




 本文介绍了Oracle 19c的自动索引特性,它能根据应用程序工作负载变化自动创建、删除索引,提高数据库性能。文中阐述了自动索引的工作原理、限制,还说明了启动、禁用、配置方法,以及生成报告的方式,并通过案例展示了其对SQL执行效率的提升。
本文介绍了Oracle 19c的自动索引特性,它能根据应用程序工作负载变化自动创建、删除索引,提高数据库性能。文中阐述了自动索引的工作原理、限制,还说明了启动、禁用、配置方法,以及生成报告的方式,并通过案例展示了其对SQL执行效率的提升。
💫《博主介绍》:✨又是一天没白过,我是奈斯,从事IT领域✨
💫《擅长领域》:✌️擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了解✌️
💖💖💖大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注💖💖💖

经过一段时间的沉寂,今天给大家分享一下Oracle 19c版本中引入的一个革命性的新特性:自动索引。
自动索引,如其名,是为了简化Oracle数据库的索引管理而生的。自动索引会根据应用程序工作负载的变化自动创建、自动删除索引,从而提高数据库性能。
现在,想象一下这样一个场景:数据库不再需要你手动干预,它可以根据应用程序的工作负载变化,智能地创建、重建或删除索引。这不仅大大减轻了DBA的工作负担,更重要的是,它能够根据实际的数据访问模式,自动优化数据库的性能。
那么,自动索引是如何工作的呢?它又是如何帮助我们提高数据库的性能呢?别着急,接下来我会详细为大家解读这一强大的新功能。
特别说明💥:本篇文章部分理论性知识点均来源于版权归 Oracle 所有的官方公开文档手册,并结合了我个人的解读和案例演示。若需要调整,请联系,会尽快处理😄
官方文档对于自动索引的介绍(Oracle 19c):

One
Two
Three
开始今天的内容!!!

目录
(1)DBMS_AUTO_INDEX.REPORT_ACTIVITY:此函数返回数据库中特定时间段内执行的自动索引操作的报告。
(2)DBMS_AUTO_INDEX.REPORT_LAST_ACTIVITY:该函数返回数据库中最近一次执行的自动索引操作的报告。
自动索引介绍:
自动索引功能使Oracle数据库中的索引管理任务自动化。自动索引会根据应用程序工作负载的变化自动创建、自动删除索引,从而提高数据库性能。自动管理的索引称为自动索引。
索引结构是数据库性能的一个基本特征。 索引对于OLTP应用程序至关重要,因为OLTP应用程序会使用大量数据集,并且每天运行数百万条SQL语句。索引对于数据仓库应用程序也很重要,这些应用程序通常从非常大的表中查询相对较少的数据。如果在应用程序工作负载发生变化时不更新索引,现有索引可能会导致数据库性能大幅下降。
自动索引通过根据应用程序工作负载的变化自动、动态地管理Oracle数据库中的索引来提高数据库性能。自动索引提供了以下功能:
- 以预定义的时间间隔在后台定期运行自动索引过程。
- 分析应用程序工作负载,并相应地创建新索引和删除现有性能不佳的索引,以提高数据库性能。
- 重建由于表分区维护操作(如ALTER table MOVE)而标记为不可用的索引。
- 提供PL/SQL API,用于配置数据库中的自动索引并生成与自动索引操作相关的报告。
自动索引的限制:
- 自动索引只能是本地B树索引,不支持自动创建全局B树索引
- 可以为分区表和非分区表创建自动索引
- 无法为临时表创建自动索引
- 自动索引在内部使用SQL性能分析器框架来衡量SQL语句的性能。如果链接SQL可执行文件时明确排除了Real Application Testing,则自动索引将不起作用。如果向make命令提供RAT_OFF参数,则排除真实应用程序测试。明确排除真实应用程序测试并使用自动索引将产生错误:ORA-00438: Real Application Testing Option not installed.
