




 本文详细解析JVM内存布局,涵盖线程私有区如程序计数器、虚拟机栈、本地方法栈,以及线程共享区如方法区、堆、运行时常量池和直接内存。探讨各区域的作用、数据存储特性及其与垃圾回收的关系。
本文详细解析JVM内存布局,涵盖线程私有区如程序计数器、虚拟机栈、本地方法栈,以及线程共享区如方法区、堆、运行时常量池和直接内存。探讨各区域的作用、数据存储特性及其与垃圾回收的关系。
-
JVM内存模型和结构
JVM定义了不同运行时数据区,他们是用来执行应用程序的。某些区域随着JVM启动及销毁,另外一些区域的数据是线程性独立的,随着线程创建和销毁.
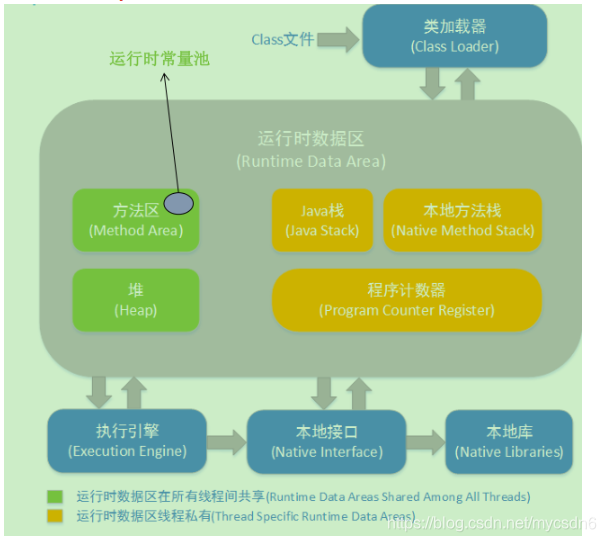
线程私有区:
1.程序计数器:
当同时进行的线程数超过CPU数或其内核数时,就要通过时间片轮询分派CPU的时间资源,不免发生线程切换。这时,每个线程就需要一个属于自己的计数器来记录下一条要运行的指令(保存线程切换时执行的位置)。如果执行的是JAVA 方法,计数器记录正在执行的java字节码地址,如果执行的是native方法,则计数器为空。
2.虚拟机栈:
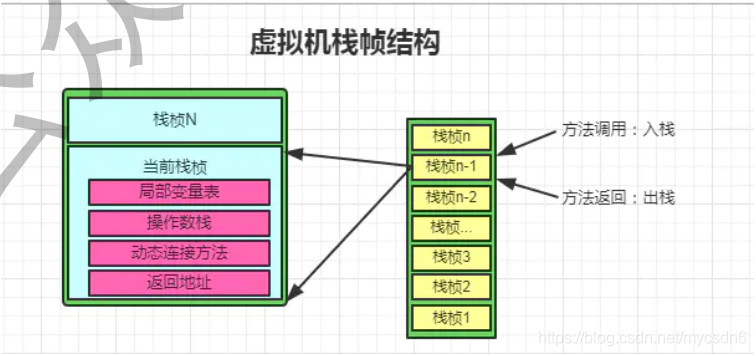
线程私有的,与线程在同一时间创建。管理JAVA方法执行的内存模型。 每个方法在执行的同时都会创建一个 栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息。方法的执行就对应着栈帧在虚拟机栈中入栈和出栈的过程;栈里面存放着各种基本数据类型和对象的引用;
栈中存放了编译器可知的八种基本数据类型(byte,char,short,int,long,double,float,boolean) 以及对象引用(对象引用不等同对象本身,可能是指向对象起始地址的引用指针)。 栈的生命周期与线程相同,每个方法在执行的同事都会创建一个栈帧(栈帧是用来存储局部变量表,操作数栈, 动态链接以及方法出口等) 通过配置-Xss参数来设置栈容量大小
下图为栈帧结构图:
3.本地方法栈:
本地方法栈保存的是native方法的信息,当一个JVM创建的线程调用native方法后,JVM不再为其在虚拟机栈中创建栈 帧,JVM只是简单地动态链接并直接调用native方法;
线程共享区:
1.方法区:
线程共享的,用于存放被虚拟机加载的类的元数据信息,如常量、静态变量和即时编译器编译后的代码。若要分代,算是永久代(老年代),以前类大多“static”的,很少被卸载或收集,现回收废常量和无用的类。其中运行时常量池存放编译生成的各种常量。(如果hotspot虚拟机确定一个类的定义信息不会被使用,也会将其回收。回收的基本条件至少有:所有该类的实例被回收,而且装载该类的ClassLoader被回收) (jdk1.8已经将方法区去掉了,将方法区移动到直接内存)
JDK1.8为什么要移除方法区
1)永久代来存储类信息、常量、静态变量等数据不是个好主意, 很容易遇到内存溢出的问题.JDK8的实现中将类的元数据放入 native memory, 将字符串池和类的静态变量放入java堆中. 可以使用MaxMetaspaceSize对元数据区大小进行调整;
2)对永久代进行调优是很困难的,同时将元空间与堆的垃圾回收进行了隔离,避免永久代引发的Full GC和OOM等问题;
2.堆:
