








p676 回顾昨天内容
Collection有一个父接口叫Iterable,这个父接口中有一个方法叫iterator,Collection调用这个父接口返回了一个迭代器对象iterator。这个iterator对象有三个方法,hasNext().Next(),remove()方法。
HashSet是一个特殊的HashMap。操作Set集合的时候在底层都会创建一个Map集合。
Map集合没有迭代器,他是通过k部分进行遍历的
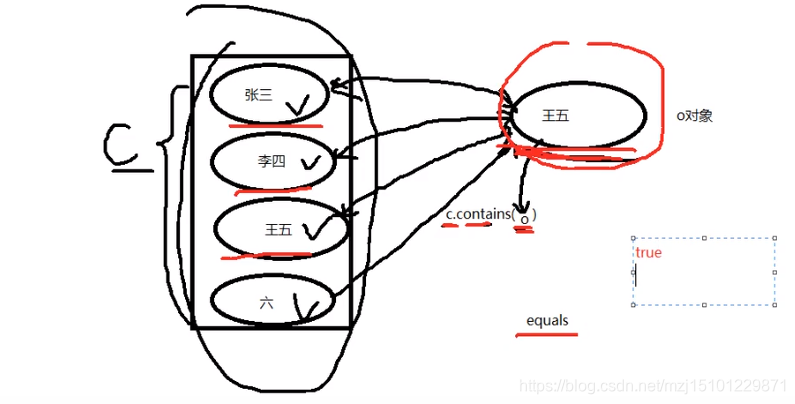
contains方法会调用集合里面对象的equals方法去比较。 但是需要重写equals方法,如果不重写的话会默认调用Object下的equals方法,比较对象的内存地址。remove和contain方法都会调用equals方法。
hasNext方法返回的是Object对象。
p677 关于集合的remove方法
集合一旦发生改变,迭代器必须重新获取。否则会发生异常
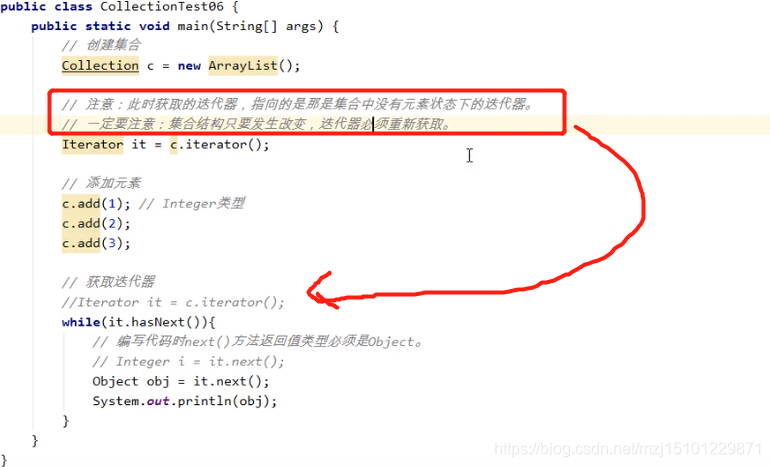
在迭代集合元素的过程中,不能改变集合的结构。所以下面的remove方法不能写在while循环中。

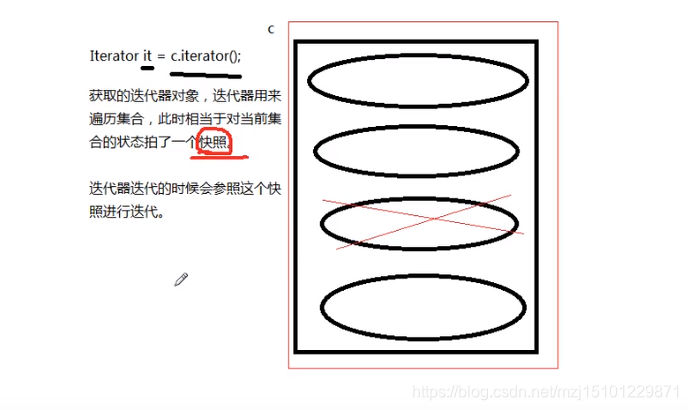
获取迭代器的时候就是相当于给集合拍了一个照片,然后按照这个快照去迭代,如果迭代过程中改变了集合,那么和原来的快照就不一样了,就会出问题。
删除的时候要使用迭代器iteartor去删除,这样就会保证快照和集合对应,不会出问题。
删除的时候要采用迭代器去删除,不能用集合去删。


