






 本文详细介绍数据库编程技术,包括嵌入式SQL、过程化SQL、存储过程、自定义函数、ODBC编程、OLEDB编程和JDBC编程等内容。通过具体示例讲解了不同编程方式的特点和应用场景。
本文详细介绍数据库编程技术,包括嵌入式SQL、过程化SQL、存储过程、自定义函数、ODBC编程、OLEDB编程和JDBC编程等内容。通过具体示例讲解了不同编程方式的特点和应用场景。
本文属于「数据库系统学习实践」系列文章之一,这一系列着重于「数据库系统知识的学习与实践」。由于文章内容随时可能发生更新变动,欢迎关注和收藏数据库系统系列文章汇总目录一文以作备忘。需要特别说明的是,为了透彻理解和全面掌握数据库系统,本系列文章中参考了诸多博客、教程、文档、书籍等资料,限于时间精力有限,这里无法一一列出。部分重要资料的不完全参考目录如下所示,在后续学习整理中还会逐渐补充:
- 数据库系统概念 第六版
Database System Concepts, Sixth Edition,作者是Abraham Silberschatz, Henry F. Korth, S. Sudarshan,机械工业出版社- 数据库系统概论 第五版,王珊 萨师煊编著,高等教育出版社
建立数据库后,就要开发应用系统了。本章讲解在应用系统中如何使用编程方法,对数据库进行操纵的技术。
标准化SQL是非过程化的查询语言,具有操纵统一、面向集合、功能丰富、使用简单等多项优点。但和程序设计语言相比,高度非过程化的优点也造成了它的弱点:缺少流程控制能力,难以实现应用业务中的逻辑控制。SQL编程技术可以有效克服SQL语言实现复杂应用方面的不足,提高应用系统和数据库管理系统间的互操作性。
在应用系统中使用SQL编程,访问和管理数据库中数据的方式主要有:嵌入式SQL Embedded SQL, ESQL 、过程化SQL Procedural Language/SQL, PL/SQL 、存储过程和自定义函数、开放数据库互连 Open Data Base Connectivity, ODBC 、OLE DB Object Linking and Embedding DB 、Java数据库连接 Java Data Base Connectivity, JDBC 等编程方式。本章将介绍这些编程技术的概念和方法。
本章参考文献

8.1 嵌入式SQL
这部分内容比较多,见【数据库系统】第二部分 设计与应用开发(8) 数据库编程(1) 嵌入式SQL。
8.2 过程化SQL
SQL 99标准支持过程和函数的概念,SQL可以使用程序设计语言来定义过程和函数,也可以用关系DBMS自己的过程语言来定义。Oracle的PL/SQL、Microsoft SQL Server的Transact-SQL、IBM DB2的SQL PL、Kingbase的PL/SQL都是过程化的SQL编程语言。本节介绍过程化SQL Procedural Language/SQL, PL/SQL 。
8.2.1 过程化SQL的块结构
基本的SQL是高度非过程化的语言。嵌入式SQL将SQL语句嵌入程序设计语言,借助高级语言的控制功能实现过程化;过程化SQL则是对SQL的扩展,使其增加了过程化语句功能。
过程化SQL程序的基本结构是块。所有的过程化SQL程序,都是由块组成的。这些块之间可以互相嵌套,每个块完成一个逻辑操作。下面是过程化SQL块的基本结构:
定义部分:
declare /* 定义的变量、常量等只能在该基本块中使用 */
变量、常量、游标、异常等 /* 当基本块执行结束时,定义就不再存在 */
执行部分:
begin
SQL语句、过程化SQL的流程控制语句
exception/except /* 遇到不能继续执行的情况称为异常 */
异常处理部分 /* 在出现异常时,采取措施来纠正错误或报告 */
end;
8.2.2 变量和常量的定义
1. 变量定义
变量名 数据类型 [[not null] := 初值表达式] 或
变量名 数据类型 [[not null] 初值表达式
2. 常量定义
常量必须要给一个值,并且该值在存在期间或常量的作用域内不能改变。如果试图修改它,过程化SQL将返回一个异常。
常量名 数据类型 constant := 常量表达式
3. 赋值语句
变量名 := 表达式
8.2.3 流程控制
过程化SQL提供了流程控制语句,主要有条件控制和循环控制语句。这些语句的语法、语义和一般的高级语言(如C语言)类似,只做概要的介绍。使用时,要参考具体产品手册的语法规则。
1. 条件控制语句
一般有三种形式的 IF 语句:IF-THEN 语句、IF-THEN_ELSE 语句和嵌套的 IF 语句:
(1)IF-THEN 语句:
if condition then