自动索引工作原理:
自动索引进程每15分钟在后台运行一次,并执行以下操作:
1) 自动索引候选依赖于最新统计信息:
自动索引候选是根据SQL语句中表列的使用情况来识别的,确保表统计信息是最新的,没有统计数据的表不考虑自动索引,具有过时统计信息的表不考虑自动索引。
2) 候选索引不可见:
候选索引最初是不可见和不可用的,它们对应用程序工作负载不可见,应用程序工作负载中的SQL语句不能使用不可见的自动索引。自动索引可以是单列或多列的,它们被考虑用于以下情况:
- 表列(包括虚拟列)
- 分区表和非分区表
- 选定的表达式(例如:JSON表达式)
3) 候选索引验证,性能未提升保持不可见:
针对候选索引测试一个工作负载SQL语句示例。在此验证阶段,将构建一些或所有候选索引并使其有效,以便衡量对SQL语句的性能影响。在验证步骤中,所有候选索引都保持不可见状态。如果使用候选索引没有提高SQL语句的性能,它们将保持不可见。需要注意💥:数据库中首次运行的SQL语句不能使用自动索引,原因是Oracle无法对该SQL语句做出有效的判断。
4)有效索引可见,性能退化创建SQL计划基线:
被发现可提高SQL性能的候选有效索引将对应用程序工作负载可见和可用。不会提高SQL性能的候选索引将在短暂延迟后恢复为不可见且不可用。 在验证阶段,如果发现某个索引是有益的,但是某个SQL语句出现了性能退化,那么将创建一个SQL计划基线,以防止在索引可见时出现性能退化。
5)删除不可用和未使用的有效索引:
自动索引进程会删除不可用和未使用的有效索引
注意:默认情况下,未使用的自动索引将在373天后删除。在数据库中保留未使用的自动索引的时间段可以使用DBMS_AUTO_INDEX.CONFIGURE过程进行配置。
自动索引相关包介绍:
下面是DBMS_AUTO_INDEX包中定义的存储过程和函数,对于每个存储过程和函数中的参数,可以参考官方文档:DBMS_AUTO_INDEX
| 子程序 | 类型 | 描述 |
| DBMS_AUTO_INDEX.CONFIGURE | 存储过程 | 配置与自动索引相关的设置。 |
| DBMS_AUTO_INDEX.DROP_AUTO_INDEXES | 存储过程 | 此过程可用于手动删除自动创建的覆盖保留参数设置的索引。 |
| DBMS_AUTO_INDEX.DROP_SECONDARY_INDEXES | 存储过程 | 从架构或表中删除所有索引(用于约束的索引除外)。 |
| DBMS_AUTO_INDEX.REPORT_ACTIVITY | 存储函数 | 返回数据库中特定时段执行的自动索引操作的报告。 |
| DBMS_AUTO_INDEX.REPORT_LAST_ACTIVITY | 存储函数 | 返回数据库中上次执行的自动索引操作的报告。 |
自动索引相关视图:
SQL> select * from DBA_AUTO_INDEX_CONFIG; ###显示自动索引的当前配置参数设置。如果处于cdb模式,会列出当前pdb的配置,如果用sqlplus / as sysdba则会显示CDB$ROOT的配置。
SQL> select * from DBA_INDEXES where auto='YES'; ###表中的AUTO列是表示索引是否为自动索引,(YES)是或(NO)不.
自动索引相关参数:
SQL> alter system set "_exadata_feature_on"=true scope=spfile;
###19c版本中此功能仅限于企业版。通过设置初始化参数"_exadata_feature_on"=true开启自动索引功能(19c需要设置参数才能使用DBMS_AUTO_INDEX包,如果不开启在使用DBMS_AUTO_INDEX包时会报ORA-40216: feature not supported,并且需要重启实例生效)
一、启动、禁用、配置自动索引(默认是禁用的):
通过 DBMS_AUTO_INDEX.CONFIGURE 存储过程来启用、禁用、配置自动索引。
SQL> select * from DBA_AUTO_INDEX_CONFIG;
AUTO_INDEX_SCHEMA:要包含或排除使用自动索引的用户。
AUTO_INDEX_DEFAULT_TABLESPACE:用于存储自动索引的表空间。默认值是NULL,这意味着在创建数据库期间指定的默认永久表空间用于存储自动索引。
AUTO_INDEX_SPACE_BUDGET:空间大小用于自动索引的百分比
AUTO_INDEX_RETENTION_FOR_AUTO:在数据库中保留未使用的自动索引的天数,然后删除它们。默认值为373天。
AUTO_INDEX_RETENTION_FOR_MANUAL:在数据库中保留未使用的手动创建的索引(非自动索引)的天数,然后删除它们。当它被设置为NULL,自动索引过程不会删除手动创建的索引。默认值是NULL.。
AUTO_INDEX_MODE:自动索引的操作方式。
IMPLEMENT:在此模式下,新的自动索引创建为可见索引和任何现有的看不见自动索引也被设置为可见索引。在这种模式下,可以在SQL语句中使用自动索引。
REPORT ONLY:在此模式下,新的自动索引创建为看不见索引,不能在SQL语句中使用。
OFF:将模式设置为OFF防止考虑和创建新的自动索引。但是,它并不禁用现有的自动索引。
AUTO_INDEX_COMPRESSION:自动索引的高级索引压缩。默认值是OFF.
