






 本文详细介绍了如何在Linux系统中创建虚拟环境并安装Scrapy,包括虚拟环境的创建、Scrapy的安装及爬虫项目的搭建过程。通过具体步骤,读者可以快速上手Scrapy爬虫开发。
本文详细介绍了如何在Linux系统中创建虚拟环境并安装Scrapy,包括虚拟环境的创建、Scrapy的安装及爬虫项目的搭建过程。通过具体步骤,读者可以快速上手Scrapy爬虫开发。
我使用的是linux系统,因为有其他的项目,特创建虚拟环境单独使用scrapy
1, 创建虚拟环境
mkvirtualenv scrapy_test(虚拟环境名称,自己随意命名)
2, 安装scrapy
pip install scrapy
执行这一步不仅仅会安装scrapy包,而且会自动下载安装一些其他的依赖包,会稍微慢一点
3,安装好以后进入虚拟环境使用命令创建爬虫项目
scrapy startproject firstspider(项目名称,随意命名),这一步是不是很像django创建项目命令
4,然后你会发现类似下面这个目录结构的爬虫项目已经创建成功了
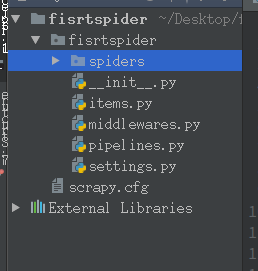
5, cd到第一层firstspider目录下,执行命令创建第一个爬虫
scrapy genspider myblog myblog.com(此步骤在执行完步骤3后会有相应的提示,类似于下面提示)
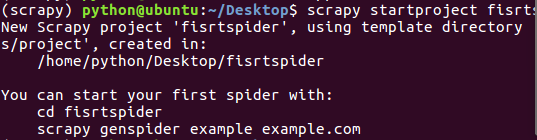
6。执行完步骤5后,你会在自己项目的spider目录下(创建好项目后是空文件夹)发现一个与自己创建的爬虫名称一样的py文件
7, 到此步骤后第一个爬虫完成,你可以打开你的第一个爬虫文件,就是下面这种结构
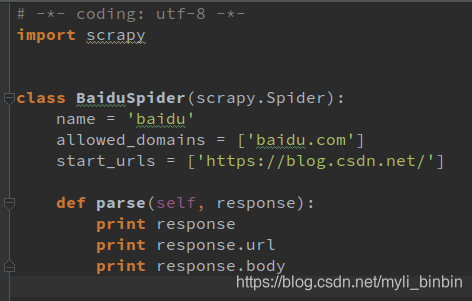
8, print是我自己改的,刚开始默认pass
9,这时候你可以启动命令去查看爬虫给你返回的结果
scrapy crawl myblog(你的项目名称)
scrapy crawl myblog --nolog(这样不会输出日志,能够很直观的看到返回结果)

















 65万+
65万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