sequence_of_statements; /* 条件为真时语句序列才被执行 */
end if; /* 条件为假或null时什么也不做,控制转移到下一个语句 */
(2)IF-THEN-ELSE 语句:
if condition then
sequence_of_statements1; /* 条件为真时执行语句序列1 */
else
sequence_of_statements2; /* 条件为假或null时执行语句序列2 */
end if;
(3)嵌套的 IF 语句:
在 THEN 和 ELSE 子句中,还可以再包含 IF 语句,即 IF 语句可以嵌套。
2. 循环控制语句
过程化SQL有三种循环结构:LOOP 、WHILE_LOOP 和 FOR-LOOP 。
(1)最简单的循环语句 LOOP :多数数据库服务器的过程化SQL都提供 EXIT 、BREAK 或 LEAVE 等循环结束语句,以保证 LOOP 语句块能够在适当的条件下提前结束。
loop
sequence_of_statements; /* 循环体,一组过程化SQL语句 */
end loop;
(2)WHILE-LOOP 循环语句:每次执行循环体语句之前,首先要对条件进行求值,如果条件为真则执行循环体内的语句序列,如果条件为假则跳过循环、并把控制传递给下一个语句。
while condition loop
sequence_of_statements; /* 条件为真时执行循环体内的语句序列 */
end loop;
(3)FOR-LOOP 循环语句:基本执行过程是,将 count 设置为循环的下界 bound1 ,检查它是否小于上界 bound2 ;当指定 REVERSE 时则将 count 设置为循环的上界 bound2 ,检查 count 是否大于下界 bound1 。如果越界则跳出循环,否则执行循环体,然后按照步长(
+
1
+1
+1 或
−
1
-1
−1)更新 count 的值,重新判断条件。
for count in [reverse] bound1 .. bound2 loop
sequence_of_statements
end loop;
3. 错误处理
如果过程化SQL在执行时出现异常,则应该让程序在产生异常的语句处停下来,根据异常的类型去执行异常处理语句。
SQL标准对数据库服务器提供什么样的异常处理做出了建议,要求过程化SQL管理器提供完善的异常处理机制。相对于嵌入式SQL简单地提供执行状态信息 SQLCODE ,这里的异常处理就复杂多了,要根据具体系统的支持情况来进行错误处理。
8.3 存储过程和函数
过程化SQL块主要有两种类型,即命名块和匿名块。前面介绍的都是匿名块,匿名块每次执行时都要进行编译,不能被存储到数据库中,也不能在其他过程化SQL块中调用。
过程和函数是命名块,它们被编译后保存在数据库中,称为持久性存储模块 persistent stored module, PSM ,可被反复调用,运行速度较快。SQL 2003标准支持SQL/PSM。
8.3.1 存储过程
存储过程是由过程化SQL语句书写的过程,这一过程经编译和优化后,存储在数据库服务器中,因此称它为存储过程,使用时只要调用即可。
1. 存储过程的优点
使用存储过程具有以下优点:
(1)由于存储过程不像解释执行的SQL语句那样,要在提出操作请求时才进行语法分析和优化工作,因而运行效率高,提供了在服务器端快速执行SQL语句的有效途径。
(2)存储过程降低了客户机和服务器之间的通信量。客户机上的应用程序只要通过网络向服务器发出调用存储过程的名字和参数,就可以让关系DBMS执行其中的多条SQL语句,并进行数据处理。只有最终的处理结果才返回客户端。
(3)方便实施企业规则。可以把企业规则的运算程序写成存储过程,放入数据库服务器中,由关系DBMS管理,既有利于集中控制,又能够方便地进行维护。当企业规则发生变化时,只要修改存储过程即可,无须修改其他应用程序。
2. 存储过程的用户接口
用户通过下面的SQL语句创建、执行、修改和删除存储过程。
(1)创建存储过程:存储过程包括过程首部和过程体。在过程首部,「过程名」是数据库服务器合法的对象标识;「参数列表」用名字来标识调用时给出的参数值,必须指定值的数据类型,可以定义输入参数、输出参数或输入/输出参数,默认为输入参数,也可以无参数;「过程体」是一个 <过程化SQL块> ,包括声明部分和可执行语句部分,其基本结构已在8.2节中讲解了。
create or replace procedure 过程名([参数1, 参数2, ...]) /* 存储过程首部 */
as <过程化SQL块>; /* 存储过程体, 描述该存储过程的操作 */
【例8.9】利用存储过程实现下面的应用,从账户
1
1
1 转指定数额的款项到账户
2
2
