






 本文介绍了MongoDB中索引的基本概念、创建方法及其优化技巧。包括简单索引、复合索引、唯一索引等类型的创建及使用场景,同时探讨了查询优化器的工作原理和索引管理方法。
本文介绍了MongoDB中索引的基本概念、创建方法及其优化技巧。包括简单索引、复合索引、唯一索引等类型的创建及使用场景,同时探讨了查询优化器的工作原理和索引管理方法。
1,创建索引
# 语法:
db.stu.ensureIndex({"要加索引的字段名": 1})
例:
db.stu.ensureIndex({"name":1})
效果如下:
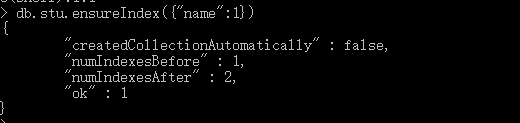
注意:虽然创建索引在查询时效率是量级的提高,但是创建索引是有代价的,对于每一个添加的索引,每次写操作(插入,更新,删除)都会耗费更多的时间,因为数据发生变化时,mongoDB不仅要更新文档,还要更新集合上的所有索引,因此,mongoDB限制每个集合上最多只能有64个索引! 但是:在一个特定的集合上,不应该拥有2个以上的索引,所以,挑选合适的索引是至关重要的!
2,复合索引
# 语法:
db.stu.ensureIndex({"字段1":1,"字段2":1})
例:
db.stu.ensuerIndex({"name":1, "age":1})
效果如下:
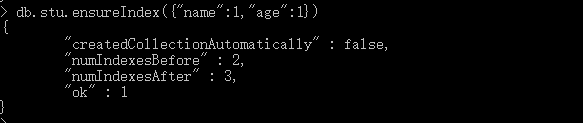
注意:①索引的值是按一定的顺序排列的,因此。如果使用索引键对文档进行排序会非常快,但是只有在首先使用索引键进行排序时,索引才有用!
②如果排序是按照某两个字段进行排序的,那么最好是在这两个字段上建立复合索引,这样才有用
③:创建复合索引时需要注意方向,以上面那个例子为例,如果我们的查询条件是按照name和age正序排列,那么是没有问题的,但是假如我们要以name正序排列,age倒叙排列,那么我们创建复合索引还按照上面那种方式就不合适了,就要以下面这种方式了,所以,在创建复合索引时要注意方向
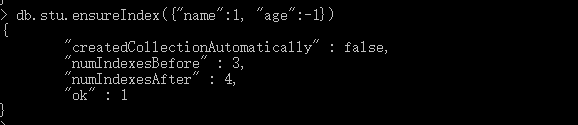
3,隐式索引
复合索引具有双重功能,而且对不同的查询有不同表现,如果有一个拥有N个键的索引,那么你就免费得到了所这N个键的前缀组成的索引
例:
如果你创建了一个{"a": 1, "b": 1, "c": 1, "d": 1, ... "h":1}的复合索引,那么实际上我们也可以使用{"a":1} , {"a":1, "b": 1}, {"a":1, "b": 1, "c": 1}等一系列索引,但是需要注意的是,不是这些键的任意子集所组成的索引都一定可用,比如,{"b":1}或者{"a":1, "c":1}作为索引是不会被优化的
4,索引对象
mongoDB允许深入文档内部,对嵌套字段和数组建立索引,大多数情况下,和正常使用索引是一样的
①在嵌套的文档建立索引
# 语法:
db.stu.ensureIndex({"a.b":1})
例:
db.stu.ensureIndex({"msg.email":1})
效果如下:(在msg对应的对象的email键上创建索引)

