






目录
K-means及K-means++原理相对简单,直接引用了下文中的内容:
https://www.cnblogs.com/yixuan-xu/p/6272208.html
本文重点是基于python实现了K-means和K-means++算法,并做了测试。
一、K-means

二、K-means++
起步
由于 K-means 算法的分类结果会受到初始点的选取而有所区别,因此有提出这种算法的改进: K-means++ 。
算法步骤
其实这个算法也只是对初始点的选择有改进而已,其他步骤都一样。初始质心选取的基本思路就是,初始的聚类中心之间的相互距离要尽可能的远。
算法描述如下:
- 步骤一:随机选取一个样本作为第一个聚类中心 c1;
- 步骤二:
-
- 计算每个样本与当前已有类聚中心最短距离(即与最近一个聚类中心的距离),用 D(x)表示;
- 这个值越大,表示被选取作为聚类中心的概率较大;
- 最后,用轮盘法选出下一个聚类中心;
- 步骤三:重复步骤二,直到选出 k 个聚类中心。
选出初始点后,就继续使用标准的 k-means 算法了。
效率
K-means++ 能显著的改善分类结果的最终误差。
尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。
网上有人使用真实和合成的数据集测试了他们的方法,速度通常提高了 2 倍,对于某些数据集,误差提高了近 1000 倍。

下面结合一个简单的例子说明K-means++是如何选取初始聚类中心的。
数据集中共有8个样本,分布以及对应序号如下图所示:
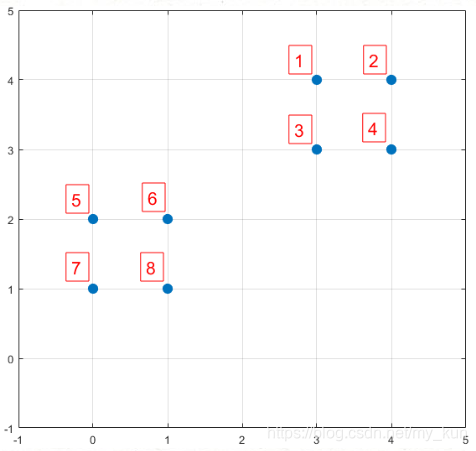
假设经过图2的步骤一后6号点被选择为第一个初始聚类中心,
那在进行步骤二时每个样本的D(x)和被选择为第二个聚类中心的概率如下表所示:
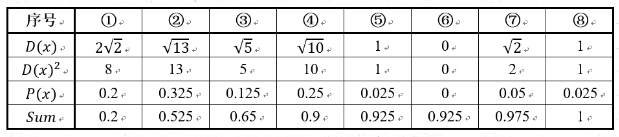
其中的P(x)就是每个样本被选为下一个聚类中心的概率。
最后一行的Sum是概率P(x)的累加和,用于轮盘法选择出第二个聚类中心。
方法是随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了。
例如1号点的区间为[0,0.2),2号点的区间为[0.2, 0.525)。
从上表可以直观的看到第二个初始聚类中心是1号,2号,3号,4号中的一个的概率为0.9。
而这4个点正好是离第一个初始聚类中心6号点较远的四个点。
这也验证了K-means的改进思想:即离当前已有聚类中心较远的点有更大的概率被选为下一个聚类中心。
可以看到,该例的K值取2是比较合适的。当K值大于2时,每个样本会有多个距离,需要取最小的那个距离作为D(x)。
三、代码实现
import numpy as np
import random
def distance(vec1, vec2):
# 定义距离
return np.sqrt(np.sum((vec1 - vec2) ** 2))
def kmeans(dataset, k, is_kmeans=True, is_random=False):
"""
dataset: 数据集 二维数组
k: 聚类数量
is_kmeans: 默认True 使用k-means,否则使用k-means++
is_random: 默认False,在使用k-means++时,选取最远距离样本为新聚类中心;否则根据距离使用概率随机产生
"""
num_sample, num_feature = dataset.shape
# K-means++ 初始化聚类中心
if not is_kmeans:
# 1.随机选出第一个中心点
first_idx = random.sample(range(num_sample), 1)
center = dataset[first_idx]
# 2.计算每个样本距每个中心点的距离,并通过轮盘赌选出其他中心点
dist_note = np.zeros(num_sample)
dist_note += 1000000000.0
for j in range(k):
if j+1 == k:
break # 已经计算了足够的聚类中心,直接退出
# 计算每个样本和各聚类中心的距离,保存最小的距离
for i in range(num_sample):
dist = distance(center[j], dataset[i])
if dist < dist_note[i]:
dist_note[i] = dist
# 若使用轮盘赌,根据距离远近随机产生新的聚类中心,否则使用最远距离的样本作为下一个聚类中心点
if is_random:
dist_p = dist_note / dist_note.sum()
next_idx = np.random.choice(range(num_sample), 1, p=dist_p)
center = np.vstack([center, dataset[next_idx]])
else:
next_idx = dist_note.argmax()
center = np.vstack([center, dataset[next_idx]])
# K-means 随机初始化聚类中心
else:
# 随机初始化聚类中心点
center_indexs = random.sample(range(num_sample), k)
center = dataset[center_indexs, :]
# K-means算法迭代实现
cluster_assessment = np.zeros((num_sample, 2))
cluster_assessment[:, 0] = -1 # 将所有的类别置为 -1
cluster_changed = True
while cluster_changed:
cluster_changed = False
for i in range(num_sample):
min_distance = 100000000.0
c = 0
# 确定每一个样本属于哪一个类,即与哪个中心点最近
for j in range(k):
dist = distance(dataset[i, :], center[j, :])
if min_distance > dist:
min_distance = dist
c = j
# 更新簇
if cluster_assessment[i, 0] != c: # 仍存在数据在前后两次计算中有类别的变动,未达到迭代停止要求
cluster_assessment[i, :] = c, min_distance
cluster_changed = True
# 更新簇中心点位置
for j in range(k):
changed_center = dataset[cluster_assessment[:, 0] == j].mean(axis=0)
center[j, :] = changed_center
return cluster_assessment, center
def show_cluster(dataSet, k, centroids, clusterAssement):
"""
针对二维数据进行聚类结果绘图
"""
numSamples, dim = dataSet.shape
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', '<r', 'pr']
center_mark = ['*r', '*b', '*g', '*k', '*r', '*r', '*r', '*r']
for i in range(numSamples):
markIndex = int(clusterAssement[i,0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex], markersize=2)
for j in range(k):
plt.plot(centroids[j, 0], centroids[j, 1], center_mark[j], markersize=12)
plt.show()代码测试:
x1 = np.random.randint(0, 50, (50, 2))
x2 = np.random.randint(40, 100, (50, 2))
x3 = np.random.randint(90, 120, (50, 2))
x4 = np.random.randint(110, 160, (50, 2))
test = np.vstack((x1, x2, x3, x4))
# 对特征进行聚类
result, center = kmeans(test, 4, is_kmeans=False, is_random=False)
print(center)
show_cluster(test, 4, center, result)
>>>
聚类中心点
[[134 134]
[ 21 25]
[106 104]
[ 70 64]] 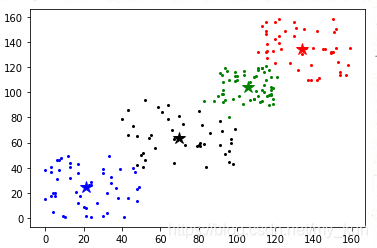

















 694
694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