AUTO_INDEX_REPORT_RETENTION:在删除自动索引日志之前,在数据库中保留这些日志的天数。由于自动索引报告是根据这些日志生成的,因此不能在指定的值以外的时间内生成自动索引报告。AUTO_INDEX_REPORT_RETENTION。默认值为373天。
(1)库级别禁用:
###禁用(现有的自动索引仍然启用)
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_MODE','OFF');
(2)库级别启动:
默认情况下,如果启用了自动索引,那么数据库中的所有用户都可以使用自动索引。
###启用,并将任何新的自动索引创建为可见索引,以便它们可以在SQL语句中使用
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_MODE','IMPLEMENT');
###启用,但将任何新的自动索引创建为看不见索引,因此它们不能在SQL语句中使用
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_MODE','REPORT ONLY');
(3)用户级别:
###将SH用户添加到排除列表中,这样SH用户就不能使用自动索引
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_SCHEMA', 'SH', FALSE);
###从排除列表中删除HR用户,以便HR用户可以使用自动索引
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_SCHEMA', 'HR', NULL);
###从排除列表中删除所有用户,以便数据库中的所有用户都可以使用自动索引
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_SCHEMA', NULL, TRUE);
(4)指定未使用的自动索引的保留时间:
使用AUTO_INDEX_RETENTION_FOR_AUTO配置设置来指定在数据库中保留未使用的自动索引的保留时间。未使用的自动索引会在指定的保留时间后被删除。默认情况下,未使用的自动索引在373天后被删除。
###未使用的自动索引的保留期设置为90天。
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_RETENTION_FOR_AUTO', '90');
###未使用的自动索引的保留期重置为373天的默认值
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_RETENTION_FOR_AUTO', NULL);
(5)指定未使用的非自动索引(手动创建的索引)的保留时间:
使用AUTO _ INDEX _ RETENTION _ FOR _ MANUAL配置设置来指定在数据库中保留未使用的非自动索引(手动创建的索引)的保留时间。未使用的非自动索引将在指定的保留时间后被删除。默认情况下,自动索引进程不会删除未使用的非自动索引(手动创建的索引)。
###未使用的非自动索引(手动创建的索引)的保留期设置为60天
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_RETENTION_FOR_MANUAL', '60');
###未使用的非自动索引(手动创建的索引)的保留期设置为NULL,这样它们就不会被自动索引进程删除
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_RETENTION_FOR_MANUAL', NULL);
(6)指定自动化索引日志的保留时间
使用AUTO_INDEX_REPORT_RETENTION配置设置来指定在数据库中保留自动索引日志的保留时间。自动索引日志在指定的保留时间后被删除。默认情况下,自动索引日志在373天后被删除。并且自动索引报告是基于自动索引日志生成。因此,生成自动索引报告的时间段不能超过使用AUTO_INDEX_REPORT_RETENTION配置设置指定的自动索引日志的保留期。
