




*前段时间学习了一些浅显的爬虫知识,防止遗忘写个博客记录一下,如果能帮到其他人是更好的
本篇介绍一下如何一步一步实现使用python爬取豆瓣电影TOP250,博主是个小白,如果内容有误,请将宝贵的建议请留在评论区,谢谢*
源代码在最后面
本篇爬取的数据为静态数据
一、什么是爬虫
网络爬虫就是通过编写程序或脚本模拟人操作浏览器阅览网页。
二、分析
,首先确定需要的数据,我们的目的是爬取豆瓣电影TOP250页面每部电影的详细信息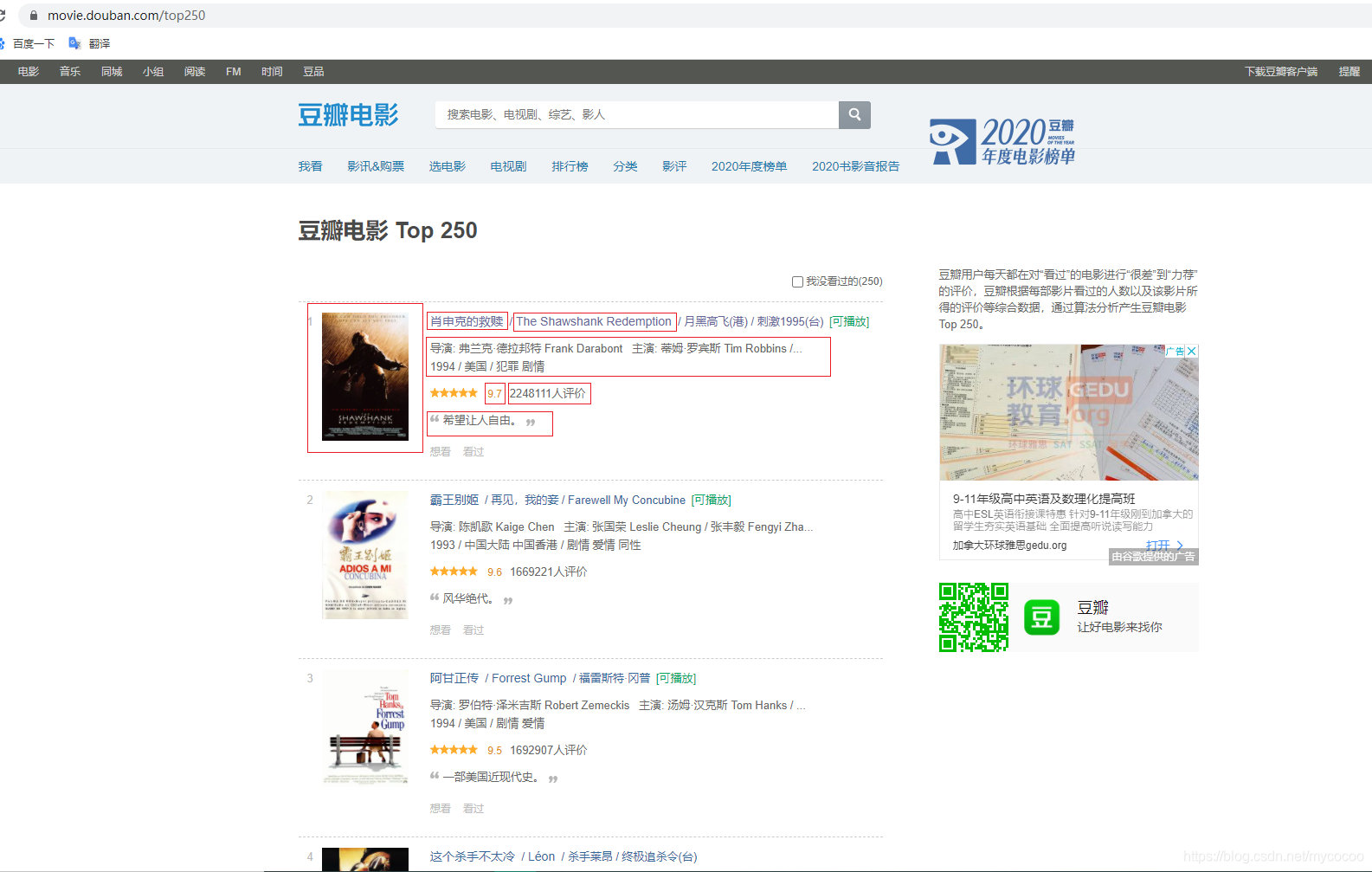
打开开发者工具找到元素的位置
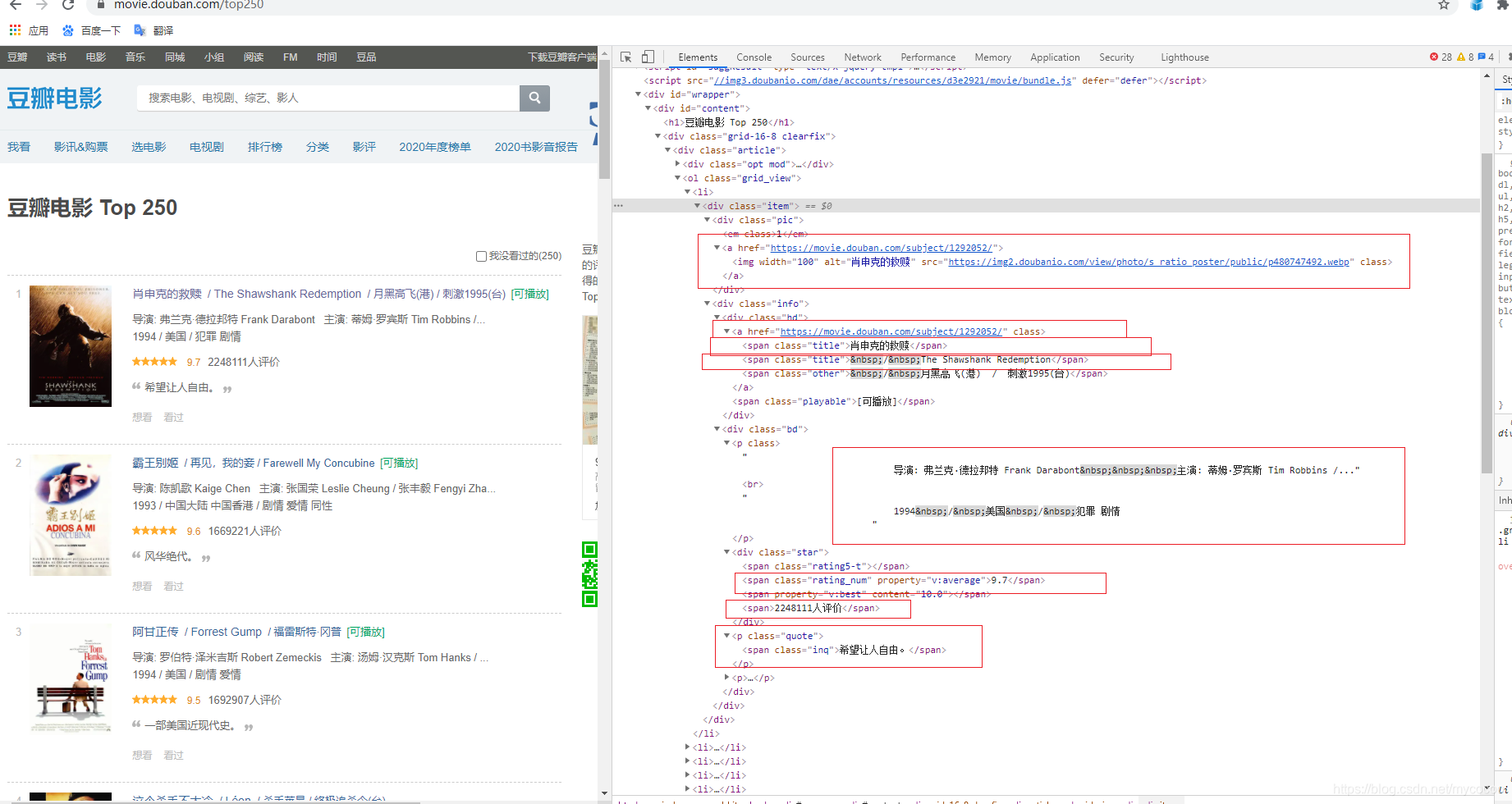
此处拿八个数据举例子:海报链接、电影链接、电影中文名、电影外文名、电影制片人员、电影评分、参与电影评分人数、电影总结;
三、编写代码
1、连接页面
要爬取这个页面的数据第一步肯定是访问这个页面。
要访问这个页面需要导入一些包
在这里使用urllib,我将会在另外一篇博客中用爬取全国疫情数据的实例写使用selenium爬取数据的方法。
import urllib.request,urllib.error #制定URL,前者获取网页数据,后者返回错误信息
连接页面普通方法:
#得到指定一个URL的网页内容
def askURL(url): #url为传入函数的参数,代表访问页面的地址''
html=""
response=urllib.request.urlopen(url) #使用urllib中的方法连接页面
html=response.read().decode("utf-8") #建议使用打印一下html,观察返回的是什么
return html
这种方法直接打开一个网页,网页可以判断到你就是一个程序或者脚本,很多网页都具有反爬机制,这样明显的爬取大概率会被网页禁止访问,并返回403错误
伪装自己的连接页面方法:
def askURL(url):
header={
"User-Agent":"*****************************************************"}
