 数据库系统查询处理与优化详解
数据库系统查询处理与优化详解







 本文深入探讨了关系数据库的查询处理和优化技术,包括查询分析、查询检查、查询优化和执行策略。介绍了选择、连接操作的算法以及代数和物理优化方法,强调了查询优化在提高查询效率中的关键作用。通过实例展示了不同执行策略的代价差异,并列举了关系代数等价变换规则。此外,还提及了启发式规则和基于代价估算的优化策略,以及查询计划的执行方式。
本文深入探讨了关系数据库的查询处理和优化技术,包括查询分析、查询检查、查询优化和执行策略。介绍了选择、连接操作的算法以及代数和物理优化方法,强调了查询优化在提高查询效率中的关键作用。通过实例展示了不同执行策略的代价差异,并列举了关系代数等价变换规则。此外,还提及了启发式规则和基于代价估算的优化策略,以及查询计划的执行方式。
本文属于「数据库系统学习实践」系列文章之一,这一系列着重于「数据库系统知识的学习与实践」。由于文章内容随时可能发生更新变动,欢迎关注和收藏数据库系统系列文章汇总目录一文以作备忘。需要特别说明的是,为了透彻理解和全面掌握数据库系统,本系列文章中参考了诸多博客、教程、文档、书籍等资料,限于时间精力有限,这里无法一一列出。部分重要资料的不完全参考目录如下所示,在后续学习整理中还会逐渐补充:
- 数据库系统概念 第六版
Database System Concepts, Sixth Edition,作者是Abraham Silberschatz, Henry F. Korth, S. Sudarshan,机械工业出版社- 数据库系统概论 第五版,王珊 萨师煊编著,高等教育出版社
本章参考文献


本章介绍关系数据库的查询处理 query processing 和查询优化 query optimization 技术。首先介绍关系数据库管理系统的查询处理步骤,然后介绍查询优化技术。查询优化一般分为代数优化(也称逻辑优化)和非代数优化(也称物理优化)——代数优化是指关系代数表达式的优化,非代数优化则是指通过存取路径和底层操作算法的选择进行的优化。
本章讲解实现查询操作的主要算法思想,初步了解关系数据库管理系统查询处理的基本步骤,以及查询优化的概念、基本方法和技术,为数据库应用开发中利用查询优化技术提高查询效率和系统性能打下基础。也可以有更高的要求,比如掌握关系DBMS查询处理和查询优化的内部实现技术什么的,以后说不定会学习相关的技术细节。
特别说明,本章只关注查询语句,更一般的数据库语言(包括数据定义语言、数据操作语言、数据控制语言)的处理技术,需参考关系DBMS实现的有关文献。
9.1 关系数据库系统的查询处理
查询处理是关系数据库管理系统执行查询语句的过程,其任务是:把用户提交给关系数据库管理系统的查询语句,转换为高效的查询执行计划。查询语句是关系DBMS语言处理中最重要、最复杂的部分,查询处理是关系DBMS的核心,而查询优化又是查询处理的关键技术。
9.1.1 查询处理步骤
关系DBMS的查询处理,可以分为四个阶段:查询分析、查询检查、查询优化和查询执行。如下图所示:
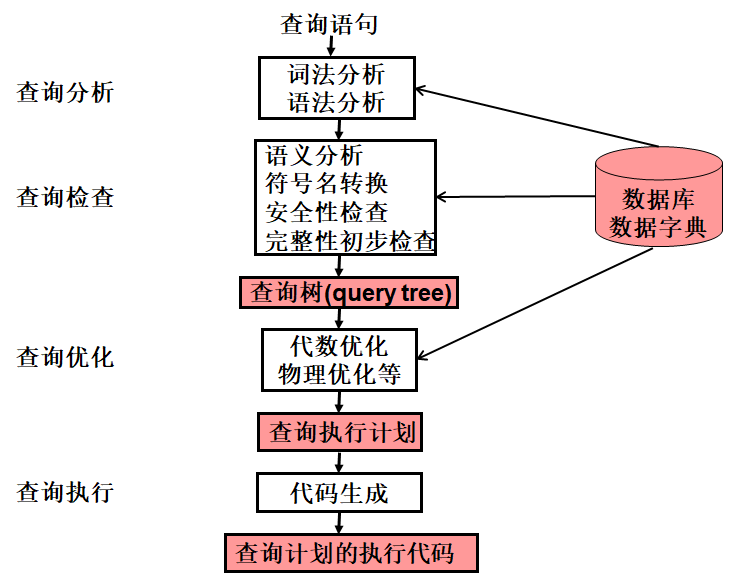
1. 查询分析
首先对查询语句进行扫描、词法分析和语法分析。从查询语句中识别出语言符号,如SQL关键字、属性名和关系名,进行语法检查和语法分析,即判断出查询语句是否符合SQL语法规则。如果没有语法错误就转入下步处理,否则报告语句中出现的语法错误。
2. 查询检查
对「合法的查询语句」进行语义检查,即根据数据字典中有关的模式定义,检查语句中的数据库对象,如关系名、属性名是否存在和有效。如果是对视图的操作,则要用视图消解方法,把对视图的操作转换为对基本表的操作。
还要根据数据字典中的用户权限、完整性约束定义,对用户的存取权限进行检查。如果该用户没有相应的访问权限、或违反了完整性约束,就拒绝执行该查询。当然,这时的完整性检查是初步的、静态的检查。
检查通过后,就把SQL查询语句转换成内部表示,即等价的关系代数表达式。这个过程中,要把数据库对象的外部名称转换为内部表示。关系数据库管理系统一般都用查询树 query tree(或称语法分析树 syntax tree )来表示扩展的关系代数表达式。
3. 查询优化
每个查询都会有许多可供选择的执行策略和操作算法,查询优化就是选择一个高效执行的查询处理策略。查询优化有多种方法,按照优化的层次一般可将查询优化分为代数优化和物理优化:
- 代数优化是指关系代数表达式的优化,即按照一定的规则,通过对关系代数表达式进行等价变换,改变代数表达式中操作的次序和组合,使查询执行更高效。
- 物理优化则是指存取路径和底层操作算法的选择。选择的依据可以是基于规则的
rule based,也可以是基于代价的cost based,还可以是基于语义的semantic based。
实际上,关系数据库管理系统中的查询优化器,都综合运用了这些优化技术,以获得最好的查询优化效果。
4. 查询执行
依据优化器得到的执行策略,先生成查询执行计划,再由代码生成器 code generator 生成执行这个查询计划的代码,然后加以执行,回送查询结果。
9.1.2 实现查询操作的算法示例
本节简单介绍选择操作和连接操作的实现算法,确切地说是算法思想。每种操作有多种执行的算法,这里仅仅介绍最主要的几个算法,对于其他重要操作的详细实现算法,有兴趣可以参考关于关系DBMS实现技术的书。
1. 选择操作的实现
第3章中介绍了 select 语句的强大功能,select 语句有许多选项,因此实现的算法和优化策略也很复杂。不失一般性,下面以简单的选择操作为例,介绍典型的实现方法。
