




一、下载源码
项目地址:
https://github.com/ultralytics/yolov5.git![]() https://github.com/ultralytics/yolov5.git
https://github.com/ultralytics/yolov5.git
git clone https://github.com/ultralytics/yolov5
# 用于克隆yolov5项目
cd yolov5
pip install -r requirements.txt
# 安装所有依赖库下载完成后执行python detect.py测试yolov5是否可以正常运行
运行结果会放置在yolov5/runs/detect

二、数据集准备
可以直接下载已有数据集也可以手动标注图片制作数据集
本文使用labelimg来完成手动标注数据集这一步骤
1.安装labelimg
pip install labelimg
2.启动labelimg
安装完成后,直接输入labelimg会打开标注界面
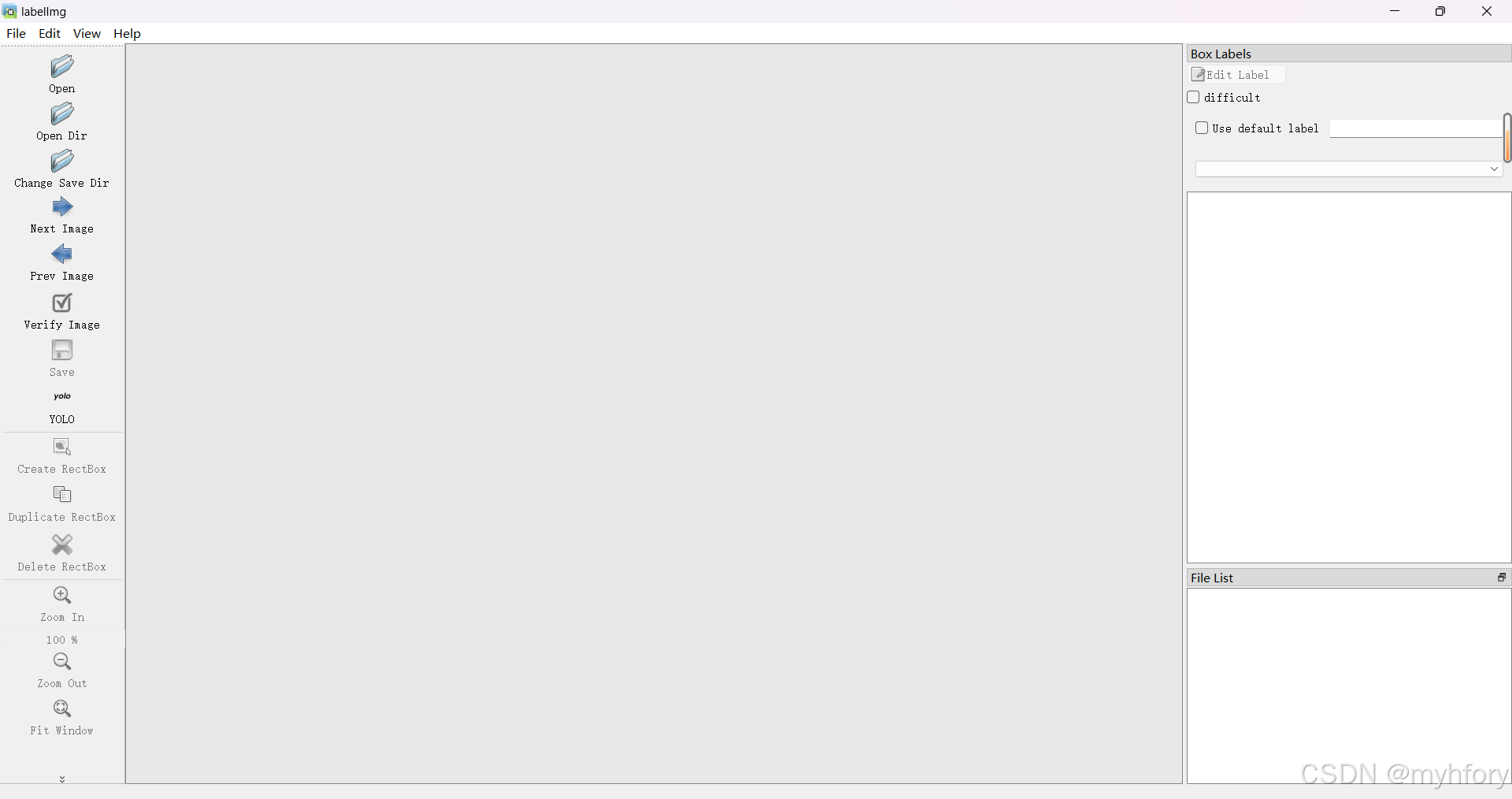
3.标注数据集
打开要标注的图片文件夹,并修改标注信息存储路径,然后开始标注

标注完后,标注信息存储路径下会出现标注文件,格式为txt文本
每张图片的标注信息与图片名相同,最终会多一个classes.txt文件,这个文件保存有所有的标注类别


三、修改配置文件
1.模型配置文件
官方给出的已有的模型配置文件一般在yolov5/models路径下,如下面的yolov5s.yaml
自己训练模型时,只需要修改下识别结果的总类别数 nc
总类别数
nc: 80 # number of classes倍增因子
depth_multiple (深度倍增因子):
这个参数决定了模型每个层的深度,也就是每个模块中的重复次数。值为
0.33表示模型的深度会减少到原始深度的 33%。width_multiple (宽度倍增因子):
这个参数用于调整模型每层的通道数(卷积层的输出通道数)。值为
0.50表示模型的宽度(通道数)将减少到原始宽度的 50%。depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple锚框
anchors: - [10, 13, 16, 30, 33, 23] # P3/8 - [30, 61, 62, 45, 59, 119] # P4/16 - [116, 90, 156, 198, 373, 326] # P5/32网络结构
# YOLOv5 v6.0 backbone backbone: # [from, number, module, args] [ [-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5 v6.0 head head: [ [-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, "nearest"]], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, "nearest"]], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
2.数据集配置文件