###将自动索引日志的保留期设置为60天
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_REPORT_RETENTION', '60');
###将自动索引日志的保留期重置为默认值373天
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_REPORT_RETENTION', NULL);
PS补充💥:还有剩下关于指定存储自动索引的表空间、指定要为自动索引分配的表空间百分比、为自动索引配置高级索引压缩的案例参考官方文档即可。
二、生成自动索引报告
使用DBMS_AUTO_INDEX包的REPORT_ACTIVITY和REPORT_LAST_ACTIVITY函数生成与Oracle数据库中的自动索引操作相关的报告。
(1)DBMS_AUTO_INDEX.REPORT_ACTIVITY:此函数返回数据库中特定时间段内执行的自动索引操作的报告。
语法:
DBMS_AUTO_INDEX.REPORT_ACTIVITY ( activity_start IN TIMESTAMP WITH TIME ZONE DEFAULT SYSTIMESTAMP - 1, activity_end IN TIMESTAMP WITH TIME ZONE DEFAULT SYSTIMESTAMP, type IN VARCHAR2 DEFAULT 'TEXT', section IN VARCHAR2 DEFAULT 'ALL', level IN VARCHAR2 DEFAULT 'TYPICAL') RETURN CLOB;
参数 描述 activity_start 从报告考虑执行自动索引操作开始的时间。如果指定了NULL,则报告将考虑上次执行的自动索引操作。如果没有为此参数指定值,则在开始时间考虑当前时间减去一天(24小时)。 activity_end 报告考虑执行自动索引操作的时间。如果没有指定值,则当前时间被视为结束时间。 type 报告的格式。它可以具有以下值之一:
- 文本
- HTML
- XML
默认值为TEXT。
section 报告中应包含的章节。它可以包含以下值的组合:
- SUMMARY:仅在报告中包含摘要详细信息部分。
- INDEX_DETAILS:仅在报告中包含自动索引详细信息部分。
- VERIFICATION_DETAILS:仅在报告中包含自动索引验证详细信息部分。
- ERRORS:仅在报告中包含错误详细信息部分。
- ALL:在报告中包括所有部分(摘要详细信息、自动索引详细信息、自动化索引验证详细信息和错误详细信息),默认值。
level 报告中要包含的自动索引信息级别。它可以具有以下值之一:
- BASIC:在报告中包含基本的自动索引信息。
- TYPICAL:在报告中包含典型的自动索引信息。这是默认值。
- ALL:在报告中包含所有自动索引信息。
示例一:使用默认配置生成报告(默认是过去24小时自动索引操作的信息,以纯文本格式text生成)
SQL> declare report clob := null; begin report := DBMS_AUTO_INDEX.REPORT_ACTIVITY(); end; / SQL> SELECT DBMS_AUTO_INDEX.report_activity( type => 'HTML') ###可以是html、text、xml。默认值是text FROM dual; ###查看默认24小时文本格式的HTML报告
示例二:指定时间间隔、报告类型、级别、内容生成报告