【例9.1】对于 select * from Student where <条件表达式>; ,我们先考虑 <条件表达式> 的几种情况:
C1:无条件;C2:Sno = '201215121';C3:Sage > 20;C4:Sdept = 'CS' and Sage > 20;
选择操作只涉及一个关系,一般采用全表扫描或基于索引的算法:
(1)简单的全表扫描算法 table scan :假设可以使用的内存为
M
M
M 块,全表扫描的算法思想如下:
① 按照物理次序读 Student 的
M
M
M 块到内存;
② 检查内存中的每个元组
t
t
t ,如果
t
t
t 满足选择条件,则输出
t
t
t ;
③ 如果 Student 还有其他块未被处理,重复①和②。
全表扫描算法只需要很少的内存(最少为
1
1
1 块)就可以运行,而且控制简单。对于规模小的表,这种算法简单有效;对于规模大的表进行顺序扫描,当选择率(即满足条件的元组数占全表的比例)较低时,这个算法的效率很低。
(2)索引扫描算法 index scan
如果选择条件中的属性上有索引(例如
B
+
B^+
B+ 树索引或
h
a
s
h
hash
hash 索引),可以用索引扫描方法,通过索引先找到满足条件的元组指针,再通过元组指针在查询的基本表中找到元组。
【例9.1-C2】以 C2 为例,Sno = '201215121' ,并且 Sno 上有索引,则可以使用索引得到 Sno = '201215121' 的元组的指针,然后通过元组指针在 Student 表中检索到该学生。
【例9.1-C3】以 C3 为例,Sage > 20 ,并且 Sage 上有
B
+
B^+
B+ 树索引,则可以使用
B
+
B^+
B+ 树索引找到 Sage = 20 的索引项,以此为入口点在
B
+
B^+
B+ 树的顺序集上,得到 Sage > 20 的所有元组指针,然后通过这些元组指针到 Student 表中,检索到所有年龄大于 20 的学生。
【例9.1-C4】以 C4 为例,Sdept = 'CS' and Sage > 20 ,如果 Sdept 和 Sage 上都有索引,一种算法是,分别用上面两种方法找到 Sdept = 'CS' 的一组元组指针、Sage > 20 的另一组元组指针,求这两组指针的交集,再到 Student 表中检索,就得到计算机系年龄大于 20 岁的学生。
另一种算法是,找到 Sdept = 'CS' 的一组元组指针,通过这些元组指针到 Student 表中检索,并对得到的元组检查另一些选择条件(如 Sage > 20 )是否满足,把满足条件的元组作为结果输出。
一般情况下,当选择率较低时,基于索引的选择算法要优于全表扫描算法。但在某些情况下,例如选择率较高、或者要查找的元组均匀地分布在查找的表中,这时基于索引的选择算法的性能不如全表扫描算法。因为除了对表的扫描操作,还要加上对 B + B^+ B+ 树索引的扫描操作,对每个检索码,从 B + B^+ B+ 树根节点到叶子节点路径上的每个节点,都要执行一次I/O操作。
2. 连接操作的实现
连接操作是查询处理中最常见也最耗时的操作之一。人们对它进行了深入的研究,提出了一系列的算法。不失一般性,这里通过例子简单介绍等值连接(或自然连接)最常用的几种算法思想。
【例9.2】对于以下代码:
select *
from Student, SC
where Student.Sno = SC.Sno;
(1)嵌套循环算法 nested loop join
这是最简单可行的算法。对外层循环 Student 表的每个元组,检索内层循环 SC 表中的每个元组,并检查这两个元组在连接属性 Sno 上是否相等。如果满足连接条件,则串接后作为结果输出,直到外层循环表中的元组处理完为止。这里讲的是算法思想,在实际实现中,数据存取是按照数据块读入内存,而不是按照元组进行I/O的。嵌套循环算法是最简单、最通用的连接算法,可以处理包括「非等值连接」在内的各种连接操作。
(2)排序-合并算法 sort-merge join 或 merge join
这是等值连接常用的算法,尤其适合参与连接的诸表已经排好序的情况。 用排序-合并连接算法的步骤是:
① 如果参与连接的表没有排好序,首先对 Student 表和 SC 表按连接属性 Sno 排序;
② 取 Student 表中第一个 Sno ,依次扫描 SC 表中具有相同 Sno 的元组,把它们连接起来(如下图所示):
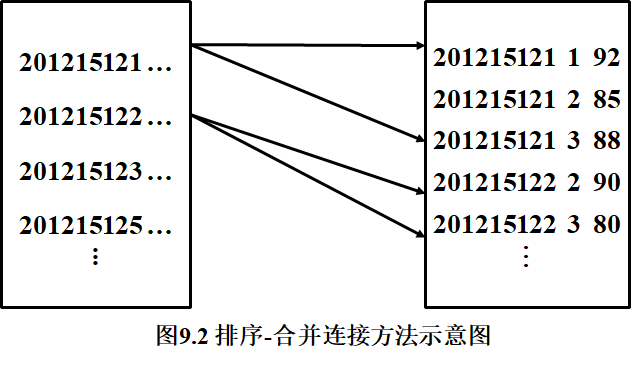 ③ 当扫描到
③ 当扫描到 Sno 不相同的第一个 SC 元组时,返回 Student 表扫描它的下一个元组,再扫描 SC 表中具有相同 Sno 的元组,把它们连接起来。
重复上述步骤,直到 Student 表扫描完成。这样对 Student 表和 SC 表都只要扫描一遍即可。当然,如果两个表原本无序,执行时间要加上对两个表的排序时间。一般来说,对于大表,先排序后使用排序-合并连接算法执行连接,总的时间一般仍会减少。
(3)索引连接算法 index join
用索引连接算法的步骤是:
① 在 SC 表上已经建立了属性 Sno 的索引;
② 对 Student 中每个元组,由 Sno 值通过 SC 的索引查找相应的 SC 元组;
③ 把这些 SC 元组和 Student 元组连接起来。
循环执行②③,直到 Student 表中的元组处理完为止。
(4)哈希连接算法 hash join