官方给出的已有的数据集配置文件一般在yolov5/data路径下,如下面的coco.yaml
开头注释,指明许可证,使用COCO 2017数据集,示例用法,文件结构,以及数据集的三种指定方式:
# Ultralytics YOLOv5 🚀, AGPL-3.0 license # COCO 2017 dataset http://cocodataset.org by Microsoft # Example usage: python train.py --data coco.yaml # parent # ├── yolov5 # └── datasets # └── coco ← downloads here (20.1 GB) # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]配置数据集路径,path指根路径,数据集所在的最外层文件夹,设置path后其他文件的路径均以path为基准。
train指训练集,test指测试集,val指验证集,可以设置为图片文件夹的位置或存有目录地址的文本文件:
path: ../datasets/coco # dataset root dir train: train2017.txt # train images (relative to 'path') 118287 images val: val2017.txt # val images (relative to 'path') 5000 images test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794所有要识别的目标的种类,从0开始编号
# Classes names: 0: person 1: bicycle 2: car 3: motorcycle 4: airplane 5: bus ············ 74: clock 75: vase 76: scissors 77: teddy bear 78: hair drier 79: toothbrush如果使用的数据集不存在,会自动从url下载到本地(官方给出的数据集):
# Download script/URL (optional) download: | from utils.general import download, Path # Download labels segments = False # segment or box labels dir = Path(yaml['path']) # dataset root dir url = 'https://github.com/ultralytics/assets/releases/download/v0.0.0/' urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels download(urls, dir=dir.parent) # Download data urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images 'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images 'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional) download(urls, dir=dir / 'images', threads=3)
自己训练模型时,只需要保留数据集路径配置和检测目标种类即可,如:
train: ../../Datas/train/images
val: ../../Datas/valid/images
test: ../../Datas/test/images
names:
0: A
1: B
2: C
3: D
4: E
5: F
6: G
7: H
8: I
9: J
10: K
11: L
12: M
13: N
15: O
14: P
16: Q
17: R
18: S
19: T
20: U
21: V
22: W
23: X
24: Y
25: Z
三、训练模型
1.模型训练
训练模型使用train.py,
YOLOv5提供了在COCO数据集上预训练后的参数,我们可以通过参数--weights yolov5s.pt加载预训练参数进行迁移学习,或在训练大数据集时用一个空的--weights ''参数从零开始训练
yolov5预训练模型下载链接
使用预训练好的yolov5模型,设置好要使用的预训练模型,数据集配置,模型配置,要训练的轮数,每批次处理的图片数:
python train.py --weight yolov5s.pt --data data.yaml --cfg yolov5s.yaml --epochs 100 --batch-size 8
# 使用预训练的模型yolov5s.pt
# 数据集配置文件为data.yaml,模型配置文件为yolov5s.yaml
# 训练的轮数为100,每批次处理8张图片2.参数列表
| 参数 | 功能 | 传入信息示例 |
|---|---|---|
| --weights | 指定初始权重文件路径 | 权重文件路径,如 ROOT / "yolov5s.pt" |
| --cfg | 指定模型配置文件(model.yaml)路径 | 模型配置文件路径,如 "" |
| --data | 指定数据集配置文件(dataset.yaml)路径 | 数据集配置文件路径,如 ROOT / "data/coco128.yaml" |
| --hyp | 指定超参数文件路径 | 超参数文件路径,如 ROOT / "data/hyps/hyp.scratch-low.yaml" |
| --epochs | 指定总训练轮数 | 整数,如 100 |
| --batch-size | 指定总批处理大小(对所有 GPU,-1 表示自动调整) | 整数,如 16 |
| --imgsz | 指定训练和验证图像大小(像素) | 整数,如 640 |
| --rect | 是否进行矩形训练 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --resume | 是否从最近的训练中恢复,若没有参数则默认为 False,有参数但不具体指定值时默认为 True | 布尔值或空参数,如 nargs="?",const=True,default=False |