——————————————————————————————Collection模块结束
p678 List接口特有方法1

package com.bjpowernode.day24.Collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListTest01 {
public static void main(String[] args) {
List mylist = new ArrayList();
//添加元素。默认都是在集合末尾添加元素
mylist.add("A");
mylist.add("B");
mylist.add("C");
mylist.add("D");
//使用List特有方法进行添加元素,但是此方法效率较低(移动元素太多),使用较少。
mylist.add(1,"KING");//在指定下标位置添加元素
//迭代
Iterator it = mylist.iterator();
while(it.hasNext()){
Object o = it.next();
System.out.println(o);
}
}
}
p679 List接口特有方法2

package com.bjpowernode.day24.Collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListTest01 {
public static void main(String[] args) {
List mylist = new ArrayList();
//添加元素。默认都是在集合末尾添加元素
mylist.add("A");
mylist.add("B");
mylist.add("C");
mylist.add("D");
//使用List特有方法进行添加元素,但是此方法效率较低(移动元素太多),使用较少。
mylist.add(1,"KING");//在指定下标位置添加元素
mylist.add("KING");
//迭代
Iterator it = mylist.iterator();
while(it.hasNext()){
Object o = it.next();
System.out.println(o);
}
//根据下标获取元素
Object firstObj = mylist.get(0);
System.out.println(firstObj);
System.out.println("============================");
//通过下标遍历,List集合特有的方法,Set没有
for (int i = 0; i < mylist.size(); i++) {
Object obj = mylist.get(i);
System.out.println(obj);
}
//int indexOf(Object o)
//获取指定对象第一次出现的下标(索引)
System.out.println(mylist.indexOf("C"));
//int lastIndexOf(Object o)
//获取指定对象第一次出现的下标(索引)
System.out.println(mylist.lastIndexOf("KING"));
System.out.println("============================");
//remove,删除指定下标元素
mylist.remove(3);//删除c
System.out.println(mylist.size());
for (int i = 0; i < mylist.size(); i++) {
Object obj = mylist.get(i);
System.out.println(obj);
}
//修改指定位置元素
mylist.set(2,"QUEEN");
System.out.println(mylist.get(2));
}
}
p680 ArrayList集合初始化容量以及扩容


