






 本文深入解析Java集合框架,包括集合与数组的区别,Collection与Map的特性,HashMap、Hashtable与LinkedHashMap的工作原理及区别,以及TreeSet、HashSet和LinkedHashSet的特性和使用场景。探讨了equals与hashcode的关系,ArrayList与LinkedList的性能对比,和TreeSet的排序机制。
本文深入解析Java集合框架,包括集合与数组的区别,Collection与Map的特性,HashMap、Hashtable与LinkedHashMap的工作原理及区别,以及TreeSet、HashSet和LinkedHashSet的特性和使用场景。探讨了equals与hashcode的关系,ArrayList与LinkedList的性能对比,和TreeSet的排序机制。
1.什么是集合?它和数组有什么区别?
(1)集合的由来?
我们学习的是Java -- 面向对象 -- 操作很多对象 -- 存储 -- 容器(数组和StringBuffer) -- 数组
而数组的长度固定,所以不适合做变化的需求,Java就提供了集合供我们使用。
(2)集合和数组的区别?
A:长度区别
数组固定
集合可变
B:内容区别
数组可以是基本类型,也可以是引用类型
集合只能是引用类型
C:元素内容
数组只能存储同一种类型
集合可以存储不同类型(其实集合一般存储的也是同一种类型)2.Collection和Map的区别
collection接口:是所有单列集合中共性的方法,因为list有索引,set无索引,所以collection中没有带索引的方法由于需求不同,Java就提供了不同的集合类。这多个集合类的数据结构不同,但是它们都是要提供存储和遍历功能的,
我们把它们的共性不断的向上提取,最终就形成了集合的继承体系结构图。
Collection
|--List
|--ArrayList
|--Vector
|--LinkedList
|--Set
|--HashSet
|--TreeSetMap
(1)将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
(2)Map和Collection的区别?
A:Map 存储的是键值对形式的元素,键唯一,值可以重复。夫妻对
B:Collection 存储的是单独出现的元素,子接口Set元素唯一,子接口List元素可重复。光棍3.HashMap和Hashtable和LinkedHashMap的区别
hashmap是一个无序的集合
hashtable是一个无序的集合
linkedhashmap是一个有序的集合
HashMap底层的数据结构是哈希表,哈希表是一种优秀的数据结构,它集成了数组的查询快和链表的增删快的特点.
为什么这么说?因为它可以理解为是一个元素为链表的数组.
HashMap的初始桶(数组的大小)的数量为16,loadFact(加载因子)为0.75,当桶里面的数据记录超过阈值(16*0.75)的时候,HashMap将会进行扩容则操作,每次都会变为原来大小的2倍,把所有元素rehash再放到扩容后的容器中,这是一个非常耗时的操作。直到设定的最大值之后就无法再resize(改变大小)了。为什么加载因子要默认是0.75?这就是算法概率统计学的事情了,关键字:泊淞分布,用0.75作为加载因子,每个桶(数组中的一个元素)中元素到达8个时候的概率 0.00000006(官方统计),也就是说用0.75作为加载因子,每个碰撞位置的链表长度超过8个是几乎不可能的。
如果put一个值(key,value)进来,会先对key进行hash运算,得到一个hashcode,hashcode根据算法,插入到数组中.当然,如果两个值是一样的hashcode,那么它们最后得到的插入脚标,是一样的,这种情况称为哈希冲突,解决哈希冲突有开放定址法,再哈希法,建立一个公共溢出区,链地址法等等,而HashMap解决哈希冲突就是用了链地址法,即发生了冲突会再比较其中的内容是否一致,也就是用equals()方法,如果内容一致,那么后者覆盖前者,如果内容不一致,那么后者成为前者的next节点,组成链表,
性能:
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。当桶中的节点数大于8时,桶结构由单链表转化为一个红黑树结构
区别
1、HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
2、HashMap的key-value支持key-value,null-null,key-null,null-value四种。而Hashtable只支持key-value一种(即key和value都不为null这种形式)。既然HashMap支持带有null的形式,那么在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断,因为使用get的时候,当返回null时,你无法判断到底是不存在这个key,还是这个key就是null,还是key存在但value是null。
3、线程安全性不同,HashMap的方法都没有使用synchronized关键字修饰,都是非线程安全的,而Hashtable的方法几乎都是被synchronized关键字修饰的。HashTable类是线程安全的,它使用synchronize来做线程安全,全局只有一把锁,在线程竞争比较激烈的情况下hashtable的效率是比较低下的。因为当一个线程访问hashtable的同步方法时,其他线程再次尝试访问的时候,会进入阻塞或者轮询状态,比如当线程1使用put进行元素添加的时候,线程2不但不能使用put来添加元素,而且不能使用get获取元素。所以,竞争会越来越激烈。但是,当我们需要HashMap是线程安全的时,怎么办呢?我们可以通过Collections.synchronizedMap(hashMap)来进行处理,亦或者我们使用线程安全的ConcurrentHashMap。ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。ConcurrentHashMap使用了分段锁技术来提高了并发度,不在同一段的数据互相不影响,多个线程对多个不同的段的操作是不会相互影响的。每个段使用一把锁。所以在需要线程安全的业务场景下,推荐使用ConcurrentHashMap,而HashTable不建议在新的代码中使用,如果需要线程安全,则使用ConcurrentHashMap,否则使用HashMap就足够了。
4、HashMap去掉了Hashtable的contains(Object value)方法,保留containsKey和containsValue方法。参考:
https://blog.youkuaiyun.com/weixin_40255793/article/details/80748946
https://www.jianshu.com/p/8f4f58b4b8ab
https://www.jianshu.com/p/e2f75c8cce01
https://blog.youkuaiyun.com/luojishan1/article/details/81952147
4.为什么重写equals方法就必须重写hashcode方法
趁热打铁
先说规定