SQL> declare report clob := null; begin report := DBMS_AUTO_INDEX.REPORT_ACTIVITY( activity_start => TO_TIMESTAMP('2018-11-01', 'YYYY-MM-DD'), ###开始时间 activity_end => TO_TIMESTAMP('2018-12-01', 'YYYY-MM-DD'), ###结束时间 type => 'HTML', ###报告类型,默认值是TEXT section => 'SUMMARY', ###报告内容 level => 'BASIC'); ###报告级别 end; / SQL> SELECT DBMS_AUTO_INDEX.report_activity( activity_start => SYSTIMESTAMP-2, activity_end => SYSTIMESTAMP-1, type => 'HTML') ###可以是html、text、xml。默认值是text FROM dual; ###查看前一天的THML格式的报告
(2)DBMS_AUTO_INDEX.REPORT_LAST_ACTIVITY:该函数返回数据库中最近一次执行的自动索引操作的报告。
语法:
DBMS_AUTO_INDEX.REPORT_LAST_ACTIVITY ( type IN VARCHAR2 DEFAULT 'TEXT', section IN VARCHAR2 DEFAULT 'ALL', level IN VARCHAR2 DEFAULT 'TYPICAL') RETURN CLOB;
参数 描述 type 报告的格式。它可以具有以下值之一:
- 文本
- HTML
- XML
默认值为TEXT。
section 报告中应包含的章节。它可以包含以下值的组合:
- SUMMARY:仅在报告中包含摘要详细信息部分。
- INDEX_DETAILS:仅在报告中包含自动索引详细信息部分。
- VERIFICATION_DETAILS:仅在报告中包含自动索引验证详细信息部分。
- ERRORS:仅在报告中包含错误详细信息部分。
- ALL:在报告中包括所有部分(摘要详细信息、自动索引详细信息、自动化索引验证详细信息和错误详细信息)。这是默认值。
level 报告中要包含的自动索引信息级别。它可以具有以下值之一:
- BASIC:在报告中包含基本的自动索引信息。
- TYPICAL:在报告中包含典型的自动索引信息。这是默认值。
- ALL:在报告中包含所有自动索引信息。
示例一:使用默认配置生成报告(默认生成上一次自动索引操作的报告 )
SQL> declare report clob := null; begin report := DBMS_AUTO_INDEX.REPORT_LAST_ACTIVITY(); end; / SQL> SELECT DBMS_AUTO_INDEX.report_last_activity( type => 'HTML') ###可以是html、text、xml。默认值是text FROM dual; ###查看最后一次自动索引操作的HTML报告
示例二:指定自动索引操作的摘要、索引详细信息和错误信息,报告以HTML格式生成。
SQL> declare report clob := null; begin report := DBMS_AUTO_INDEX.REPORT_LAST_ACTIVITY( type => 'HTML', section => 'SUMMARY +INDEX_DETAILS +ERRORS', level => 'BASIC'); end; / SQL> SELECT DBMS_AUTO_INDEX.report_last_activity( type => 'HTML', ###可以是html、text、xml。默认值是text section => 'ALL', "LEVEL" => 'ALL') FROM dual; ###查看最后一次自动索引的html报告
案例开始:库级别开启自动索引(Oracle 19c环境)
(1)开启自动索引相关参数(19c需要设置参数才能使用DBMS_AUTO_INDEX包,如果不开启在使用DBMS_AUTO_INDEX包时会报ORA-40216: feature not supported,并且需要重启实例生效)
