



 本文探讨了梯度提升树中的关键概念,包括叶子节点数量、节点数值及其对预测误差的影响。通过对比不同回归树组合的表现,揭示了如何平衡模型复杂度以避免过拟合。此外,还介绍了贪心策略在节点分裂过程中的应用。
本文探讨了梯度提升树中的关键概念,包括叶子节点数量、节点数值及其对预测误差的影响。通过对比不同回归树组合的表现,揭示了如何平衡模型复杂度以避免过拟合。此外,还介绍了贪心策略在节点分裂过程中的应用。
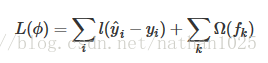
![]()
T表示叶子节点的个数,w表示节点的数值(这是回归树的东西,分类树对应的是类别)
直观上看,目标要求预测误差尽量小,叶子节点尽量少,节点数值尽量不极端(这个怎么看,如果某个样本label数值为4,那么第一个回归树预测3,第二个预测为1;另外一组回归树,一个预测2,一个预测2,那么倾向后一种,为什么呢?前一种情况,第一棵树学的太多,太接近4,也就意味着有较大的过拟合的风险)

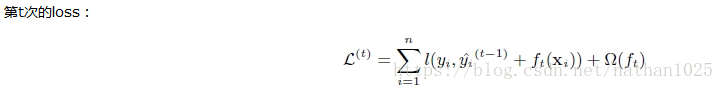
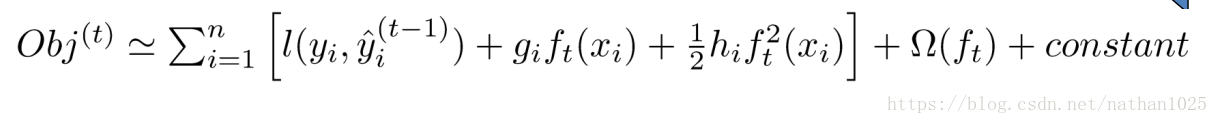
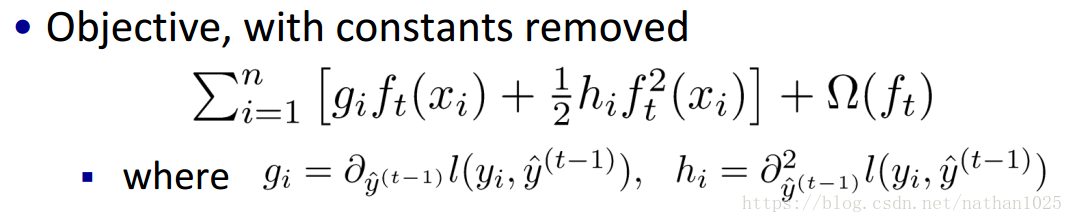

贪心策略+最优化
在分裂的时候,你可以注意到,每次节点分裂,loss function被影响的只有这个节点的样本,因而每次分裂,计算分裂的增益(loss function的降低量)只需要关注打算分裂的那个节点的样本。

贪心算法的过程:

总结:

https://blog.youkuaiyun.com/u013709270/article/details/78156207

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