哈希连接算法也是处理等值连接的算法。它把连接属性作为 hash 键,用同一个 hash 函数,把 Student 表和 SC 表中的元组散列到 hash 表中。
① 划分阶段 building phase ,也称为创建阶段,即创建 hash 表。对包含较少元组的表(如 Student 表)进行一遍处理,把它的元组按 hash 函数(hash 键是连接属性)分散到 hash 表的桶中;
② 试探阶段 probing phase ,也称为连接阶段 join phase 。对另一个表(如 SC 表)进行一遍处理,把 SC 表的元组也按同一个 hash 函数(hash 键是连接属性)进行散列,找到适当的 hash 桶,并把 SC 元组与桶中来自 Student 表、并与之相匹配的元组连接起来。
上面的哈希连接算法,假设两个表中较小的表,在①后可以完全放入内存的 hash 桶中。不需要这个前提条件的哈希连接算法、以及许多改进的算法,请参考本章文献 [16] 。以上的算法思想,可以推广到更加一般的、多个表的连接算法上。
9.2 关系数据库系统的查询优化
查询优化在关系数据库系统中,有着非常重要的地位。关系数据库系统和非过程化的SQL,之所以能够取得巨大的成功,得益于查询优化技术的发展。关系查询优化是影响关系DBMS性能的关键因素。
优化对关系系统来说,既是机遇也是挑战。所谓挑战是指,关系系统为了达到用户可接受的性能,必须进行查询优化。由于关系表达式的语义级别很高,使关系系统可以从关系表达式中分析查询语义,提供了执行查询优化的可能性。这就为关系系统在性能上接近、甚至超越菲关系系统提供了机遇。
9.2.1 查询优化概述
关系系统的查询优化,既是关系DBMS实现的关键技术,又是关系系统的优势所在。它减轻了用户选择存取路径的负担——用户只需提出“干什么”、不必指出“怎么干”。对比一下非关系系统中的情况:用户使用过程化的语言表达查询要求,至于执行何种记录级的操作、以及操作的序列,是由用户而非系统来决定的。因此用户必须了解存取路径,系统要提供用户选择存取路径的手段,查询效率由用户的存取策略决定。如果用户做了不当的选择,系统是无法对此加以改进的。这就要求用户有较高的数据库技术和程序设计水平。
查询优化的优势,不仅在于用户不必考虑如何最好地表达查询、以获得较高的效率,而且在于系统可以比用户程序的优化做得更好。这是因为:
(1)优化器可从数据字典中获取许多统计信息,例如每个关系表中的元组数、关系中每个属性值的分布情况、哪些属性上已经建立了索引等。优化器可根据这些信息做出正确的估算,选择高效的执行计划,而用户程序则难以获取和利用这些信息。
(2)如果数据库的物理统计信息改变了,系统可以自动对查询进行重新优化、以选择相适应的执行计划。在非关系系统中则必须重写程序,而重写程序在实际应用中往往是不太可能的。
(3)优化器可考虑数百种不同的执行计划,而程序员一般只能考虑有限的几种可能性。
(4)优化器中包括了很多复杂的优化技术,这些优化技术往往只有最好的程序员才能掌握。系统的自动优化,相当于使得所有人都拥有这些优化技术。
目前,关系DBMS会通过某种代价模型,计算出各种查询执行策略的执行代价,然后选取代价最小的执行方案。在集中式数据库中,查询执行开销主要包括磁盘存取块数(I/O代价)、处理机时间(CPU代价)以及查询的内存开销。在分布式数据库中,还要加上通信代价,即:总代价=I/O代价+CPU代价+内存代价+通信代价。
由于磁盘的I/O操作涉及机械动作,需要的时间比内存操作要高几个数量级,因此,在计算查询代价时,一般用查询处理读写的块数作为衡量单位。
查询优化的总目标是选择有效的策略,求得给定关系表达式的值,使得查询代价较小。因为查询优化的搜索空间有时非常大,系统选择的实际策略不一定是最优的,而是较优的。
9.2.2 一个实例
首先通过一个简单的例子,说明为什么要进行查询优化。
【例9.3】求选修了
2
2
2 号课程的学生姓名。
答:用SQL语句表达:
select Student.Sname
from Student, SC
where Student.Sno = SC.Sno and SC.Cno = '2';
假定学生-课程数据库中有 1000 1000 1000 个学生记录、 10000 10000 10000 个选课记录,其中选修 2 2 2 号课程的选课记录为 50 50 50 个。
系统可用多种等价的关系代数表达式完成这一查询。但分析下面三种就足以说明问题了:
①
Q
1
=
∏
S
n
a
m
e
(
σ
S
t
u
d
e
n
t
.
S
n
o
=
S
C
.
S
n
o
∧
S
C
.
C
n
o
=
′
2
′
(
S
t
u
d
e
n
t
×
S
C
)
)
Q_1 = \prod_{Sname} (\large \sigma_{Student.Sno = SC.Sno\ \land \ SC.Cno = '2'}\small (Student \times SC))
Q1=∏Sname(σStudent.Sno=SC.Sno ∧ SC.Cno=′2′(Student×SC))
②
Q
2
=
∏
S
n
a
m
e
(
σ
S
C
.
C
n
o
=
′
2
′
(
S
t
u
d
e
n
t
⋈
S
C
)
)
Q_2 = \prod_{Sname} (\large \sigma_{SC.Cno = '2'} \small (Student \bowtie SC))
Q2=∏Sname(σSC.Cno=′2′(Student⋈SC))
③
Q
3
=
∏
S
n
a
m
e
(
S
t
u
d
e
n
t
⋈
σ
S
C
.