p681 二进制位运算
10 >>1 [表示是操作二进制,10的二进制是1010,右移1位就是101,也就是5.]
其实左移就是乘2,右移就是除2

p682 ArrayList的另一个构造方法【将HashSet集合转换为List集合】。
package com.bjpowernode.day24.Collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.List;
public class ArrayListTest02 {
public static void main(String[] args) {
//初始化数组,默认数组容量为10
List list1 = new ArrayList();
//指定数组容量
List list2 = new ArrayList(100);
//创建HashSet集合
Collection c = new HashSet();
//往HashSet中添加元素
c.add(100);
c.add(27);
c.add("hello");
c.add(3.14);
//将HashSet集合转换为List集合
//创建List集合时,将HashSet作为参数传进去。
List list3 = new ArrayList(c);
for (int i = 0; i < list3.size(); i++) {
System.out.println(list3.get(i));
}
}
}
p683 为什么数组最后添加元素效率高?
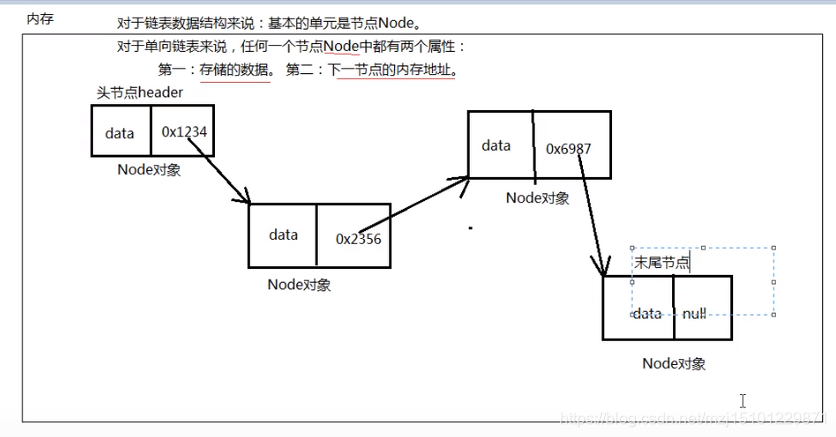
p684 单链表数据结构,使用代码来帮助理解
Link
package com.bjpowernode.day24.singleLink;
public class Link {
//头节点
Node header = null;
//定义方法
//添加元素
public void add(Object obj) {
}
//删除元素
public void delete(Object obj) {
}
//修改数据
public void modify(Object newobj) {
}
//查找元素
public int find(Object obj) {
return 1;
}
}
Node
package com.bjpowernode.day24.singleLink;
/**
* 单链表中的节点
* 节点是单链表的基本单元
* 每一个节点都有两个属性
* 1、存储的数据
* 2、下一个节点的内存地址
*
*/
public class Node {
//存储的数据
Object element;
//下一个节点,还是Node类型
Node next;
//构造方法
public Node() {
}
public Node(Object element, Node next) {
this.element = element;
this.next = next;
}
}
Link
package com.bjpowernode.day24.singleLink;
public class Link {
//头节点
Node header = null;
//获取size
int size = 0;
public int getSize() {
return size;
}
//定义方法
//添加元素(向末尾添加)
public void add(Object data) {
//创建一个新的节点对象
//让之前链表的末尾节点指向新节点对象
//有可能这个元素是第一个,有可能是第二个,也有可能是第三个。需要判断
if (header== null){
//说明还没有节点,因为头节点为空
//需要new一个新的节点作为头节点
//此时的头节点既头节点,又是末尾节点
header = new Node(data, null);
}else{
//说明存在头节点了,找出末尾节点让当前末尾节点的next指向新节点
Node currentLastNode = findLast(header);
currentLastNode.next = new Node(data,null);
}
size++;
}
//专门用来找末尾节点的方法
//使用递归实现
private Node findLast(Node node) {
if (node.next == null){
return node;
}
//程序执行到这里,说明node不是末尾节点,所以把node的下一个节点传进去继续寻找
return findLast(node.next);
}
//删除元素
public void delete(Object obj) {
}
//修改数据
public void modify(Object newobj) {
}
//查找元素
public int find(Object obj) {
return 1;
}
}
Node
package com.bjpowernode.day24.singleLink;
/**
* 单链表中的节点
* 节点是单链表的基本单元
* 每一个节点都有两个属性
* 1、存储的数据
* 2、下一个节点的内存地址
*
*/
public class Node {
//存储的数据
Object data;
//下一个节点,还是Node类型
Node next;
//构造方法
public Node() {
}
public Node(Object element, Node next) {
this.data = element;
this.next = next;
}
}
Test
package com.bjpowernode.day24.singleLink;
public class Test {
public static void main(String[] args) {
Link link = new Link();
link.add(100);
link.add(200);
link.add(300);
System.out.println(link.getSize());
}
}
p685 链表的优缺点