2 中。假设账户关系表为 Account(AccountNum, Total) 即账户号、账户余额。
答:存储过程如下:
/* 定义存储过程transfer, 其参数为转入账户、转出账户、转账额度 */
create or replace procedure
transfer(inAccount int, outAccount, int, amount float)
as
declare
totalDepositOut float;
totalDepositIn float;
inAccountNum int;
begin
/* 检查转出账户的余额 */
select Total into totalDepositOut
from Account
where AccountNum = outAccount;
if totalDepositOut is null then /* 如果转出账户不存在或账户中没有存款 */
rollback; /* 回滚事务 */
return;
end if;
if totalDepositOut < amount then /* 如果账户存款不足 */
rollback; /* 回滚事务 */
return;
end if;
/* 检查转入账户是否存在 */
select AccountNum into inAccountNum
from Account
where AccountNum = inAccount;
if inAccountNum is null then /* 如果转入账户不存在 */
rollback; /* 回滚事务 */
return;
end if;
/* 修改转出账户的余额, 减去转出额 */
update Account
set Total = Total - amount
where AccountNum = outAccount;
/* 修改转入账户的余额, 增加转入额 */
update Account
set Total = Total + amount
where AccountNum = inAccount;
/* 提交转账事务 */
commit;
end;
(2)执行存储过程:使用 call 或 perform 等方式激活存储过程的执行。在过程化SQL中,数据库服务器支持在过程体中调用其他存储过程。
call/perform procedure 过程名([参数1, 参数2, ...]);
【例8.10】从账户
0100
3815
868
0100\ 3815\ 868
0100 3815 868 转
10
000
10\ 000
10 000 元到
0100
3813
828
0100\ 3813\ 828
0100 3813 828 账户中。
答:
call procedure transfer(01003815868, 01003813828, 10000);
(3)修改存储过程:可用 alter procedure 重命名一个存储过程;也可用 alter procedure 重新编译一个存储过程:
alter procedure 过程名1 rename to 过程名2;
alter procedure 过程名 compile;
(4)删除存储过程:
drop procedure 过程名();
8.3.2 函数
此处讲解的函数也称为自定义函数,因为是用户自己使用过程化SQL设计定义的。函数和存储过程类似,都是持久性存储模块;函数的定义和存储过程也类似;不同之处是函数必须指定返回的类型。
1. 函数定义语句的格式
create or replace function
函数名([参数1, 参数2, ...]) returns <类型>
as <过程化SQL块>;
2. 函数执行语句的格式
call/select 函数名([参数1, 参数2, ...]);
3. 修改函数
可用 alter function 重命名一个自定义函数;也可用 alter function 重新编译一个函数:
alter function 函数名1 rename to 函数名2;
alter function 函数名 compile;
由于函数的概念与存储过程类似,这里就不再赘述了。有关示例可参考资料 [4] 。
8.3.3 过程化SQL中的游标
和嵌入式SQL一样,在过程化SQL中,如果 select 语句只返回一条记录,可将该结果存放到变量中。当查询返回多条记录时,就要使用游标对结果集合进行处理。一个游标与一个SQL语句相关联。在存储过程中,我们可以定义普通游标、RefCursor 类型游标、带参数的游标等。游标的概念已在8.1节中介绍过了,稍有差别的是过程化SQL存储过程中的语句格式,(限于篇幅)这里仅给出带参数游标的示例。