###19c版本中此功能仅限于企业版。通过设置初始化参数"_exadata_feature_on"=true开启自动索引功能
SQL> alter system set "_exadata_feature_on"=true scope=spfile;
SQL> shutdown immediate
SQL> startup
SQL> show parameter "_exadata_feature_on"(2)开启库级别的自动索引
[oracle@oracle19c ~]$ sqlplus / as sysdba
###启用,并将任何新的自动索引创建为可见索引,以便它们可以在SQL语句中使用。默认情况下,如果启用了自动索引,那么数据库中的所有用户都可以使用自动索引。
SQL> EXEC DBMS_AUTO_INDEX.CONFIGURE('AUTO_INDEX_MODE','IMPLEMENT'); (3)查看库中是否有自动索引和自动索引的配置
SQL> select * from DBA_AUTO_INDEX_CONFIG; ###显示自动索引的当前配置参数设置。如果处于cdb模式,会列出当前pdb的配置,如果用sqlplus / as sysdba则会显示CDB$ROOT的配置。
SQL> select * from DBA_INDEXES where auto='YES'; ###表中的AUTO列是表示索引是否为自动索引,(YES)是或(NO)不.


(4)模拟两张表的关联查询
数据库中首次运行的SQL语句不能使用自动索引,原因是Oracle无法对该SQL语句做出有效的判断。所以需要多执行几次
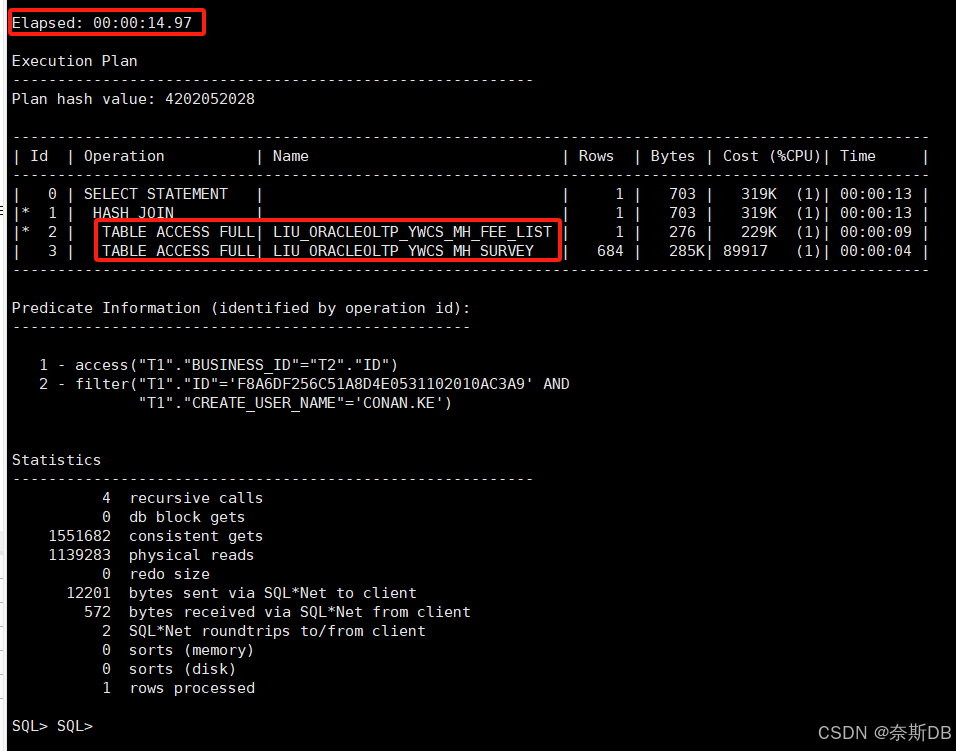
SQL> select * from LIU_ORACLEOLTP_YWCS_MH_FEE_LIST t1 inner join LIU_ORACLEOLTP_YWCS_MH_SURVEY t2 on t1.BUSINESS_ID = t2.ID where t1.create_user_name = 'CONAN.KE' and t1.id='F8A6DF256C51A8D4E0531102010AC3A9';可以看到SQL查询耗时14秒
SQL语句的执行计划和统计信息分析
Execution Plan为执行计划部分:执行计划部分列出了相关SQL语句每步的具体情况和消耗,包括访问路径、扫描情况、扫描行数、使用字节数、使用临时空间字节数,以及每个步骤的成本和时间估计
1)通过执行计划可以看到,两个表都进行了全表扫描
Predicate Information (identified by operation id)为谓词信息部分:谓词信息部分列出了执行计划部分where过滤条件或者join连接条件的信息,其实也就是where过滤条件或者join连接条件都会在谓词信息中,where过滤条件或者join连接条件对于查询性能最重要,通过谓词信息部分考虑是否可以通过添加或修改索引来提高过滤操作的效率。
列出了执行计划部分where过滤条件或者join连接条件的信息,一共有两种:access表示使用索引作为过滤条件,那么filter表示没有使用索引作为过滤条件
1)可以看到t1.create_user_name = 'CONAN.KE' and t1.id='F8A6DF256C51A8D4E0531102010AC3A9'条件没有走索引
(5)多执行了几次SQL后,通过视图查看,为执行的SQL创建了合适的自动索引
SQL> select * from dba_indexes where auto='YES'; ###表中的AUTO列是表示索引是否为自动索引,(YES)是或(NO)不.
创建的自动索引如下:
1、SYS_AI_33ggv6cn5xvn9索引为LIU_ORACLEOLTP_YWCS_MH_FEE_LIST表的组合索引,索引在CREATE_USER_NAME, ID列
2、SYS_AI_czr0cy119whsv索引为LIU_ORACLEOLTP_YWCS_MH_FEE_LIST表的单列索引,索引在BUSINESS_ID列