注意:对嵌套文档本身建立索引和对嵌套文档的某个字段建立索引是不同的,对整个子文档建立索引,只会提高整个子文档的查询速度,也就是说在进行与子文档完全匹配的子文档查询时,查询才会使用嵌套文档上的索引,也无法对嵌套文档的某个字段查询时使用该索引
5,索引数组
对数组建立索引,实际上是对数组中的每个元素建立索引,而不是对数组本身建立索引
6,使用expain()和hint()
expain()是mongoDB的诊断工具,可以显示出于查询有关的大量查询信息
#语法:
db.stu.find({查询条件}).explain()
详细信息如下:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "20201115.stu",
"indexFilterSet" : false,
"parsedQuery" : {
"name" : {
"$eq" : "paul"
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"name" : 1,
"age" : -1
},
"indexName" : "name_1_age_-1",
"isMultiKey" : false,
"multiKeyPaths" : {
"name" : [ ],
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"paul\", \"paul\"]"
],
"age" : [
"[MaxKey, MinKey]"
]
}
}
},
"rejectedPlans" : [
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"name" : 1,
"age" : 1
},
"indexName" : "name_1_age_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"name" : [ ],
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"paul\", \"paul\"]"
],
"age" : [
"[MinKey, MaxKey]"
]
}
}
},
{
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"name" : 1
},
"indexName" : "name_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"name" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"paul\", \"paul\"]"
]
}
}
}
]
},
"serverInfo" : {
"host" : "Mrli",
"port" : 27017,
"version" : "4.0.11",
"gitVersion" : "417d1a712e9f040d54beca8e4943edce218e9a8c"
},
"ok" : 1
}
如果发现使用的索引indexName和自己期望的不一样,可以使用hint()强制mongoDB使用特定的索引
#语法:
db.stu.find({查询条件}).hint({指定索引})
例:
db.stu.find({"name":"paul"}).hint({"name":1})
7,查询优化器
mongoDB查询优化器和其他数据库稍有不同,基本来说,如果一个索引能够精确匹配到一个查询,那么优化器会使用这个索引,不然的话,可能会有好几个索引都适合你的查询,mongoDB会从这些可能的索引自己中为每次查询计划选择一个,这些查询计划是并行执行的,最早返回100个结果的为胜者,其他的查询计划就会被终止!并且这个查询计划会被缓存,并且这个查询接下来都会使用它,直到集合数据发生了比较大的变化
8,索引类型
①:唯一索引
# 创建唯一索引
语法:
db.stu.ensureIndex({创建索引字段}, {"unique":true})
例:
db.stu.ensureIndex({"name":1 , "xx": -1}, {"unique": true})
1,复合唯一索引
注意:创建复合唯一索引时,单个键的值可以相同,但所有键的组合必须是唯一的
2,去除重复
在已有的集合上创建唯一索引时可能会失败,因为集合中可能已经存在相同的值了,那个这个时候先要对自己已有的数据进行处理,找出重复数据,并处理(删除),但是极少数情况下,可能希望删除重复的值,如果想删除怎么办呢?
# 创建索引时去重
语法:
db.stu.ensureIndex({要创建索引的字段}, {"unique":true, "dropDups": true})
例:
db.stu.ensureIndex({"name": 1}, {"unique": true, "dropDups": true })
使用“dropDups”选项时,如果遇到重复的值,,第一个会保留,之后的重复文档会被删除
②:稀疏索引
稀疏索引就是允许创建索引的字段不存在
# 语法:
db.stu.ensureIndex({"创建索引的字段"}, {"spare": true})
例:
db.stu.ensureIndex({"name": 1}, {"spare": true})
注意:稀疏索引不必是唯一的,如果希望是唯一的,则加入unique选项
9,索引管理
所有数据库索引信息都存储在system.indexes集合中,这是一个保留几个,不能在其中插入或者删除文档,只能通过ensureIndex或者dropIndex对其进行操作
那么如何查看一个集合上的索引信息呢
#语法:
db.stu.getIndexes()
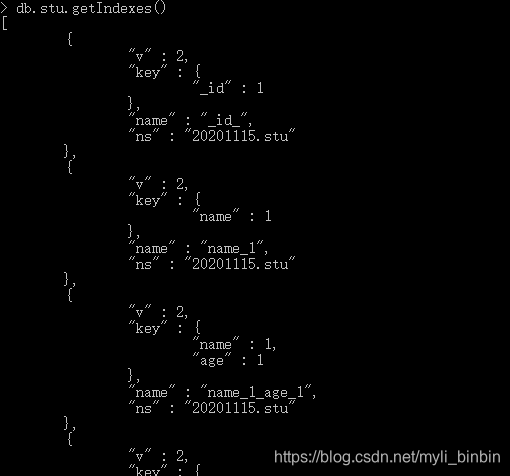
其中name为索引的名称,这个名称是唯一的,删除索引时就需要使用这个名称
#语法:
db.stu.dropIndex("索引名")
例:
db.stu.dropIndex("name_1_age_-1")
例:
![]()

















 4594
4594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