C
n
o
=
′
2
′
(
S
C
)
)
Q_3 = \prod_{Sname} (Student\bowtie \large \sigma_{SC.Cno = '2'}\small(SC))
Q3=∏Sname(Student⋈σSC.Cno=′2′(SC))
我们将看到,由于查询执行的策略不同,查询效率相差很大。
对于第一种情况,我们依次做如下计算:
- 计算广义笛卡尔积
把Student和SC的每个元组连接起来。一般连接的做法(见前文学过的四种连接算法)是:在内存中尽可能多地装入某个表(如Student表)的若干块,留出一块存放另一个表(如SC表)的部分元组;然后把「该块中的每个SC元组」和「其他块中的每个Student元组」连接,连接后的元组装满一块后,就写到中间文件上,再读入SC表的一块,和内存中的Student元组连接,直到SC表处理完毕;这时再一次读入Student表的若干块、读入SC表的一块,重复上述处理过程,直到把Student表处理完成。
设一个块能装 10 10 10 个Student元组或 100 100 100 个SC元组,在内存中存放五块Student元组和一块SC元组,则读取的总块数为 1000 10 + 1000 10 × 5 × 10000 100 = 100 + 20 × 100 = 2100 块 \dfrac{1000}{10} + \dfrac{1000}{10 \times 5} \times \dfrac{10000}{100} = 100 + 20 \times 100 = 2100块 101000+10×51000×10010000=100+20×100=2100块 其中,读Student表 100 100 100 块,读SC表 20 20 20 遍,每遍 100 100 100 块,则总计要读取 2100 2100 2100 数据块。
连接后的元组数为 1 0 3 × 1 0 4 = 1 0 7 10^3 \times 10^4 = 10^7 103×104=107 。设每块能装 10 10 10 个元组,则写出 1 0 6 10^6 106 块。 - 作选择操作
依次读入连接后的元组,按照选择条件选取满足要求的记录。假定内存处理时间忽略,这一步读取中间文件花费的时间(同写中间文件一样)需读入 1 0 6 10^6 106 块。若满足条件的元组假设仅 50 50 50 个,均可放在内存。 - 作投影操作
把第2步的结果在Sname上作投影输出,得到最终结果。
因此第一种情况下,执行查询的总读写数据块为 2100 + 1 0 6 + 1 0 6 2100 + 10^6 + 10^6 2100+106+106 。
对于第二种情况,我们依次做如下计算:
- 计算自然连接。为了执行自然连接,读取
Student和SC表的策略不变,总的读取块数仍为 2100 2100 2100 块,但自然连接的结果比第一种情况大大减少,连接后的元组数为 1 0 4 10^4 104 个元组,写出数据块为 1 0 3 10^3 103 块。 - 读取中间文件,执行选择操作,读取的数据块为 1 0 3 10^3 103 块。
- 把第2步的结果投影输出。
因此第二种情况下,执行查询的总读写数据块为 2100 + 1 0 3 + 1 0 3 2100 + 10^3 +10^3 2100+103+103 。其执行代价大约是第一种情况的 488 488 488 分之一。
对于第三种情况,我们依次做如下计算:
- 先对
SC表作选择操作,只需读一遍SC表,存取块数为 100 100 100 块,因为满足条件的元组仅 50 50 50 个,不必使用中间文件。 - 读取
Student表,把读入的Student元组和内存中的SC元组作连接。也只需读一遍Student表,共 100 100 100 块。 - 把连接结果投影输出。
第三种情况总的读写数据块为 100 + 100 100 + 100 100+100 ,其执行代价大约是第一种情况的万分之一,是第二种情况的 20 20 20 分之一。
假设 SC 表的 Cno 字段上有索引,第一步就不必读取所有的 SC 元组,而只需读取 Cno = '2' 的那些元组(
50
50
50 个),存取的索引块和 SC 中满足条件的数据块大约共
3
∼
4
3 \sim 4
3∼4 块。若 Student 表在 Sno 上也有索引,则第二步也不必读取所有的 Student 元组,因为满足条件的 SC 记录仅
50
50
50 个,涉及最多
50
50
50 个 Student 记录,因此读取 Student 表的块数也可大大减少。
这个简单的例子充分说明了查询优化的必要性,同时也给出一些查询优化方法的初步概念。
- 例如,在第一种情况下,连接后的元组可以先不立即写出,而是和下面第2步的选择操作结合,这样可以省去写出和读入的开销。
- 有选择和连接操作时,应该先做选择操作,例如,把上面的代数表达式 Q 1 , Q 2 Q_1, Q_2 Q1,Q2 变换为 Q 3 Q_3 Q3 ,这样参加连接的元组可以大大减少,这就是代数优化。
- 在
Q
3
Q_3
Q3 中,
SC表的选择操作算法可以采用全表扫描或索引扫描,经过初步估算,索引扫描方法较优。同样对于Student和SC表的连接,利用Student表上的索引,采用索引连接代价也较小,这就是物理优化。
9.3 代数优化
9.1中讲解了SQL语句经过查询分析、查询检查后变换为查询树,它是关系代数表达式的内部表示。本节介绍基于「关系代数等价变换规则」的优化方法,即代数优化。
9.3.1 关系代数表达式等价变换规则
代数优化策略是,通过对关系代数表达式的等价变换来提高查询效率。所谓关系代数表达式的等价是指,用相同的关系代替两个表达式中相应的关系,所得到的结果是相同的。两个关系表达式 E 1 , E 2 E_1, E_2 E1,E2 是等价的,可记为 E 1 ⇔ E 2 E_1 \Lrarr E_2 E1⇔E2 。下面是常用的等价变换规则,证明从略。
1. 连接、笛卡尔积的交换律
设
E
1
,
E
2
E_1, E_2
E1,E2 是关系代数表达式,
F
F
F 是连接运算的条件:
E
1
×
E
2
⇔
E
2
×
E
1
E
1
⋈
E
2
⇔
E
2
⋈
E
1
E
1
⋈
F
E
2
⇔
E
2
⋈
F
E
1
\begin{aligned} &E_1 \times E_2 \Lrarr E_2 \times E_1 \\ &E_1\bowtie E_2 \Lrarr E_2\bowtie E_1 \\ &E_1 \bowtie_F E_2 \Lrarr E_2 \bowtie_F E_1 \end{aligned}
