




 本文深入探讨了LeNet、AlexNet、Vgg、GoogleNet、Resnet、DenseNet等经典深度学习模型的架构特点与创新之处,分析了不同模型在卷积层、全连接层及特殊层的设计理念,揭示了深度学习网络从浅到深的发展历程。
本文深入探讨了LeNet、AlexNet、Vgg、GoogleNet、Resnet、DenseNet等经典深度学习模型的架构特点与创新之处,分析了不同模型在卷积层、全连接层及特殊层的设计理念,揭示了深度学习网络从浅到深的发展历程。
LeNet:
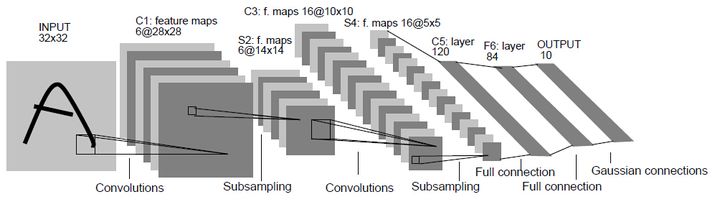

- 输入尺寸:32*32
- 卷积层:3个
- 降采样层:2个
- 全连接层:1个
- 输出层:10个类别(数字0-9的概率)
AlexNet:

1. 非线性激活函数:ReLU
2. 防止过拟合的方法:Dropout,Data augmentation
3. 大数据训练:百万级ImageNet图像数据
4. 其他:GPU实现,LRN归一化层的使用
Vgg:
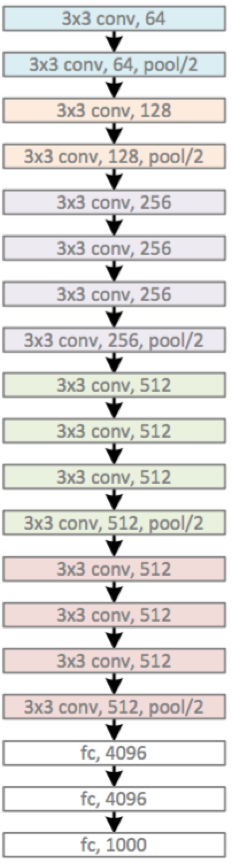

VGGNet探索了神经网络的深度与性能之间的关系,表明在结构相似的情况下,网络越深性能越好。
* 卷积核*
该模型中大量使用3*3的卷积核的串联,构造出16到19层的网络。
2个3*3的卷积核的串联相当于5*5的卷积核。
3个3*3的卷积核的串联相当于7*7的卷积核。
其意义在于7*7所需要的参数为49,3个3*3的卷积核参数为27个,几乎减少了一半。
GoogleNet:
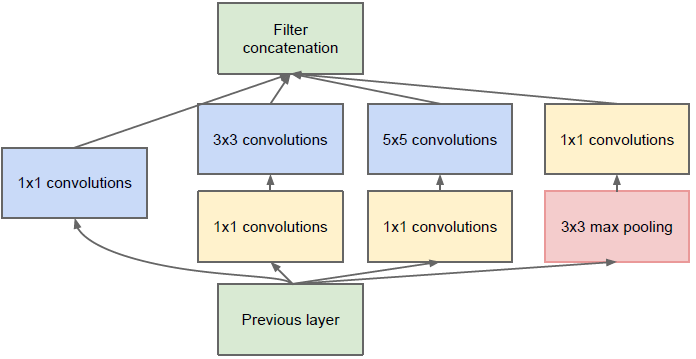
主要的创新在于他的Inception,这是一种网中网(Network In Network)的结构,即原来的结点也是一个网络。Inception一直在不断发展,目前已经V2、V3、V4了,感兴趣的同学可以查阅相关资料。Inception的结构如图9所示,其中1*1卷积主要用来降维,用了Inception之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
1. 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2. 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1后,只要分别设定pad=0、1、2,那么卷积后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了;
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
5. 使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。 例如:假定上一层的输出为100x100x128,经过具有256个5x5卷积核的卷积层处理之后(stride=1,pad=2),输出数据为100x100x256,其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个1x1卷积核的卷积层,再经过具有256个5x5卷积核的卷积层,那么最终的输出数据仍为为100x100x256,但卷积层参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
此外,该模型最后采用了average pooling来代替全连接层。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune。
Resnet: 其实这个model构成上更加简单,连LRN这样的layer都没有了。
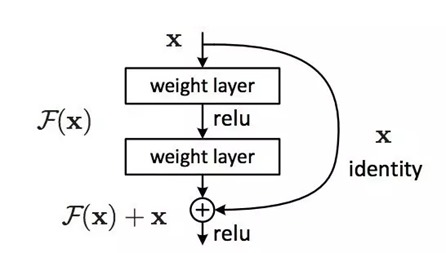
实际中,考虑计算的成本,对残差块做了计算优化:将两个3x3的卷积层替换为1x1 + 3x3 + 1x1, 如下图所示:

DenseNet:
(1) 相比ResNet拥有更少的参数数量.
(2) 旁路加强了特征的重用.
(3) 网络更易于训练,并具有一定的正则效果.
(4) 缓解了gradient vanishing和model degradation的问题.
下图是 DenseNet 的一个dense block示意图,一个block里面的结构如下,与ResNet中的BottleNeck基本一致:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3) ,而一个DenseNet则由多个这种block组成。每个DenseBlock的之间层称为transition layers,由BN−>Conv(1×1)−>averagePooling(2×2)组成
何恺明先生在提出ResNet时做出了这样的假设:若某一较深的网络多出另一较浅网络的若干层有能力学习到恒等映射,那么这一较深网络训练得到的模型性能一定不会弱于该浅层网络.通俗的说就是如果对某一网络中增添一些可以学到恒等映射的层组成新的网路,那么最差的结果也是新网络中的这些层在训练后成为恒等映射而不会影响原网络的性能.同样DenseNet在提出时也做过假设:与其多次学习冗余的特征,特征复用是一种更好的特征提取方式.

它的输出为:xl=Hl([X0,X1,…,xl−1]),其中[x0,x1,...,xl−1]就是将之前的feature map以通道的维度进行合并。
在同层深度下获得更好的收敛率,自然是有额外代价的。其代价之一,就是其恐怖如斯的内存占用。

在Denseblock中,假设每一个非线性变换H的输出为K个feature map, 那么第i层网络的输入便为K0+(i-1)×K。虽然DenseNet接受较少的k,也就是feature map的数量作为输出,但由于不同层feature map之间由cat操作组合在一起,最终仍然会是feature map的channel较大而成为网络的负担.作者在这里使用1×1 Conv(Bottleneck)作为特征降维的方法来降低channel数量,以提高计算效率. 无论多大的num_input_features 输出都会变为growth_rate(k)
BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features += num_layers*growth_rate
if i != len(block_config) - 1:
transition = _Transition(num_features, int(num_features*compression_rate))
self.features.add_module("transition%d" % (i + 1), transition)
num_features = int(num_features * compression_rate)class _DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)我们实现Transition层,它主要是一个卷积层和一个池化层:
class _Transition(nn.Sequential):
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))


















 6592
6592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









