




-
简单符号说明:
h={h1⃗,h2⃗,…,hN⃗},hi⃗∈RF\boldsymbol h = \{\vec {h_1},\vec {h_2},\ldots,\vec{h_N}\},\vec {h_i} \in R^Fh={h1,h2,…,hN},hi∈RF 转换之前的节点特征矩阵,h⃗i\vec h_ihi是节点iii的特征向量
h′={h1′⃗,h2′⃗,…,hN′⃗},h⃗i∈RF′\boldsymbol h^{'} = \{\vec {h^{'}_1},\vec {h^{'}_2},\ldots,\vec {h^{'}_N}\},\vec h_i \in R^{F^{'}}h′={h1′,h2′,…,hN′},hi∈RF′ 转换之后的节点特征矩阵
W∈RF′×FW \in R^{F^{'} \times F}W∈RF′×F 层与层之间的转换矩阵
-
模型说明:
-
这篇文章提出的图注意力网络两点主要是根据中心节点其邻接点特征向量的取值来构建其对中心节点的影响程度,而不是像Kipf & Welling等人对邻接点统一对待。最后用于计算的邻接点也是一阶邻接点(直接相连)。
每一个邻接点对于中心点的影响程度可以用图注意力系数eije_{ij}eij表示,
eij=a(Whi⃗,Whj⃗) e_{ij} = a(\boldsymbol W\vec{h_i},\boldsymbol W\vec{h_j}) eij=a(Whi,Whj)
a是注意力计算函数,对于任意节点我们只计算j∈Ni,Nij \in \mathcal{N}_i,\mathcal{N}_ij∈Ni,Ni是节点iii的邻接点集合。在这篇文章中,图注意力机制是一个单层前馈神经网络。简单的抽象理解如下:
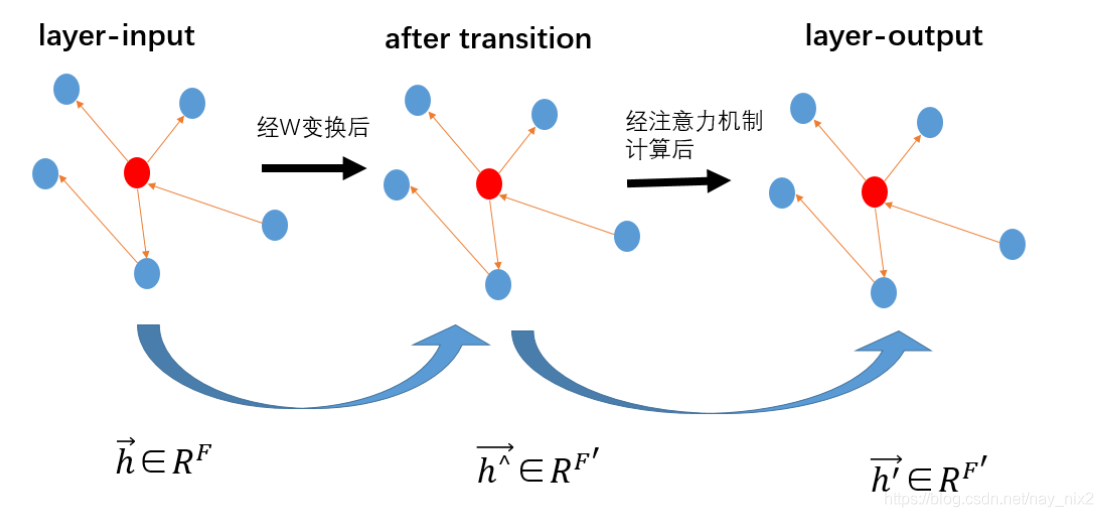
为了使不同节点之间的注意力系数可比较,使用softmax函数对注意力系数进行规范化。
αij=softmaxj(eij)=exp(eij)∑k∈Niexp(eik) \alpha_{ij} = softmax_j(e_{ij}) = \frac{exp(e_{ij})}{\sum_{k \in \mathcal{N}_i}exp(e_{ik})} αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)具体的注意力计算时,这篇文章主要使用a⃗∈R2F′\vec a \in R^{2F^{'}}a∈R2F′(用于注意力计算的权值参数),以及LeakyReLu函数, 注意力系数的具体表达式如下:
αij=exp(LeakyReLu(a⃗T[Whi⃗∣∣Whj⃗]))∑k∈Niexp(LeakyReLu(a⃗T[Whi⃗∣∣Whk⃗])) \alpha_{ij} = \frac{exp(LeakyReLu(\vec a ^T[\boldsymbol W\vec{h_i}||\boldsymbol W\vec{h_j}]))}{\sum_{k \in \mathcal{N}_i}exp(LeakyReLu(\vec a ^T[\boldsymbol W\vec{h_i}||\boldsymbol W\vec{h_k}]))} αij=∑k∈Niexp(LeakyReLu(aT[Whi∣∣Whk]))exp(LeakyReLu(aT[Whi∣∣Whj])) -
在聚合邻接点对中心节点的影响时,采用multi-head attention来聚合形成新的特征。