E1×E2⇔E2×E1E1⋈E2⇔E2⋈E1E1⋈FE2⇔E2⋈FE1
2. 连接、笛卡尔积的结合律
设
E
1
,
E
2
,
E
3
E_1, E_2, E_3
E1,E2,E3 是关系代数表达式,
F
1
,
F
2
F_1, F_2
F1,F2 是连接运算的条件:
(
E
1
×
E
2
)
×
E
3
⇔
E
1
×
(
E
2
×
E
3
)
(
E
1
⋈
E
2
)
⋈
E
3
⇔
E
1
⋈
(
E
2
⋈
E
3
)
(
E
1
⋈
F
1
E
2
)
⋈
F
2
E
3
⇔
E
1
⋈
F
1
(
E
2
⋈
F
2
E
3
)
\begin{aligned} &(E_1 \times E_2) \times E_3 \Lrarr E_1 \times (E_2\times E_3) \\ &(E_1\bowtie E_2) \bowtie E_3 \Lrarr E_1 \bowtie (E_2\bowtie E_3) \\ &(E_1 \bowtie_{F_1} E_2) \bowtie_{F_2} E_3 \Lrarr E_1 \bowtie_{F_1} (E_2 \bowtie_{F_2} E_3) \end{aligned}
(E1×E2)×E3⇔E1×(E2×E3)(E1⋈E2)⋈E3⇔E1⋈(E2⋈E3)(E1⋈F1E2)⋈F2E3⇔E1⋈F1(E2⋈F2E3)
3. 投影的串接定律
设 E E E 是关系代数表达式, A i ( i = 1 , 2 , … , n ) , B j ( j = 1 , 2 , … , m ) A_i\ (i = 1, 2, \dots, n),\ B_j\ (j = 1, 2, \dots, m) Ai (i=1,2,…,n), Bj (j=1,2,…,m) 是属性名,且 { A 1 , A 2 , … , A n } \{ A_1, A_2, \dots, A_n\} {A1,A2,…,An} 构成 { B 1 , B 2 , … , B m } \{B_1, B_2, \dots, B_m\} {B1,B2,…,Bm} 的子集。 Π A 1 , A 2 , … , A n ( Π B 1 , B 2 , … , B m ( E ) ) ⇔ Π A 1 , A 2 , … , A n ( E ) \Pi_{A_1, A_2, \dots, A_n} ( \Pi_{B_1, B_2, \dots, B_m} (E)) \Lrarr \Pi_{A_1, A_2, \dots, A_n} (E) ΠA1,A2,…,An(ΠB1,B2,…,Bm(E))⇔ΠA1,A2,…,An(E)
4. 选择的串接定律
设 E E E 是关系代数表达式, F 1 , F 2 F_1, F_2 F1,F2 是选择条件。选择的串接定律说明,选择条件可以合并,这样一次就可检查全部条件。 σ F 1 ( σ F 2 ( E ) ) ⇔ σ F 1 ∧ F 2 ( E ) \sigma_{F_1} ( \sigma_{F_2}(E)) \Lrarr \sigma_{F_1 \land F_2}(E) σF1(σF2(E))⇔σF1∧F2(E)
5. 选择与投影操作的交换律
选择条件
F
F
F 只涉及属性
A
1
,
A
2
,
…
,
A
n
A_1,A_2, \dots, A_n
A1,A2,…,An :
σ
F
(
Π
A
1
,
A
2
,
…
,
A
n
(
E
)
)
⇔
Π
A
1
,
A
2
,
…
,
A
n
(
σ
F
(
E
)
)
\begin{aligned} &\sigma_F (\Pi_{A_1, A_2, \dots, A_n} (E)) \Lrarr \Pi_{A_1, A_2, \dots, A_n} (\sigma_F(E))\\ \end{aligned}
σF(ΠA1,A2,…,An(E))⇔ΠA1,A2,…,An(σF(E)) 若
F
F
F 中有不属于
A
1
,
A
2
,
…
,
A
n
A_1, A_2, \dots, A_n
A1,A2,…,An 的属性
B
1
,
B
2
,
…
,
B
m
B_1, B_2, \dots, B_m
B1,B2,…,Bm ,则有更一般的规则:
Π
A
1
,
A
2
,
…
,
A
n
(
σ
F
(
E
)
)
⇔
Π
A
1
,
A
2
,
…
,
A
n
(
σ
F
(
Π
A
1
,
A
2
,
…
,
A
n
,
B
1
,
B
2
,
…
,
B
m
(
E
)
)
)
\Pi_{A_1, A_2, \dots, A_n} (\sigma_F(E)) \Lrarr \Pi_{A_1, A_2, \dots, A_n} (\sigma_F(\Pi_{A_1, A_2, \dots, A_n, B_1, B_2, \dots, B_m} (E)))
ΠA1,A2,…,An(σF(E))⇔ΠA1,A2,…,An(σF(ΠA1,A2,…,An,B1,B2,…,Bm(E)))
6. 选择与笛卡尔积的交换律
如果
F
F
F 中涉及的属性都是
E
1
E_1
E1 中的属性,则:
σ
F
(
E
1
×
E
2
)
⇔
σ
(
E
1
)
×
E
2
\sigma_F (E_1 \times E_2) \Lrarr \sigma (E_1) \times E_2
σF(E1×E2)⇔σ(E1)×E2
如果
F
=
F
1
∧
F
2
F = F_1 \land F_2
F=F1∧F2 ,并且
F
1
F_1
F1 只涉及
E
1
E_1
E1 中的属性,
F
2
F_2
F2 只涉及
E
2
E_2
E2 中的属性,则由上面的等价变换规则1、4、6可推出:
σ
F
(
E
1
×
E
2
)
⇔
σ
F
1
(
E
1
)
×
σ
F
2
(
E
2
)
\sigma_F (E_1 \times E_2) \Lrarr \sigma_{F_1} (E_1) \times \sigma_{F_2} (E_2)
σF(E1×E2)⇔σF1(E1)×σF2(E2)
若
F
1
F_1
F1 只涉及
E
1
E_1
E1 中的属性,
F
2
F_2
F2 只涉及
E
1
,
E
2
E_1, E_2
E1,E2 两者的属性,则有如下规则,它使部分选择在笛卡尔积前先做:
σ
F
(
E
1
×
E
2
)
⇔
σ
F
2
(
σ
F
1
(
E
1
)
×
E
2
)
\sigma_F (E_1 \times E_2) \Lrarr \sigma_{F_2} (\sigma_{F_1} (E_1) \times E_2)