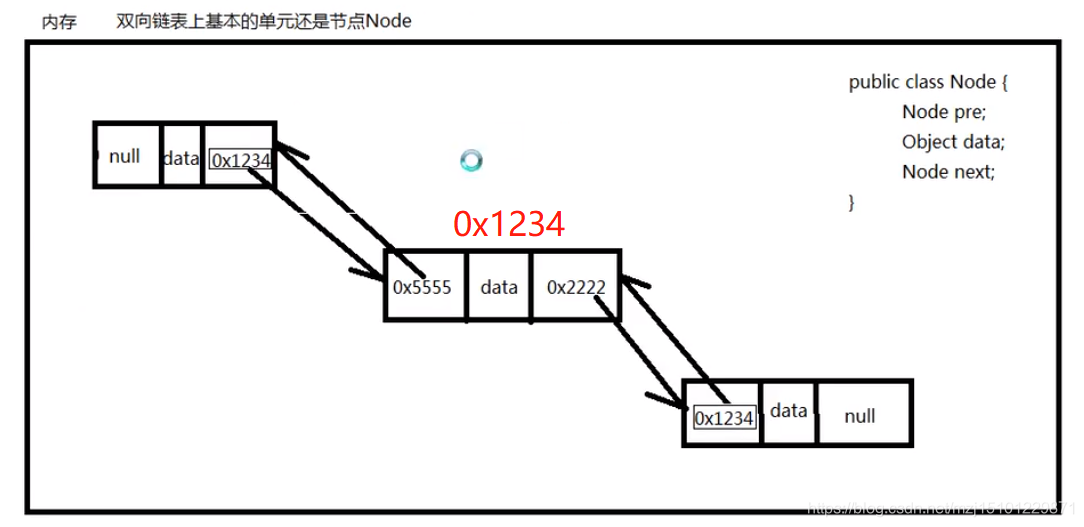
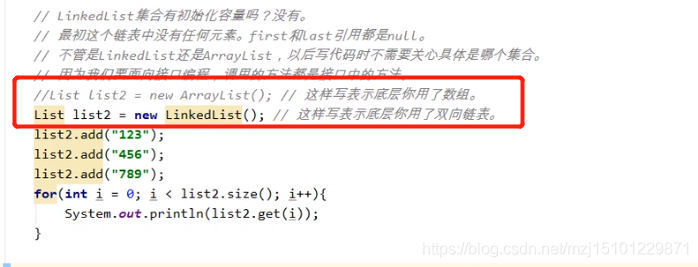
p686 LinkedList链表源码分析
p687 总结LinkedList
最常用的是ArrayList。
LinkedList集合底层是双向链表
p688 Vector
Vector:
1、底层也是一个数组。
2、初始化容量:10
3、怎么扩容的?
扩容之后是原容量的2倍。
10--> 20 --> 40 --> 80
4、ArrayList集合扩容特点:
ArrayList集合扩容是原容量1.5倍。
5、Vector中所有的方法都是线程同步的,都带有synchronized关键字,
是线程安全的。效率比较低,使用较少了。
6、怎么将一个线程不安全的ArrayList集合转换成线程安全的呢?
使用集合工具类:
java.util.Collections;
java.util.Collection 是集合接口。
java.util.Collections 是集合工具类。
ArrayList是非线程安全的,转换为线程安全的
Collections.synchronizedList(myList)
public class VectorTest {
public static void main(String[] args) {
// 创建一个Vector集合
List vector = new Vector();
//Vector vector = new Vector();
// 添加元素
// 默认容量10个。
vector.add(1);
vector.add(2);
vector.add(3);
vector.add(4);
vector.add(5);
vector.add(6);
vector.add(7);
vector.add(8);
vector.add(9);
vector.add(10);
// 满了之后扩容(扩容之后的容量是20.)
vector.add(11);
Iterator it = vector.iterator();
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
// 这个可能以后要使用!!!!
List myList = new ArrayList(); // 非线程安全的。
// 变成线程安全的
Collections.synchronizedList(myList); // 这里没有办法看效果,因为多线程没学,你记住先!
// myList集合就是线程安全的了。
myList.add("111");
myList.add("222");
myList.add("333");
}
}
+++++++++++++++++++++++++++++++++++++++++++++++List结束
p689 泛型机制