hi′⃗=∥k=1Kσ(∑j∈NiαijkWkhj⃗) \vec{h_i^{'}} = \|_{k=1}^{K}\sigma(\sum_{j \in \mathcal{N}_i}\alpha_{ij}^{k}\boldsymbol W^k \vec{h_j}) hi′=∥k=1Kσ(j∈Ni∑αijkWkhj)
注:经计算后,hi′∈RKF′h_i^{'} \in R^{KF^{'}}hi′∈RKF′最后一层(预测层)的聚合方式则采用取均值的方法进行,并延后使用激活函数
hi′⃗=σ(1K∑k=1K∑j∈NiαijkWkhj⃗) \vec{h_i^{'}} =\sigma(\frac{1}{K}\sum_{k=1}^{K}\sum_{j \in \mathcal{N}_i}\alpha_{ij}^{k}\boldsymbol W^k \vec{h_j}) hi′=σ(K1k=1∑Kj∈Ni∑αijkWkhj) -
模型过程:下面用来具体看一看每一层具体做了什么。
每一层的输出:
每一层的输出(不用于预测时):Hl+1=[H11l+1H12l+1⋯H1,KF′l+1⋮⋮⋱⋮HN1l+1HN2l+1⋯HN,KF′l+1]每一层的输出(用于预测时):Hl+1=[H11l+1H12l+1⋯H1F′l+1⋮⋮⋱⋮HN1l+1HN2l+1⋯HNF′l+1] 每一层的输出(不用于预测时):H^{l+1} = \begin{bmatrix} H^{l+1}_{11} & H^{l+1}_{12} & \cdots & H^{l+1}_{1,KF'}\\ \vdots & \vdots & \ddots & \vdots\\ H^{l+1}_{N1} & H^{l+1}_{N2} & \cdots & H^{l+1}_{N,KF'} \end{bmatrix} \\ \quad \\ 每一层的输出(用于预测时):H^{l+1} = \begin{bmatrix} H^{l+1}_{11} & H^{l+1}_{12} & \cdots & H^{l+1}_{1F'}\\ \vdots & \vdots & \ddots & \vdots\\ H^{l+1}_{N1} & H^{l+1}_{N2} & \cdots & H^{l+1}_{NF'} \end{bmatrix} 每一层的输出(不用于预测时):Hl+1=⎣⎢⎡H11l+1⋮HN1l+1H12l+1⋮HN2l+1⋯⋱⋯H1,KF′l+1⋮HN,KF′l+1⎦⎥⎤每一层的输出(用于预测时):Hl+1=⎣⎢⎡H11l+1⋮HN1l+1H12l+1⋮HN2l+1⋯⋱⋯H1F′l+1⋮HNF′l+1⎦⎥⎤
每一层的输入:
每一层的输入:Hl=[H11lH12l⋯H1Fl⋮⋮⋱⋮HN1lHN2l⋯HNFl] \\ \quad \\ 每一层的输入:H^{l} = \begin{bmatrix} H^{l}_{11} & H^{l}_{12} & \cdots & H^{l}_{1F}\\ \vdots & \vdots & \ddots & \vdots\\ H^{l}_{N1} & H^{l}_{N2} & \cdots & H^{l}_{NF} \end{bmatrix} 每一层的输入:Hl=⎣⎢⎡H11l⋮HN1lH12l⋮HN2l⋯⋱⋯H1Fl⋮HNFl⎦⎥⎤
神经网络在每一层需要训练的参数,其中转换权值矩阵是直接的网络参数,而注意力矩阵是由神经网络参数a⃗\vec aa计算而来。
