,所以考虑是否可以在程序报错的时候让程序自动重启?
解决办法
- 定位错误信息文字代码
- 当报exception后程序自动退出
- 利用Supervisor的autorestart参数设置当程序退出时自动重启程序
详细步骤
- 找到错误文字所在包:apscheduler\schedulers\base.py
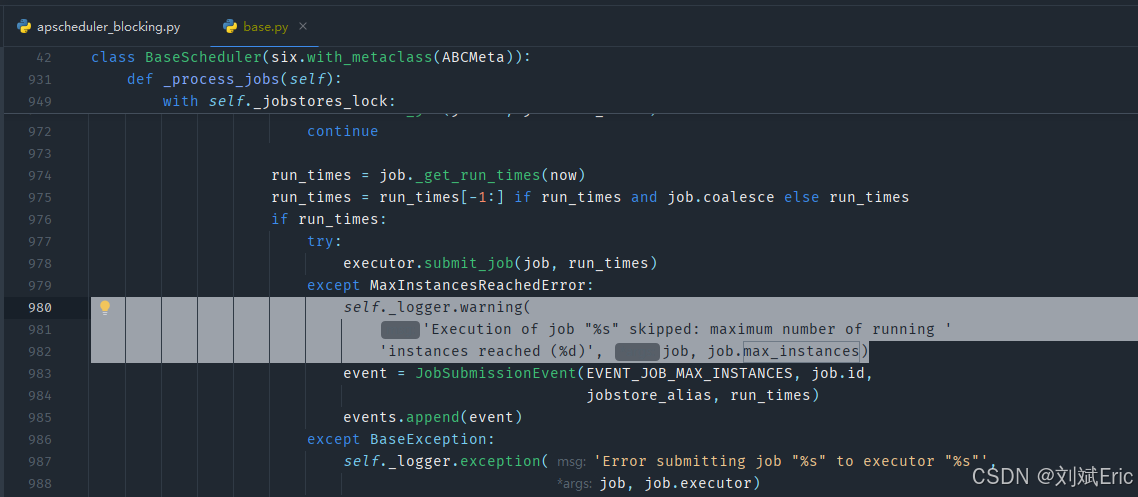
- 包文件不能直接做修改,只能在项目里继承和重写下该方法
- 在项目里新建文件MaximumBaseScheduler继承BaseScheduler类
- 把方法_process_jobs拷贝到MaximumBaseScheduler
- 在行982下面添加出错后退出程序
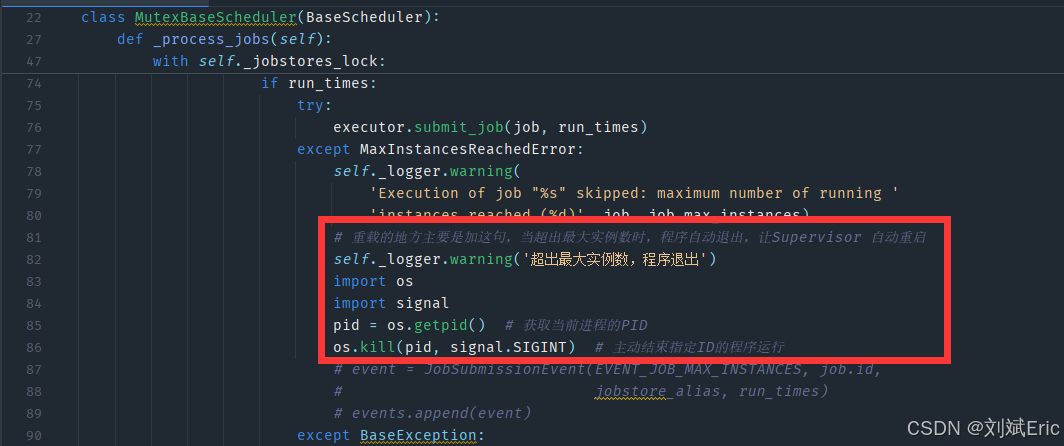
import os import signal pid = os.getpid() # 获取当前进程的PID os.kill(pid, signal.SIGINT) # 主动结束指定ID的程序运行 - debug的过程中试过使用os.exit()等退出,但是程序实际没有退出,使用kill可以让程序退出
- 另外Supervisor的配置里要把autorestart 设置为true,只要停止就重启应用
后续
经过两天的运行,发现程序还是会报错,然后停止(不会重启),思前想后,又找了个测试的Supervisor环境试了下,发现情况还是一样的,然后就继续寻找答案,可能出现在退出程序的代码放在里包里面,在跑实例的时候退出的是线程,而不是主程序,所以最后改动为在报错警告后加raise SystemError(0),然后在main方法再来加上程序退出的语句os._exit(0),测试环境终于在报错后,自动重启了,已经部署到生产环境,等下一次报错,看是否已经解决问题


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