σF(E1×E2)⇔σF2(σF1(E1)×E2)
7. 选择对并的分配律
设
E
=
E
1
∪
E
2
E= E_1 \cup E_2
E=E1∪E2 ,
E
1
,
E
2
E_1, E_2
E1,E2 有相同的属性名,则:
σ
F
(
E
1
∪
E
2
)
⇔
σ
F
(
E
1
)
∪
σ
F
(
E
2
)
\sigma_F ({E_1 \cup E_2} ) \Lrarr \sigma_F(E_1) \cup \sigma_F(E_2)
σF(E1∪E2)⇔σF(E1)∪σF(E2)
8. 选择对差运算的分配律
若
E
1
,
E
2
E_1, E_2
E1,E2 有相同的属性名,则:
σ
F
(
E
1
−
E
2
)
⇔
σ
F
(
E
1
)
−
σ
F
(
E
2
)
\sigma_F(E_1 - E_2) \Lrarr \sigma_F(E_1) - \sigma_F(E_2)
σF(E1−E2)⇔σF(E1)−σF(E2)
9. 选择对自然连接的分配律
F
F
F 只涉及
E
1
,
E
2
E_1, E_2
E1,E2 的公共属性:
σ
F
(
E
1
⋈
E
2
)
⇔
σ
F
(
E
1
)
⋈
σ
F
(
E
2
)
\sigma_F (E_1 \bowtie E_2) \Lrarr \sigma_F (E_1) \bowtie \sigma_F (E_2)
σF(E1⋈E2)⇔σF(E1)⋈σF(E2)
10. 投影对笛卡尔积的分配律
设
E
1
,
E
2
E_1, E_2
E1,E2 是两个关系表达式,
A
1
,
A
2
,
…
,
A
n
A_1, A_2, \dots, A_n
A1,A2,…,An 是
E
1
E_1
E1 的属性,
B
1
,
B
2
,
…
,
B
m
B_1, B_2, \dots, B_m
B1,B2,…,Bm 是
E
2
E_2
E2 的属性,则:
Π
A
1
,
A
2
,
…
,
A
n
,
B
1
,
B
2
,
…
,
B
m
(
E
1
×
E
2
)
⇔
Π
A
1
,
A
2
,
…
,
A
n
(
E
1
)
×
Π
B
1
,
B
2
,
…
,
B
m
(
E
2
)
\Pi_{A_1, A_2, \dots, A_n, B_1, B_2, \dots, B_m} (E_1 \times E_2) \Lrarr \Pi_{A_1, A_2, \dots, A_n} (E_1) \times \Pi_{B_1, B_2, \dots, B_m} (E_2)
ΠA1,A2,…,An,B1,B2,…,Bm(E1×E2)⇔ΠA1,A2,…,An(E1)×ΠB1,B2,…,Bm(E2)
11. 投影对并的分配律
设
E
1
,
E
2
E_1, E_2
E1,E2 有相同的属性名,则:
Π
A
1
,
A
2
,
…
,
A
n
(
E
1
∪
E
2
)
⇔
Π
A
1
,
A
2
,
…
,
A
n
(
E
1
)
∪
Π
A
1
,
A
2
,
…
,
A
n
(
E
2
)
\Pi_{A_1, A_2, \dots, A_n} (E_1\cup E_2) \Lrarr \Pi_{A_1, A_2, \dots, A_n} (E_1) \cup \Pi_{A_1, A_2, \dots, A_n} (E_2)
ΠA1,A2,…,An(E1∪E2)⇔ΠA1,A2,…,An(E1)∪ΠA1,A2,…,An(E2)
9.3.2 查询树的启发式优化
本节讨论应用启发式规则 heuristic rules 的代数优化。这是对关系代数表达式的查询树进行优化的方法。典型的启发式规则由:
- 选择运算应尽可能先做。在优化策略中这是最重要、最基本的一条。它常常可使执行代价节约几个数量级,因为选择运算一般使计算的中间结果大大变小。
- 把投影运算和选择运算同时进行。如有若干投影和选择运算,并且它们都对同一个关系操作,则可以在扫描此关系的同时,完成所有这些运算以避免重复扫描关系。
- 把投影同其前或后的双目运算结合起来。没有必要为了去掉某些字段而重复扫描一遍关系。
- 把某些选择同在它前面要执行的笛卡尔积结合起来,成为一个连接运算。连接(特别是等值连接)运算要比同样关系上的笛卡尔积省很多时间。
- 找出公共子表达式。如果这种重复出现的子表达式的结果不是很大的关系,并且从外存中读入这个关系比计算该子表达式的时间少得多,则先计算一次公共子表达式,并把结果写入中间文件是合算的。当查询的是视图时,定义视图的表达式就是公共子表达式的一种情况。
下面给出遵循这些「启发式规则」且应用9.3.1的「等价变换公式」,优化关系表达式的具体算法,该算法的输入是「一个关系表达式的查询树」,输出是「优化的查询树」,方法如下:
(1)利用等价变换规则
4
4
4 ,把形如
σ
F
1
∧
F
2
∧
…
F
n
(
E
)
\sigma_{F_1 \land F_2 \land \dots F_n} (E)
σF1∧F2∧…Fn(E) 的表达式变换为
σ
F
1
(
σ
F
2
(
…
(
σ
F
n
(
E
)
)
…
)
)
\sigma_{F_1} (\sigma_{F_2} ( \dots (\sigma_{F_n} (E))\dots ))
σF1(σF2(…(σFn(E))…)) ;
(2)对每个选择,利用等价变换规则
4
∼
9
4\sim 9
4∼9 ,尽可能把它移到树的叶端;
(3)对每个投影,利用等价变换规则
3
,
5
,
10
,
11
3, 5, 10, 11
3,5,10,11 中的一般形式,尽可能把它移向树的叶端。注意,等价变换规则
3
3
3 使一些投影消失、规则
5
5
5 把一个投影分裂为两个,其中一个有可能被移向树的叶端;
(4)利用等价变换规则
3
∼
5
3 \sim 5
3∼5 ,把选择和投影的串接合并成单个选择、单个投影或一个选择后跟一个投影,使多个选择或投影能同时执行,或在一次扫描中全部完成。尽管这种变换似乎违背「投影尽可能早做」的原则,但这样做效率更高。
(5)把上述得到的语法树的内节点分组。每一双目运算
×
,
⋈
,
∪
,
−
\times, \bowtie, \cup , -
×,⋈,∪,− 和它的所有直接祖先为一组(这些直接祖先是
σ
,
Π
\sigma, \Pi
σ,Π 运算)。如果其后代直到叶子全是单目运算,则也将它们并入该组,但当双目运算是笛卡尔积
×
\times
× 时,而且后面不是与它组成等值连接的选择时,则不能把选择与这个双目运算组成同一组。把这些单目运算单独分为一组。(?)