转换权值矩阵:W=[W11W12⋯W1F′⋮⋮⋱⋮WF1WF2⋯WFF′]注意力矩阵:att=[att11att12⋯att1N⋮⋮⋱⋮attN1attN2⋯attNN] \\ \quad \\ 转换权值矩阵:W = \begin{bmatrix} W_{11} & W_{12} & \cdots & W_{1F^{'}}\\ \vdots & \vdots & \ddots & \vdots\\ W_{F1} & W_{F2} & \cdots & W_{FF^{'}} \end{bmatrix} \\ \quad \\ 注意力矩阵:att = \begin{bmatrix} att_{11} & att_{12} & \cdots & att_{1N}\\ \vdots & \vdots & \ddots & \vdots\\ att_{N1} & att_{N2} & \cdots & att_{NN} \end{bmatrix} 转换权值矩阵:W=⎣⎢⎡W11⋮WF1W12⋮WF2⋯⋱⋯W1F′⋮WFF′⎦⎥⎤注意力矩阵:att=⎣⎢⎡att11⋮attN1att12⋮attN2⋯⋱⋯att1N⋮attNN⎦⎥⎤
每一层首先做的事就是通过转换矩阵将特征维度从F−>F′F->F'F−>F′,之后再进行注意力计算,先由参数a⃗\vec aa计算任意两条边的注意力系数,根据邻接矩阵显示的节点关系得到最终的注意力系数矩阵,再通过注意力系数矩阵与维度为F’的矩阵相乘得到新的特征矩阵,大小仍为N×F′N \times F'N×F′。由于这篇文章采用的Multi-head attention策略,所以这样的网络有KKK层,可以分别得到KKK个N×F′N \times F'N×F′的特征矩阵。最后,如果是中间层,那么仅需要连接这KKK个矩阵形成N×KF′N \times KF'N×KF′的新特征矩阵,如果是最后一层,那么对这KKK个矩阵取均值仍然得到N×F′N \times F'N×F′的矩阵。
当K=3时H1′=Hl×W1,H2′=Hl×W2,H3′=Hl×W3H1l+1=att1×H1′,H2l+1=att2×H2′,H3l+1=att3×H3′当输出层不用于预测时,Hl+1=[H1l+1⋮H2l+1⋮H3l+1]当输出层用于预测时,Hl+1=1K∑i=1KHil+1 当K = 3时 \\ \quad \\ H^{'}_1 = H^l \times W_1 ,H^{'}_2 = H^l \times W_2 ,H^{'}_3 = H^l \times W_3 \\ \quad \\ H_1^{l+1} = att_1 \times H^{'}_1,H_2^{l+1} = att_2 \times H^{'}_2,H_3^{l+1} = att_3 \times H^{'}_3 \\ \quad \\ 当输出层不用于预测时,H^{l+1} = \begin{bmatrix}H_1^{l+1} \vdots H_2^{l+1} \vdots H_3^{l+1}\end{bmatrix} \\ \quad \\ 当输出层用于预测时,H^{l+1} = \frac{1}{K} \sum_{i=1}^K H_i^{l+1} 当K=3时H1′=Hl×W1,H2′=Hl×W2,H3′=Hl×W3H1l+1=att1×H1′,H2l+1=att2×H2′,H3l+1=att3×H3′当输出层不用于预测时,Hl+1=[H1l+1⋮H2l+1⋮H3l+1]当输出层用于预测时,Hl+1=K1i=1∑KHil+1图示说明如下:
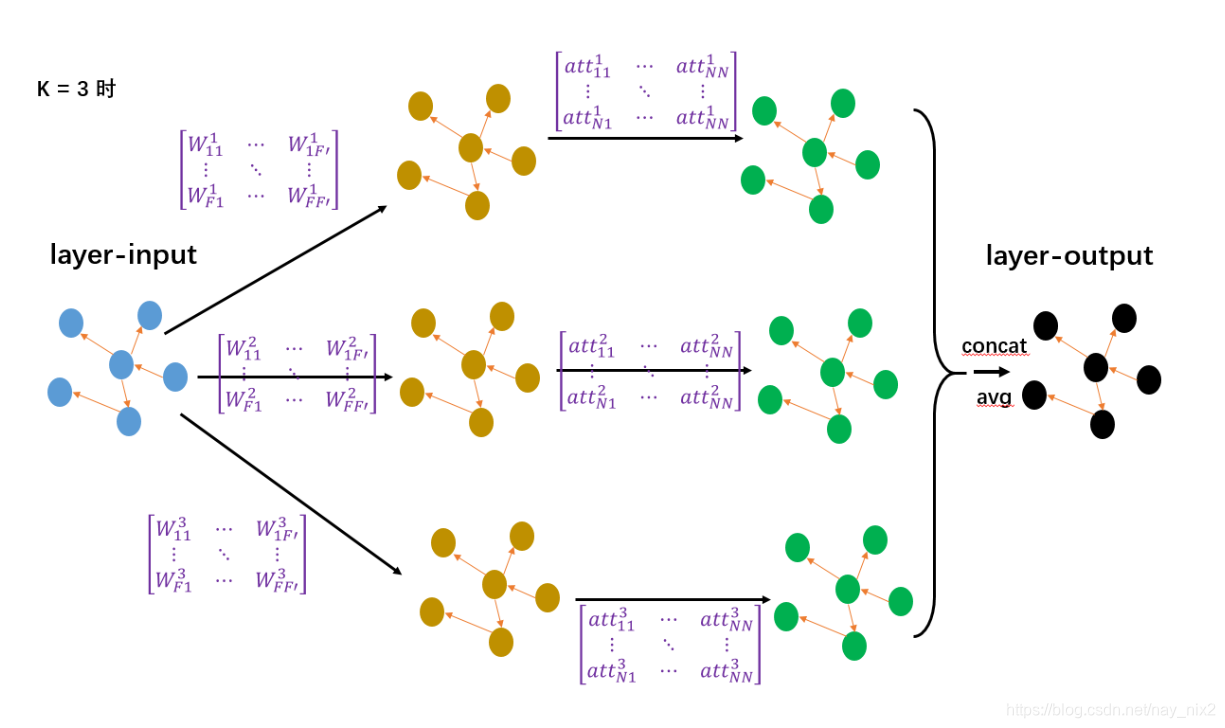
-
GRAPH ATTENTION NETWORKS论文笔记
最新推荐文章于 2025-11-02 21:30:47 发布

















 6221
6221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