存放对象实例和数组,是垃圾回收的主要区域,分为新生代和老年代。刚创建的对象在新生代的Eden区中,经过GC后进入新生代的S0区中,再经过GC进入新生代的S1区中,15次GC后仍存在就进入老年代。这是按照一种回收机制进行划分的,不是固定的。若堆的空间不够实例分配,则OutOfMemoryError。
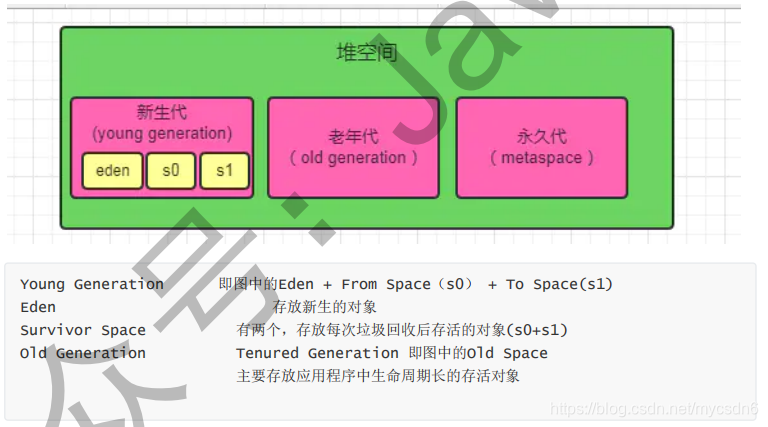
运行时常量池: 运行时常量池是方法区的一部分,用于存放编译期生成的各种字面("zdy","123"等)和符号引用。
直接内存:不是虚拟机运行时数据区的一部分,也不是java虚拟机规范中定义的内存区域;
1)如果使用了NIO,这块区域会被频繁使用,在java堆内可以用directByteBuffer对象直接引用并操作;
2) 这块内存不受java堆大小限制,但受本机总内存的限制,可以通过MaxDirectMemorySize来设置(默认与堆 内 存最大值一样),所以也会出现OOM异常;
堆和栈的区别:
栈是运行时单位,代表着逻辑,内含基本数据类型和堆中对象引用,所在区域连续,没有碎片;
堆是存储单位,代表着数据,可被多个栈共享(包括成员中基本数据类型、引用和引用对象),所在区域不连续, 会 有碎片。
1. 功能上的不同:
栈内存用来存储局部变量和方法调用(基本数据类型的变量(int、short、long、byte、float、double、boolean、char等)以及对象的引用变量,其内存分配在栈上,变量出了作用域 就 会自动释放;)
而堆内存用来存储Java中的对象。无论是成员变量,局部变量,还是类变量,
它们指向的对象都存储在堆内存中。
2. 共享性上的不同:
栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见,即栈内存可以理解成线程的私有内存。
堆内存中的对象对所有线程可见。堆内存中的对象可以被所有线程访问。
3. 空间大小:
栈的内存要远远小于堆内存,栈的深度是有限制的,如果递归没有及时跳出,很可能发生StackOverFlowError问题。
你可以通过-Xss选项设置栈内存的大小(这个参数是设定单个线程的栈空间)。-Xms选项可以设置堆的开始时的大小,-Xmx选项可以设置堆的最大值
4.异常错误提示:
栈空间不足:java.lang.StackOverFlowError。
堆空间不足:java.lang.OutOfMemoryError。
JVM内存参数设定
-Xms 初始堆内存大小
-Xmx 最大堆内存大小
-Xss 单个线程栈大小
-XX:NewSize 初始新生代堆大小
-XX:MaxNewSize 生代最大堆大小
-XX:PermSize 方法区初始大小(JDK1.7及以前)
-XX:MaxPermSize 方法区最大大小(JDK1.7及以前)
-XX:MetaspaceSize 元数据区初始值(JDK1.8)
-XX:MaxMetaspaceSize 元数据区最大值(JDK1.8)
参数设置示例
jdk1.7 windows设置tomcat的catalina.bat
set JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:PermSize=128m -XX:MaxPermSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.8 windows设置tomcat的catalina.bat
set JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:MetaspaceSize=128m -XX:MAXMetaspaceSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.7 linux设置tomcat的catalina.sh
JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:PermSize=128m -XX:MaxPermSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
jdk1.8 linux设置tomcat的catalina.sh
JAVA_OPTS=-Xms1024m -Xmx1024m -Xss1m -XX:MetaspaceSize=128m -XX:MAXMetaspaceSize=256m -XX:NewSize=256m -XX:MaxNewSize=256m
GC原理:
判断对象是否存活一般有两种方式:
引用计数:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收。此方法简单,无法解决对象相互循环引用的问题。 这个方法实现简 单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。
可达性分析(Reachability Analysis):从GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用,不可达对象。
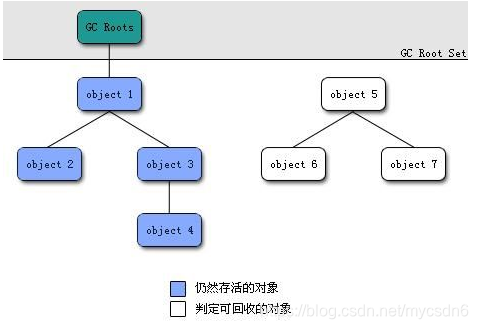
垃圾回收算法:
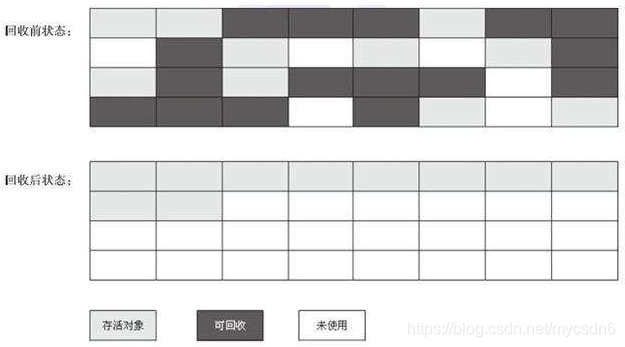
1.标记-清除法:
该算法分为“标记”和“清除”阶段:首先比较出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
-
-
效率问题
-
空间问题(标记清除后会产生大量不连续的碎片)
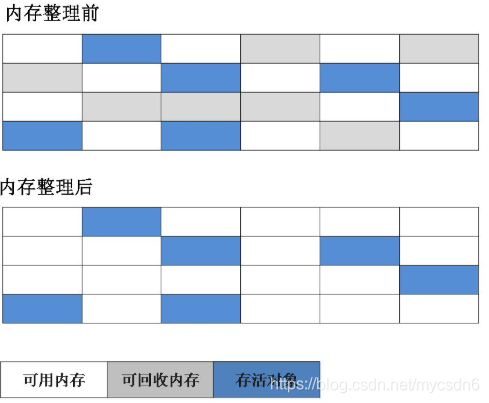
-
2. 复制算法
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
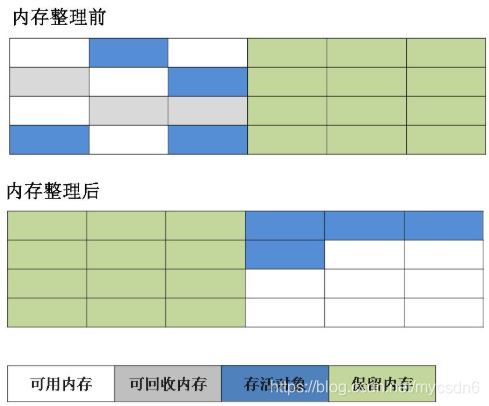
3.标记-整理(压缩)法
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
4. 分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
不可达的对象并非“非死不可”
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
被判定为需要执行的对象将会被放在一个队列中进行第二次标记,除非这个对象与引用链上的任何一个对象建立关联,否则就会被真的回收。

















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