| --nosave | 是否只保存最终检查点 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --noval | 是否只验证最终的 epoch | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --noautoanchor | 是否禁用自动锚框 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --noplots | 是否不保存绘图文件 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --evolve | 进化超参数的代数,如果没有参数则默认为 300 | 整数或空参数,如 nargs="?", const=300 |
| --evolve_population | 指定加载种群的位置 | 路径,如 ROOT / "data/hyps" |
| --resume_evolve | 指定从哪一代恢复进化 | 字符串,如 None |
| --bucket | 指定 gsutil 存储桶 | 字符串,如 "" |
| --cache | 指定图像缓存方式(ram 或 disk),如果没有参数则默认为 ram | 字符串或空参数,如 nargs="?", const="ram" |
| --image-weights | 是否使用加权图像选择进行训练 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --device | 指定 CUDA 设备,若为空则为 CPU | 设备编号或 "cpu",如 "" |
| --multi-scale | 是否进行图像尺寸变化(+/- 50%) | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --single-cls | 是否将多类数据作为单类训练 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --optimizer | 选择优化器(SGD、Adam、AdamW) | 字符串,如 "SGD" |
| --sync-bn | 是否使用同步批归一化,仅在分布式数据并行(DDP)模式下可用 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --workers | 指定最大数据加载器工作线程数(在 DDP 模式下每个 RANK) | 整数,如 8 |
| --project | 指定保存训练结果的项目路径 | 路径,如 ROOT / "runs/train" |
| --name | 指定保存训练结果的名称 | 字符串,如 "exp" |
| --exist-ok | 若项目 / 名称已存在是否继续,不递增 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --quad | 是否使用四倍数据加载器 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --cos-lr | 是否使用余弦学习率调度器 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --label-smoothing | 指定标签平滑参数 | 浮点数,如 0.0 |