1. 如果两个对象相同(即用equals比较返回true),那么它们的hashCode值一定要相同!!!!;
2. 如果两个对象不同(即用equals比较返回true),那么它们的hashCode值可能相同也可能不同;
3. 如果两个对象的hashCode相同(存在哈希冲突),那么它们可能相同也可能不同(即equals比较可能是false也可能是true)
4. 如果两个对象的hashCode不同,那么他们肯定不同(即用equals比较返回false)
也就是说如果equals相同,hashcode一定也要相同,这是规定,如果不遵循,就会产生误解和矛盾
对于对象集合的判重,如果一个集合含有10000个对象实例,仅仅使用equals()方法的话,那么对于一个对象判重就需要比较10000次,随着集合规模的增大,时间开销是很大的。但是同时使用哈希表的话,就能快速定位到对象的大概存储位置,并且在定位到大概存储位置后,后续比较过程中,如果两个对象的hashCode不相同,也不再需要调用equals()方法,从而大大减少了equals()比较次数。
比如new 两个学生出来,两个学生的name和age一样,如果仅仅自定义重写了equals方法(比较name和age),那么这两个学生是相同的,视为同一个学生,但是事实在堆中实际上是有两个学生对象,是两个不同的地址,hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值(百度来的),所以说这两个对象的hashcode大概率不同,如果把这两个学生,put到HashMap中,或者任何以哈希表为数据结构的集合中,都会出现两个"一样"的学生,这就违背了我们的初衷,我们使用HashMap,HashSet就是想为了去重复和效率,但是如果重写了equals而不重写hashcode,就达不到这样的效果.因为把这些对象塞进集合之前,会先判断hashcode,hashcode不同,直接塞进集合中,不去比较equals方法,这样你何必重写equals?所以产生矛盾.何必呢?5.TreeSet,LinkedTreeSet,HashSet的区别
1、如果我们需要将元素排序,那么使用TreeSet
2、如果我们不需要排序, 使用HashSet, HashSet比TreeSet效率高
3、如果我们需要保留存储顺序, 又要过滤重复元素, 那么使用LinkedHashSet
TreeSet:自然排序,自然排序是根据集合元素的大小,以升序排列,
HashSet:无序
LinkedTreeSet:取出和存入顺序一致@Test
public void testHashSet() throws Exception{
HashSet hashSet = new HashSet();
hashSet.add(2223);
hashSet.add(13);
hashSet.add(72);
hashSet.add(2);
Iterator iterator = hashSet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("hash = " + next);
}
}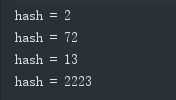 完全无序
完全无序
@Test
public void testTreeSet() throws Exception{
TreeSet treeSet = new TreeSet();
treeSet.add(2223);
treeSet.add(13);
treeSet.add(72);
treeSet.add(2);
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("tree = " + next);
}
}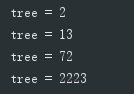 自然排序
自然排序
@Test
public void testLinkedHashSett() throws Exception{
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(2223);
linkedHashSet.add(13);
linkedHashSet.add(72);
linkedHashSet.add(2);
Iterator iterator = linkedHashSet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("linkedHashSet = " + next);
}
}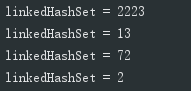 存入和取出顺序一致
存入和取出顺序一致
6.Set如何保证元素的唯一?为什么它是无序的
唯一
public boolean add(E e) {
//PRESENT是一个虚拟值,是为了HashMap实现HashSet的一个假设的值
return map.put(e, PRESENT)==null;
}当HashSet进行add操作时,其实是将要add的元素作为map的key,将PRESENT这个对象作为map的value,存入map中,并且需要注意到add方法的返回值是一个boolean。
其实到这里,我们应该能明白为什么HashSet中的元素不能重复了:
因为HashSet的底层是由HashMap实现的,而HashSet的add方法,是将元素作为map的key进行存储的,map的key是不会重复的,所以HashSet中的元素也不会重复。无序
HashSet是根据hashcode来决定存放位置,所以无序,也就是说你不知道你存的值它在集合中的位置7.ArrayList和LinkedList的区别
使用linkedList集合 不能使用多态
因为一些方法addfirst是linkedlist所特有的,所以不行
List的子类特点
ArrayList:
底层数据结构是数组,查询快,增删慢
线程不安全,效率高
Vector:
底层数据结构是数组,查询快,增删慢
线程安全,效率低
LinkedList:
底层数据结构是链表,查询慢,增删快
线程不安全,效率高8.TreeSet排序
Collections.sort(集合);* integer,string都实现了comparable接口,所以可以用sort方法
* 所以sort的使用前提是被排序的集合里面存储的元素,必须实现comparable,
* 所以需要排序自定义的pojo,需要实现comparable接口!!
* 并重写接口中的方法compareTo定义排序的规则
* 规则:
* 自己(this) - 参数 = 升序
* 反之,降序* comparable和comparator的区别
* comparable:自己(this)和别人(参数)比较,自己需要实现comparable接口,重写比较的规则comparaTo方法
* comparator:相当于找一个第三方的裁判,比较两个,可放在集合的构造器中当参数* comparator的排序规则,第一个参数 - 第二个参数 = 升序 1,2,3
* compare方法里面可以写多个规则
* o1-o2:升序
* 反之,降序

















 1596
1596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