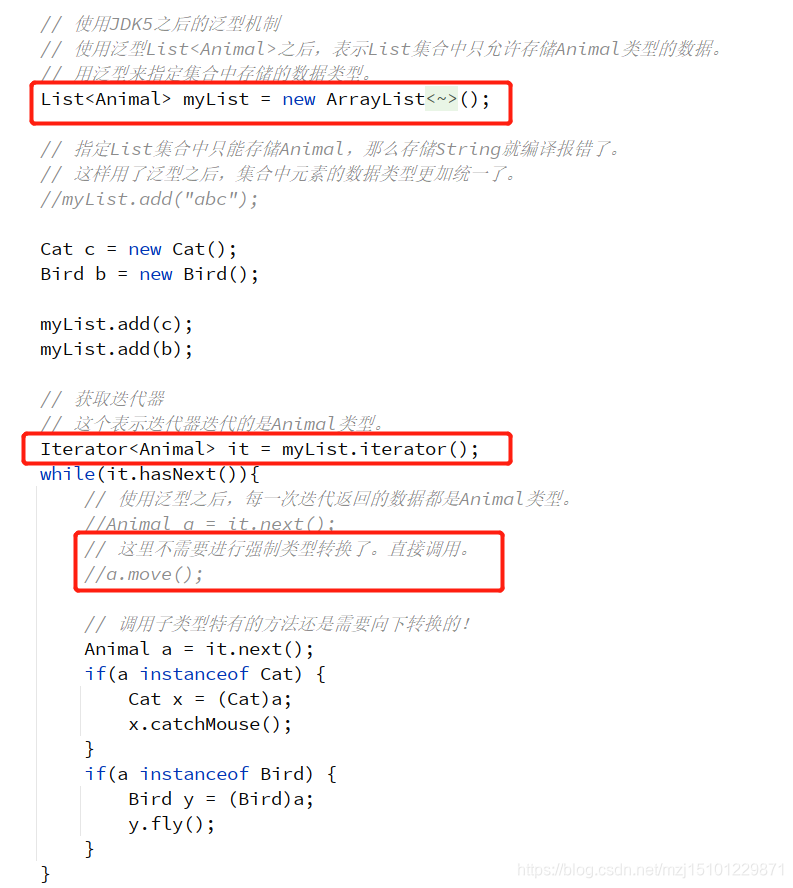
package com.bjpowernode.javase.collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/*
1、JDK5.0之后推出的新特性:泛型
2、泛型这种语法机制,只在程序编译阶段起作用,只是给编译器参考的。(运行阶段泛型没用!)
3、使用了泛型好处是什么?
第一:集合中存储的元素类型统一了。
第二:从集合中取出的元素类型是泛型指定的类型,不需要进行大量的“向下转型”!
4、泛型的缺点是什么?
导致集合中存储的元素缺乏多样性!
大多数业务中,集合中元素的类型还是统一的。所以这种泛型特性被大家所认可。
*/
public class GenericTest01 {
public static void main(String[] args) {
/*
// 不使用泛型机制,分析程序存在缺点
List myList = new ArrayList();
// 准备对象
Cat c = new Cat();
Bird b = new Bird();
// 将对象添加到集合当中
myList.add(c);
myList.add(b);
// 遍历集合,取出每个Animal,让它move
Iterator it = myList.iterator();
while(it.hasNext()) {
// 没有这个语法,通过迭代器取出的就是Object
//Animal a = it.next();
Object obj = it.next();
//obj中没有move方法,无法调用,需要向下转型!
if(obj instanceof Animal){
Animal a = (Animal)obj;
a.move();
}
}
*/
// 使用JDK5之后的泛型机制
// 使用泛型List<Animal>之后,表示List集合中只允许存储Animal类型的数据。
// 用泛型来指定集合中存储的数据类型。
List<Animal> myList = new ArrayList<Animal>();
// 指定List集合中只能存储Animal,那么存储String就编译报错了。
// 这样用了泛型之后,集合中元素的数据类型更加统一了。
//myList.add("abc");
Cat c = new Cat();
Bird b = new Bird();
myList.add(c);
myList.add(b);
// 获取迭代器
// 这个表示迭代器迭代的是Animal类型。
Iterator<Animal> it = myList.iterator();
while(it.hasNext()){
// 使用泛型之后,每一次迭代返回的数据都是Animal类型。
//Animal a = it.next();
// 这里不需要进行强制类型转换了。直接调用。
//a.move();
// 调用子类型特有的方法还是需要向下转换的!
Animal a = it.next();
if(a instanceof Cat) {
Cat x = (Cat)a;
x.catchMouse();
}
if(a instanceof Bird) {
Bird y = (Bird)a;
y.fly();
}
}
}
}
class Animal {
// 父类自带方法
public void move(){
System.out.println("动物在移动!");
}
}
class Cat extends Animal {
// 特有方法
public void catchMouse(){
System.out.println("猫抓老鼠!");
}
}
class Bird extends Animal {
// 特有方法
public void fly(){
System.out.println("鸟儿在飞翔!");
}
}
p690 自动类型推断(钻石表达式)