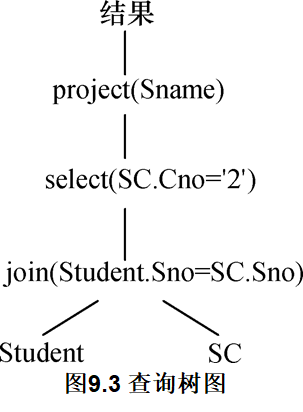
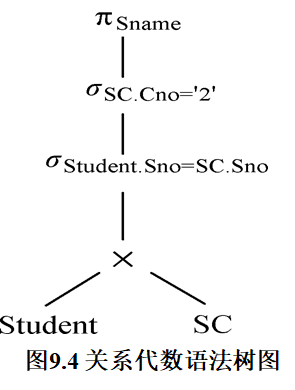
【例9.4】下面给出例9.3中SQL语句的代数优化示例。
select Student.Sname
from Student, SC
where Student.Sno = SC.Sno and SC.Cno = '2';
答:具体过程如下:
(1)把SQL语句转换成查询树,如图9.3所示。为了使用关系代数表达式的优化法,不妨假设内部表示是关系代数语法树,则上面的查询树如图9.4所示:
(2)对查询树进行优化。利用规则
4
,
6
4, 6
4,6 把选择
σ
S
C
.
C
n
o
=
′
2
′
\sigma_{SC.Cno = '2'}
σSC.Cno=′2′ 移到叶端,图9.4查询树就转换成下图优化的查询树。这就是9.2.2节中
Q
3
Q_3
Q3 的查询树表示。前面已经分析了,
Q
3
Q_3
Q3 比
Q
1
,
Q
2
Q_1, Q_2
Q1,Q2 查询效率要高得多:
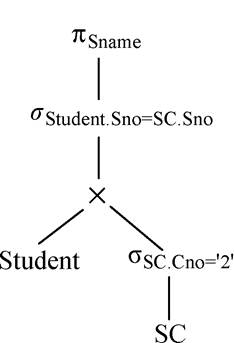
9.4 物理优化
代数优化改变查询语句中操作的次序和组合,但不涉及底层的存取路径。9.1.2节中已介绍了,对每种操作有多种执行这一操作的算法,有多条存取路径,因此对于一个查询语句有许多存取方案,它们的执行效率不同,有的会相差很大。因此,仅仅进行代数优化是不够的,物理优化就是要选择高效合理的操作算法或存取路径,求得优化的查询计划,达到查询优化的目标。
选择的方法可以是:
(1)基于规则的启发式优化。启发式规则是指那些在大多数情况下都适用、但不是在每种情况下都是最好的规则。
(2)基于代价估算的优化。使用优化器估算不同执行策略的代价,并选出具有最小代价的执行计划。
(3)两者结合的优化方法。查询优化器通常会把这两种技术结合在一起使用,因为可能的执行策略很多,要穷尽所有的策略、进行代价估算往往是不可行的,会造成查询优化本身付出的代价大于获得的益处。为此,常常先使用启发式规则,选取若干较优的候选方案,减少代价估算的工作量;然后分别计算这些候选方案的执行代价,较快地选出最终的优化方案。
9.4.1 基于启发式规则的存取路径选择优化
1. 选择操作的启发式规则
对于小关系,使用全表顺序扫描,即使选择列上有索引。对于大关系,启发式规则有:
- 对于选择条件是「主键=值」的查询,查询结果最多是一个元组,可以选择主键索引。一般的关系数据库管理系统会自动建立主键索引。
- 对于选择条件是「非主键属性=值」的查询,并且选择列上有索引,则要估算查询结果的元组数目,如果比例较少( < 10 % < 10\% <10%)可以使用索引扫描方法,否则还是使用全表顺序扫描。
- 对于选择条件是「属性上的非等值查询或范围查询」,并且选择列上有索引,同样估算查询结果的元组数目,如果选择率较少( < 10 % < 10\% <10%)可以使用索引扫描方法,否则还是使用全表顺序扫描。
- 对于用
and连接的合取选择条件,如果有涉及这些属性的组合索引,则优先采用组合索引扫描方法;如果某些属性上有一般索引,则可用【例9.1-C4】中介绍的索引扫描方法,否则使用全表顺序索引。 - 对于用
or连接的析取选择条件,一般使用全表顺序扫描。
2. 连接操作的启发式规则
连接操作的启发式规则有:
- 如果2个表都已经按照连接属性排序,则选用排序-合并算法;
- 如果一个表在连接属性上有索引,则可选用索引-连接算法;
- 如果上面2个规则都不适用,其中一个表较小,则可选用
hash join算法; - 最后可以选用嵌套循环算法,并选中其中较小的表,确切地说是占用的块数(
B
B
B)较少的表,作为外表(外循环的表)。理由如下:
设连接表 R R R 与 S S S 分别占用的块数为 B r Br Br 和 B s Bs Bs ,连接操作使用的内存缓冲区块数为 K K K ,分配 K − 1 K - 1 K−1 块给外表。如果 R R R 为外表,则嵌套循环法存取的块数为 B r + B r B s / ( K − 1 ) Br + BrBs / (K - 1) Br+BrBs/(K−1) ,显然应该选块数小的表作为外表。
上面列出了一些主要的启发式规则,在实际的关系数据库管理系统中,启发式规则要多得多。
9.4.2 基于代价估算的优化
启发式规则优化是定性的选择,比较粗糙,但是实现简单而且优化本身的代价较小,适合解释执行的系统——因为解释执行的系统,其优化开销包含在查询总开销之中。在编译执行的系统中,一次编译优化、多次执行,查询优化和查询执行是分开的。因此,可以采用精细复杂一些的、基于代价的优化方法。
1. 统计信息
基于代价的优化方法,要计算各种操作算法的执行代价,它与数据库的状态密切相关。为此,在数据字典中存储了优化器需要的统计信息 database statistics ,主要包括如下几个方面:
(1)对每个基本表,该表的元组总数
N
N
N 、元组长度
l
l
l 、占用的块数
B
B
B 、占用的溢出块数
B
O
BO
BO ;
(2)对基本表中的每个列,该列不同值的个数
m
m
m 、该列最大值、最小值,该列上是否已经建立了索引,是哪种索引(
B
+
B^+
B+ 索引、
h
a
s
h
hash
hash 索引、聚集索引)。根据这些统计信息,可以计算出谓词条件的选择率
f
f
f ,如果不同值的分布是均匀的,
f
=
1
m
f = \dfrac{1}{m}
f=m1 ;如果不同值的分布不均匀,则要计算每个值的选择率,
f
=
f =
f= 具有该值的元组数
/
N
/ N
/N 。
(3)对索引,例如对
B
+
B^+
B+ 树索引要记录这些信息:该索引的层数
L
L
L 、不同索引值的个数、索引的选择基数
S
S
S(有
S
S
S 个元组具有某个索引值)、索引的叶节点数