3、SYS_AI_f9dkdf6adm80t索引为LIU_ORACLEOLTP_YWCS_MH_SURVEY表的单列索引,索引在ID列
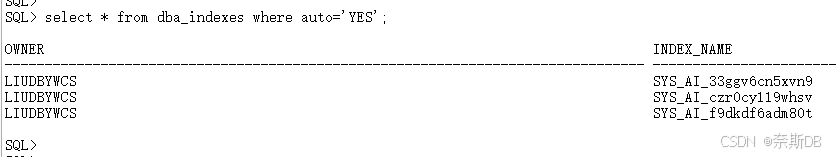
(6)再次执行两表的管理查询
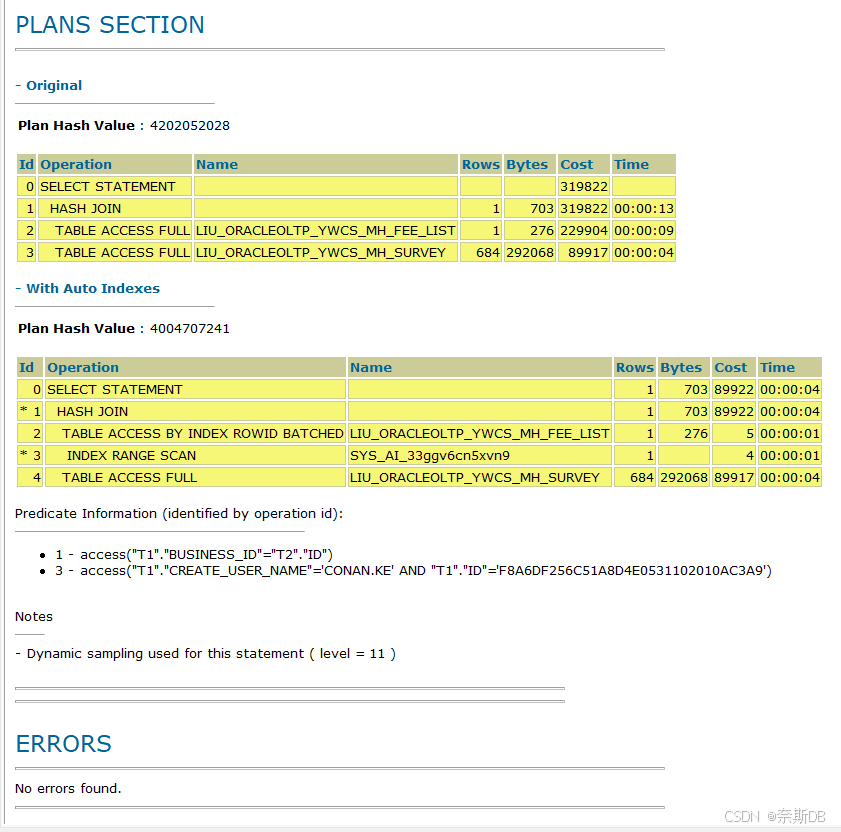
SQL> select * from LIU_ORACLEOLTP_YWCS_MH_FEE_LIST t1 inner join LIU_ORACLEOLTP_YWCS_MH_SURVEY t2 on t1.BUSINESS_ID = t2.ID where t1.create_user_name = 'CONAN.KE' and t1.id='F8A6DF256C51A8D4E0531102010AC3A9';可以看到SQL查询耗时3秒,比之前快了11秒
SQL语句的执行计划和统计信息分析
Execution Plan为执行计划部分:执行计划部分列出了相关SQL语句每步的具体情况和消耗,包括访问路径、扫描情况、扫描行数、使用字节数、使用临时空间字节数,以及每个步骤的成本和时间估计
1)通过执行计划可以看到,LIU_ORACLEOLTP_YWCS_MH_FEE_LIST表引用了自动创建的索引SYS_AI_33ggv6cn5xvn9
Predicate Information (identified by operation id)为谓词信息部分:谓词信息部分列出了执行计划部分where过滤条件或者join连接条件的信息,其实也就是where过滤条件或者join连接条件都会在谓词信息中,where过滤条件或者join连接条件对于查询性能最重要,通过谓词信息部分考虑是否可以通过添加或修改索引来提高过滤操作的效率。
列出了执行计划部分where过滤条件或者join连接条件的信息,一共有两种:access表示使用索引作为过滤条件,那么filter表示没有使用索引作为过滤条件
1)可以看到t1.create_user_name = 'CONAN.KE' and t1.id='F8A6DF256C51A8D4E0531102010AC3A9'条件使用了索引
(7)生成自动索引报告。使用默认配置生成报告(默认是过去24小时自动索引操作的信息,以纯文本格式text生成)
SQL> declare report clob := null; begin report := DBMS_AUTO_INDEX.REPORT_ACTIVITY(); end; / SQL> SELECT DBMS_AUTO_INDEX.report_activity( type => 'HTML') ###可以是html、text、xml。默认值是text FROM dual; ###查看默认24小时文本格式的HTML报告分析生成的报告:
通过创建的自动索引,SQL的执行计划由全表扫描,进一步优化为索引范围扫描,使得SQL耗时变短,提高了SQL执行效率
(8)删除自动索引(19c版本中不能手动删除自动索引)
SQL> drop index SYS_AI_33ggv6cn5xvn9; ###自动创建的自动索引不能被删除掉。只能等到参数AUTO_INDEX_RETENTION_FOR_AUTO设置的时间到了之后,未使用的自动索引在指定的保留期后被删除。默认情况下,373天后将删除未使用的自动索引。

好了今天的内容就到这里,相信大家自动索引已经有初步了解了,对于高阶内容有兴趣的兄弟可以私下去学习官方文档。对于自动索引,目前我自己还没有遇到过生产环境开的,因为 对于大表来说创建索引会耗时很长,并且是非常消耗性能的,所以都是建议业务低峰期对大表加索引 。对于自动索引有没有考虑到业务低/高峰期,在业务高峰期就对大表加索引这点,还需要再研究研究😗。



















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