| --patience | 指定早停法的耐心值(没有改进的轮数) | 整数,如 100 |
| --freeze | 指定冻结的层,例如 backbone=10, first3=0 1 2 | 整数组成的列表,如 [0] |
| --save-period | 指定每隔多少个 epoch 保存一次检查点(小于 1 则禁用) | 整数,如 -1 |
| --seed | 指定全局训练种子 | 整数,如 0 |
| --local_rank | 自动 DDP 多 GPU 参数,不要修改 | 整数,如 -1 |
| --entity | 指定实体 | 字符串,如 None |
| --upload_dataset | 是否上传数据集,参数为 “val” 时有特定选项 | 布尔值或空参数,如 nargs="?", const=True,default=False |
| --bbox_interval | 设置边界框图像日志记录间隔 | 整数,如 -1 |
| --artifact_alias | 指定数据集工件的版本别名 | 字符串,如 "latest" |
| --ndjson-console | 是否将 NDJSON 日志记录到控制台 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
| --ndjson-file | 是否将 NDJSON 日志记录到文件 | 布尔值,action="store_true",若执行命令时带有该参数则为 True |
3.常用参数
1)--weights
指定初始权重文件路径,例如 ROOT/yolov5s.pt
2.)-cfg
指定模型配置文件路径,例如 model.yaml
3)--data
指定数据集配置文件路径,例如 ROOT/data/coco128.yaml
4)--epochs
指定总训练轮数,整数值(如 100)
5)--batch-size
指定总批处理大小,整数值(如 16),-1 表示自动调整
6)--imgsz
指定训练和验证图像大小(像素),整数值(如 640)
7)--resume
是否从最近的训练中恢复,布尔值或空参数,默认为 False
8)--device
指定 CUDA 设备,若为空则为 CPU(如 "")
9)--project
指定保存训练结果的项目路径,如 ROOT/runs/train
10)--name
指定保存训练结果的名称(如 "exp")
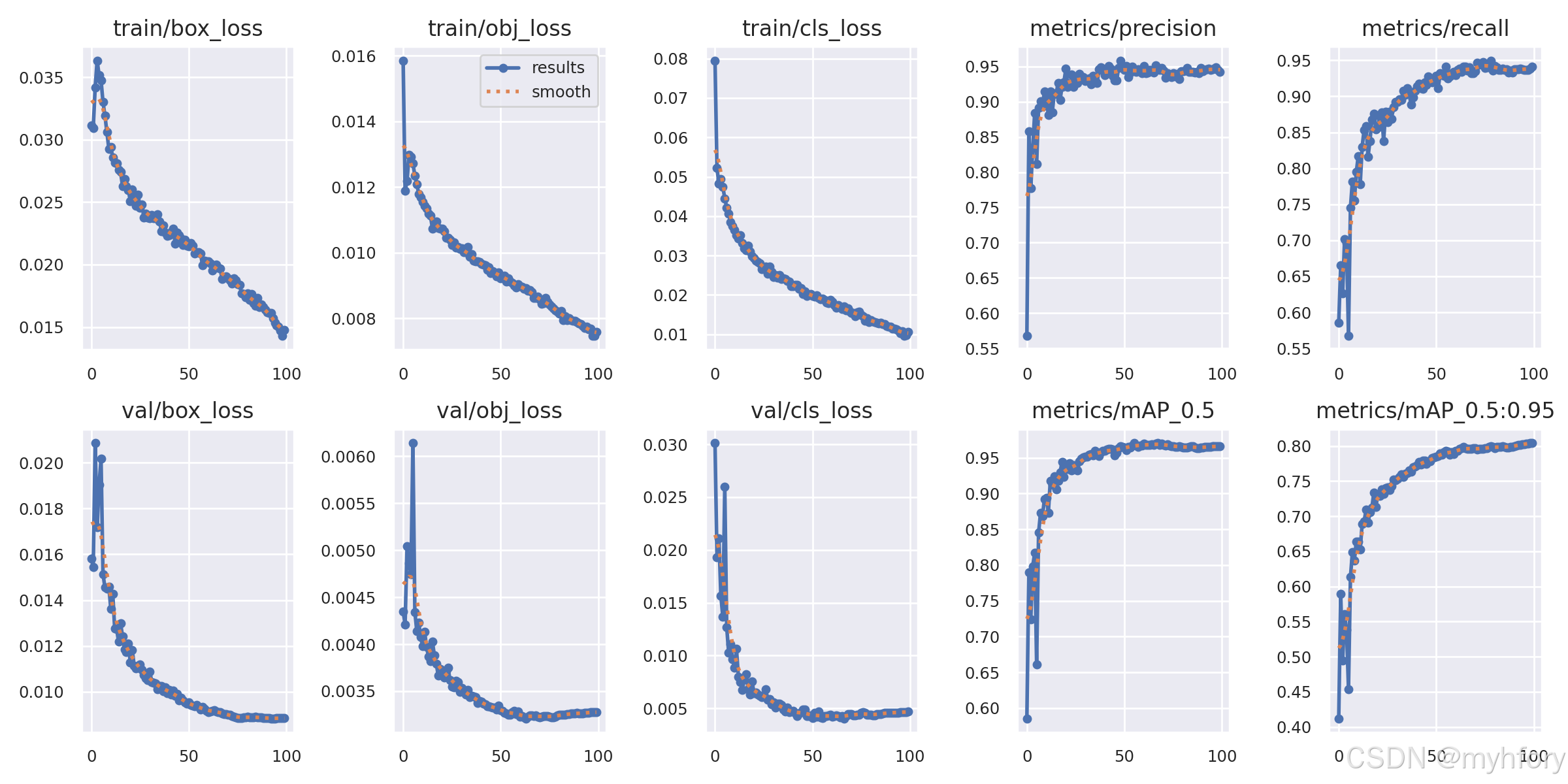
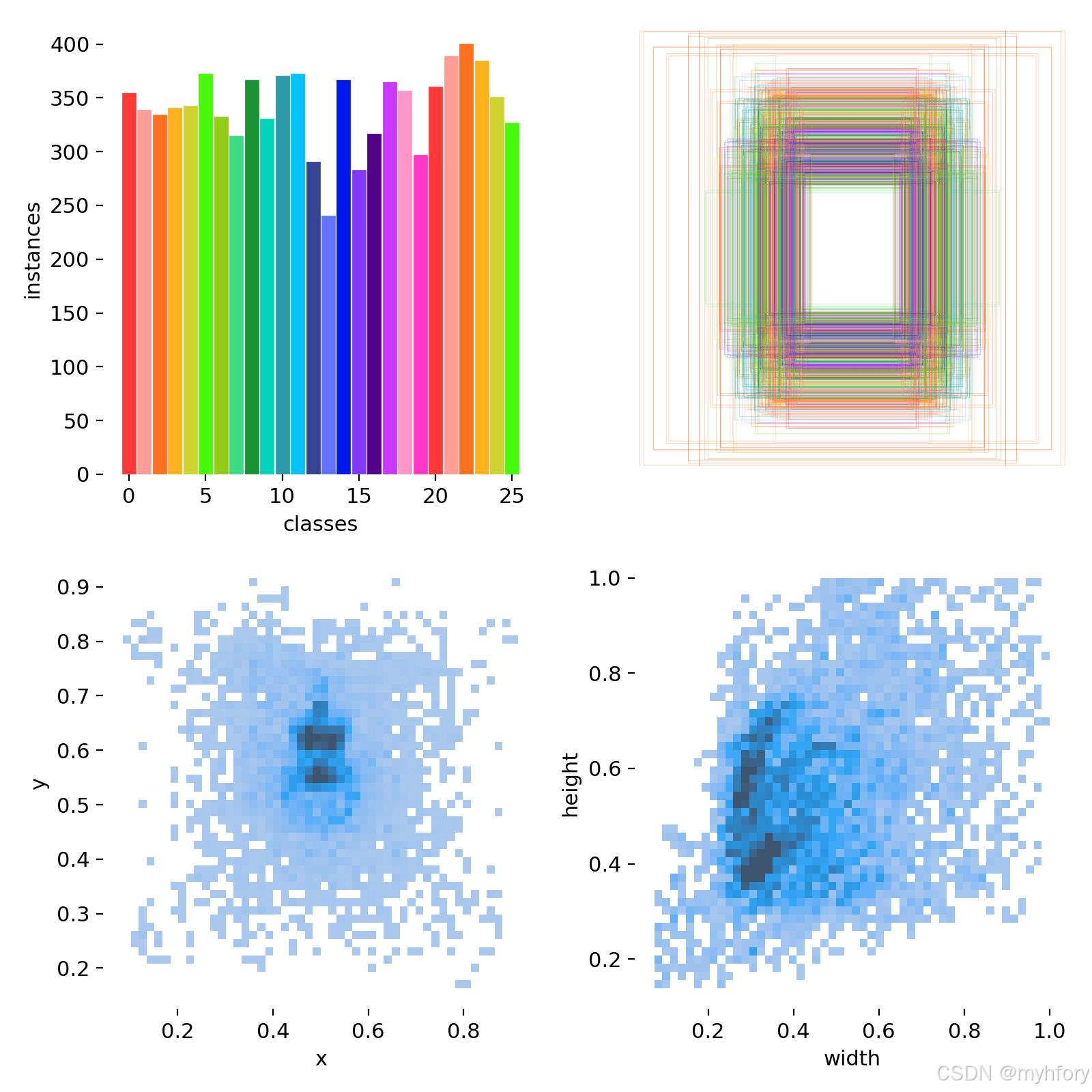
4.训练结果
模型最终训练完成后会保存在yolov5/runs/train路径下
在训练结果文件夹下会有/weight文件夹,里面存放着训练最好的模型与最后一轮训练的模型,一般使用best.pt。
结果文件夹下还有很多评价模型优度的文件,如混淆矩阵confusion_matrix,F1_curve,P_curve,R_curve,在训练集和验证集上的召回率、准确率和损失率等,以及对数据的分析信息


















 5914
5914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