Y
Y
Y 。
……
2. 代价估算示例
下面给出若干操作算法的执行代价估算。
(1)全表扫描算法的代价估算公式
- 如果基本表大小为 B B B 块,全表扫描算法的代价 c o s t = B cost = B cost=B
- 如果选择条件是「键=值」,那么平均搜索代价 c o s t = B / 2 cost = B / 2 cost=B/2
(2)索引扫描算法的代价估算公式
- 如果选择条件是「键=值」,例如【例9.1-C2】,则采用该表的主索引,若为 B + B^+ B+ 树,层数为 L L L ,需要存取 B + B^+ B+ 树中从根节点到叶节点 L L L 块,再加上基本表中该元组所在的那一块,所以 c o s t = L + 1 cost = L+ 1 cost=L+1
- 如果选择条件涉及非键属性,如【例9.1-C3】,若为 B + B^+ B+ 树索引,选择条件是相等比较, S S S 是索引的选择基数。因为满足条件的元组可能会保存在不同的块上,所以(最坏的情况) c o s t = L + S cost = L + S cost=L+S
- 如果比较条件是 > , ≥ , < , ≤ >, \ge, <, \le >,≥,<,≤ 操作,假设有一半的元组满足条件,那么就要存取一半的叶节点,并通过索引访问一半的表存储块。所以 c o s t = L + Y / 2 + B / 2 cost = L + Y / 2 + B/ 2 cost=L+Y/2+B/2 。如果可以获得更准确的选择基数,可以进一步修正 Y / 2 Y / 2 Y/2 与 B / 2 B/ 2 B/2 。
(3)嵌套循环连接算法的代价估算公式
9.4.1中已经讨论过了嵌套循环连接算法的代价
c
o
s
t
=
B
r
+
B
r
B
s
/
(
K
−
1
)
cost = Br + BrBs / (K - 1)
cost=Br+BrBs/(K−1) 。如果需要把连接结果写回磁盘,则
c
o
s
t
=
B
r
+
B
r
B
s
(
K
−
1
)
+
(
F
r
s
×
N
r
×
N
s
)
/
M
r
s
)
cost = Br + BrBs(K - 1) + (Frs \times Nr \times Ns) / Mrs)
cost=Br+BrBs(K−1)+(Frs×Nr×Ns)/Mrs) ,其中
F
r
s
Frs
Frs 为连接选择率 join selectivity ,表示连接结果元组数的比例,
M
r
s
Mrs
Mrs 是存放连接结果的块因子,表示每块中可以存放的结果元组数目。
(4)排序-合并连接算法的代价估算公式
- 如果连接表已经按照连接属性排好序,则 c o s t = B r + B s + ( F r s × N r × N s ) / M r s cost = Br + Bs+ (Frs \times Nr\times Ns) / Mrs cost=Br+Bs+(Frs×Nr×Ns)/Mrs ;
- 如果必须对文件排序,那么还需要在代价函数中加上排序的代价。对于包含 B B B 个块的文件,排序的代价大约是 2 B + 2 B log 2 B 2B+ 2B\log_2B 2B+2Blog2B ;
上面仅仅列出了少数操作算法的代价估算示例,在实际的关系数据库管理系统中,代价估算公式要多得多,也复杂得多。
前面还提到了一种优化的方法,称为语义优化。这种技术根据数据库的语义约束,把原先的查询转换成另一个执行效率更高的查询。本章不对这种方法进行详细讨论,只用一个简单的例子说明它。考虑【例9.1】的SQL查询:
select *
from Student
where Sdept = 'CS' and Sage > 200;
显然,用户在写年龄值 Sage 时,误把
20
20
20 写成了
200
200
200 。假设数据库模式上定义了一个约束,要求学生年龄在
15
∼
55
15 \sim 55
15∼55 岁之间。一旦查询优化器检查到了这条约束,它就知道上面查询的结果为空,所以根本不用执行这个查询。
9.5 查询计划的执行*
查询优化完成后,关系DBMS为用户查询生成了一个查询计划,该查询计划的执行可以分为「自顶向下」和「自底向上」两种执行方法:
- 在自顶向下的执行方式中,系统反复向查询计划顶端的操作符,发出需要查询结果元组的请求。操作符收到请求后,就试图计算下一个(或几个)元组并返回这些元组。在计算时,如果操作符的输入缓冲区为空,它就会向其孩子操作符发送需求元组的请求……这种需求元组的请求会一直传到叶子节点,启动叶子操作符运行,并返回其父操作符一个(或几个)元组,父操作符再计算自己的输出、并返回给上层操作符,直至顶端操作符。重复这一过程,直到处理完整个关系。
- 在自底向上的执行方式中,查询计划从叶节点开始执行,叶节点操作符不断地产生元组,并将它们放入其输出缓冲区中,直至缓冲区填满为止,这时它必须等待其父操作符将元组从该缓冲区中取走,才能继续执行。然后其父节点操作符开始执行,利用下层的输入元组来产生它自己的输出元组,直到其输出缓冲区满为止。重复这一过程,直到产生所有的输出元组。
显然,自顶向下的执行方式是一种被动的、需求驱动的执行方式,而自底向上的执行方式是一种主动的执行方式。详细介绍需参阅关系DBMS实现的有关文献(如 [16] )。
9.6 最后
对于比较复杂的查询,尤其是涉及连接和嵌套的查询,不要把优化的任务全部放在关系DBMS上,应找出关系DBMS的优化规律,以写出适合关系DBMS自动优化的SQL语句。对于关系DBMS不能优化的查询,需要重写查询语句,进行手工调制以优化性能。
如有时间,可以完成相应实验——使用 explain 命令分析查询执行计划,掌握数据库监视和性能优化的原理和方法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