p691自定义泛型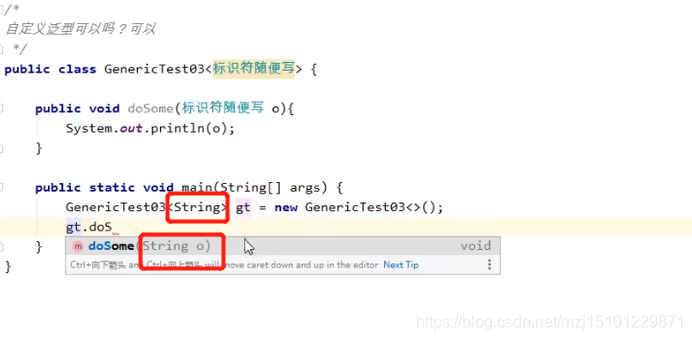
p692 增强for循环1【foreach】
缺点是没有下标

package com.bjpowernode.day24.Collection;
public class orEachTestF {
public static void main(String[] args) {
//int类型数组
int[] arr = {23,45,456,45,4566,56};
//遍历数组[普通for循环]
// for (int i = 0; i < arr.length;i++) {
// System.out.println(arr[i]);
//
// }
System.out.println("=====================");
//遍历数组[增强for循环]
for(int data:arr){
System.out.println(data);
}
}
}
p693 增强for循环2【foreach】
package com.bjpowernode.day24.Collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ForEachTest02 {
public static void main(String[] args) {
List<String> strList = new ArrayList<>();
strList.add("hello");
strList.add("world");
strList.add("kitty");
//使用迭代器遍历
// Iterator<String> it = strList.iterator();
// while(it.hasNext()){
// String s = it.next();
// System.out.println(s);
//
// }
//使用下标遍历.普通for循环
// for (int i = 0; i < strList.size(); i++) {
// String s = strList.get(i);
// System.out.println(s);
//
// }
//使用下标遍历.增强for循环
//String是因为泛型用的是String,后面的s是集合中的每一个元素
for(String s:strList){
System.out.println(s);
}
List<Integer> list = new ArrayList<>();
list.add(123);
list.add(466);
list.add(455);
list.add(433);
list.add(444);
//增强for遍历,i代表集合中的元素
for (Integer i : list){
System.out.println(i);
}
}
}
p694 演示HashSet集合的特点
无序不可重复
package com.bjpowernode.day24.Collection;
import java.util.HashSet;
import java.util.Set;
public class HashSetTest01 {
public static void main(String[] args) {
Set<String> strs = new HashSet<>();
strs.add("hello1");;
strs.add("hello2");;
strs.add("hello3");;
strs.add("hello4");;
strs.add("hello5");;
strs.add("hello6");;
strs.add("hello6");;
strs.add("hello6");;
strs.add("hello6");;
for (String s:strs){
System.out.println(s);
}
}
}
p695 演示TreeSet集合的特点
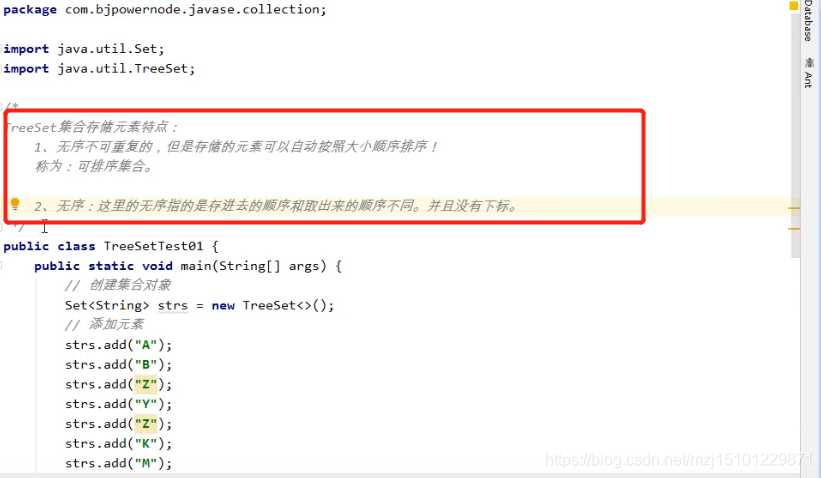
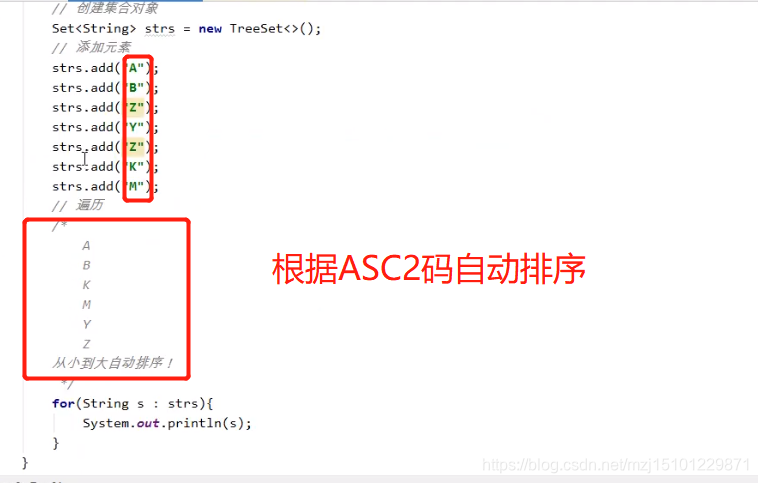
package com.bjpowernode.day24.Collection;
import java.util.Set;
import java.util.TreeSet;
public class TreeSetTest01 {
public static void main(String[] args) {
Set<String> strs = new TreeSet<>();
strs.add("A");
strs.add("B");
strs.add("C");
strs.add("M");
strs.add("Y");
strs.add("K");
for (String s:strs){
System.out.println(s);
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









