






 本文详细解析了Spark on YARN的cluster模式和client模式的提交运行流程,对比了两种模式的特点,包括资源调度、性能表现及网络流量等方面。
本文详细解析了Spark on YARN的cluster模式和client模式的提交运行流程,对比了两种模式的特点,包括资源调度、性能表现及网络流量等方面。
spark on yarn的 cluster模式 和 client模式 提交运行流程
---client 模式:

根据上面两个流程图得出:
每一个spark程序打成的jar包就是一个application,jar包提交到集群之后启动进程
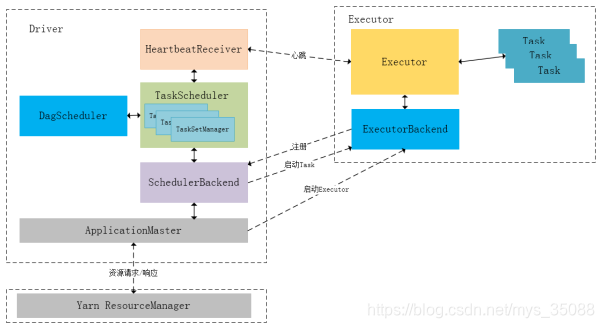
①spark driver在客户端,向yarn集群(resourceManager)请求资源,driver端同时初始化DAGSchulder,TaskSchulder,SchulderBackend和HeartbeatReceiver,启动SchedulerBackend 以及 HeartbeatReceiver,driver端划分stage、task。
②yarn集群发送一个nodeManager供spark 程序启动applicationMaster。
③applicationMaster请求到资源后启动相应个数的nodeManager用于运行spark(executor端)程序,SchedulerBackend 开始向applicationMaster请求资源,SchedulerBackend 不断向TaskSchulder获取合适的task分发到executor端。
④每个nodeManager 需要定时向resourceManager向HeartbeatReceiver发送心跳信息,同时向SchedulerBackend 通知executor的执行结果,然后schedulerBackend向TaskScheduler发送task执行情况,TaskScheduler把task执行情况发送给TaskManager,TaskManager记录了task的执行情况。
-----特点(也是cluster模式和client模式的区别):
①因为driver运行在本地机器上,所以Client模式的客户端不能杀掉。
②因为通常情况下client模式,driver运行在本地和yarn不是在一个机房所以性能不是很好。
③client模式会导致本地机器负责资源的调度,所以会引起网卡流量激增。
---cluster 模式:


根据上面两个流程图得出:
每一个spark程序打成的jar包就是一个application。
①jar包提交到集群之后启动进程,程序在yarn集群的一个nodeManager上向resourceManager请求资源,同时这个nodeManager也是spark程序的applicationMaster(driver端)。这时已经初始化了DAGSchulder,TaskSchulder,SchulderBackend和HeartbeatReceiver,启动SchedulerBackend 以及 HeartbeatReceiver,driver端划分stage、task。
②applicationMaster请求到资源后启动相应个数的nodeManager用于运行spark(executor端)程序。
③SchedulerBackend 开始向applicationMaster请求executor资源,同时和TaskSchulder交互获取合适的task并分发到executor端运行程序。
④每个nodeManager中的executor需要定时向resourceManager(driver端)的HeartbeatReceiver发送心跳信息,同时向SchedulerBackend 通知executor的执行结果,然后schedulerBackend向TaskScheduler发送task执行情况,TaskScheduler把task执行情况发送给TaskManager,TaskManager记录了task的执行情况。
--------特点(也是cluster模式和client模式的区别):
①因为driver不是运行在本地机器上而是运行在yarn的某一个nodeManager上,所以Cluster模式的客户端可以杀掉。
②因为通常情况下cluster模式driver和yarn集群是在一个机房所以性能很好。
③cluster模式没有流量激增的问题。
spark任务提交运行流程:


|
Application --> 多个job --> 多个stage --> 多个task |
1.Spark的driver端只是用来请求资源获取资源的,executor端是用来执行代码程序,也就是说application是在driver端,而job 、stage 、task都是在executor端。
2.在executor端划分job、划分stage、划分task。
程序遇见action算子划分一次job,每个job遇见shuffle(或者宽依赖)划分一次stage,每个stage中最后一个rdd的分区(分片)数就是task数量。
|--DAGScheduler(有向无环图信息,划分stage)
|--TaskScheduler(存放TaskSet,与SchedulerBackend结合向executor发送task任务)
|--DAGScheduler划分之后得taskSet被TaskScheduler封装成TaskManager,
最后TaskScheduler是以TaskManager为单位发送给SchedulerBackend
|--heartbeatReceiver(心跳连接)
|--ShcedulerBackend(和applicationMaster交互请求资源,和executor端交互获取task运行情况,然后讲结果反馈给TaskScheduler)
|--ApplicationMaster(向yarn的ResourceManager请求资源,获取到资源启动executor并将启动的executor信息反馈给SchedulerBackend)

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