request=urllib.request.Request(url,headers=header)
html=""
response=urllib.request.urlopen(request)
html=response.read().decode("utf-8")
return html
如何伪装自己呢?有一种思路就是访问页面时给网页我们的User-Agent(用户代理)

获取方法也是通过开发者工具

将其完整的复制到我们命名的header中
现在就可以用用户代理封装一个访问请求了
request=urllib.request.Request(url,headers=header)
然后再连接网页
response=urllib.request.urlopen(request)
2、获取页面数据
如果你刚才打印了html那么你将会看到
这些都是网页前端的html代码,当然如果只是这样我们还是无法读取数据的
此时需要导入另外一个包
from bs4 import BeautifulSoup #网页解析,获取数据
1 获取askURL函数返回的网页数据
2 通过BeautifulSoup解析网页数据
3 通过BeautifulSoup中的.find方法查询目标元素到的位置
- soup=BeautifulSoup(html,“html.parser”)
- soup.find_all(‘标签类型’,属性类型_=“属性值”)
4查找每个目的元素,并添加到数组中。
这时我们又需要导入一个包
import re #正则表达式,进行文字匹配
#因为需要的数据数量比较多,为了代码的看读性,统一在全局变量中设置
findLink=re.compile(r'<a href="(.*?)">') #连接
findImage=re.compile(r'<img.*src="(.*?)" width="100"/>',re.S) #图片
findTitle=re.compile(r'<span class="title">(.*)</span>') #名字
findRating=re. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