【例8.11】定义一个存储过程,多次打开游标并获取游标的当前记录。
答:过程体中打开 mycursor 后,将检索到的游标记录插入临时表中,两次打开时使用的游标参数不同,临时表中先后增加了 'L01' 和 'L02' 对应的 Leader 记录。
create or replace procedure
proc_cursor()
as
declare
cno char(3);
cname char(8);
cursor mycursor(LeaderNo char(3)) for /* 说明带参数游标mycursor */
select Lno, Lnam /* mycursor能检索Leader表中具有参数LeaderNo的记录 */
from Leader
where Lno = LeaderNo;
begin
open mycursor('L01'); /* 使用参数'L01'打开游标 */
fetch mycursor into cno, cname; /* 获取Lno='L01'的游标元组 */
insert into temp(Lno, Lname)
values(cno, cname); /* 将游标元组插入临时表中 */
close mycursor; /* 关闭游标 */
open mycursor('L02'); /* 使用新的参数'L02'重新打开游标 */
fetch mycursor into cno, cname;
insert into temp(Lno, Lname)
values(cno, cname);
close mycursor;
end;
8.4 ODBC编程
本节介绍如何使用 ODBC 来进行数据库应用程序的设计。使用 ODBC 编写的应用程序可移植性好、能同时访问不同的数据库、共享多个数据资源。
8.4.1 ODBC概述
提出和产生ODBC的原因很简单,因为存在不同的数据库管理系统——目前广泛使用的关系数据库管理系统有很多种,尽管它们都属于关系数据库,也都遵循SQL标准,但是不同系统有许多差异。因此,在某个关系DBMS下编写的应用程序,并不能在另一个关系DBMS下运行,适应性和可移植性较差。例如,运行在Oracle上的应用程序,要在KingbaseES上运行,就必须进行修改移植。这种修改移植比较繁琐,开发人员必须清楚地了解不同关系DBMS的区别,细心地一一进行修改、测试。
更重要的是,许多应用程序需要共享多个部分的数据资源,访问不同的关系数据库管理系统。为此,人们开始研究和开发连接不同关系DBMS的方法、技术和软件,使数据库系统开放、能够实现数据互联。其中,ODBC就是为了解决这样的问题、而由微软推出的接口标准,是微软开放服务体系 Windows Open Services Architecture, WOSA 中有关数据库的一个组成部分。它建立了一组规范,提供了一组访问数据库的应用程序编程接口 Application Programming Interface, API 。ODBC具有两重功效或约束力:一方面规范应用开发,另一方面规范关系DBMS的应用接口。
8.4.2 ODBC工作原理概述
ODBC应用系统的体系结构如下图所示,它由四部分构成:用户应用程序、ODBC驱动程序管理器、数据库驱动程序、数据源(如关系DBMS和数据库)。
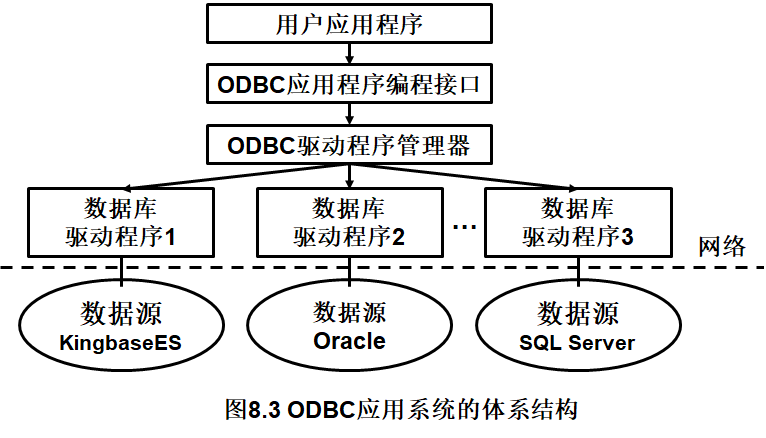
1. 用户应用程序
用户应用程序提供用户界面、应用逻辑和事务逻辑。使用ODBC开发数据库应用程序时,应用程序调用的是标准的ODBC函数和SQL语句。应用层使用ODBC API调用接口,与数据库进行交互。使用ODBC来开发应用系统的程序,简称为ODBC应用程序,包括的内容有:
- 请求连接数据库;
- 向数据源发送SQL语句;
- 为SQL语句的执行结果分配存储空间,定义所读取的数据格式;
- 获取数据库操作结果,或处理错误;
- 进行数据处理,并向用户提交处理结果;
- 请求事务的提交和回滚操作;
- 断开与数据源的连接
2. ODBC驱动程序管理器
驱动程序管理器用来管理各种驱动程序。ODBC驱动程序管理器由微软提供,它包含在 ODBC32.dll 中,对用户是透明的,管理应用程序和驱动程序之间的通信。
ODBC驱动程序管理器的主要功能包括:
- 装载ODBC驱动程序;
- 选择和连接正确的驱动程序;
- 管理数据源,建立、配置或删除数据源;
- 检查ODBC调用参数的合法性;
- 记录ODBC函数的调用;
- 当应用层需要时,查看系统当前所安装的数据库ODBC驱动程序,并返回驱动程序的有关信息
3. 数据库驱动程序
ODBC通过数据库驱动程序,提供应用系统与数据库平台的独立性。ODBC应用程序不能直接存取数据库,其各种操作请求先经过驱动程序管理器,提交给某个关系DBMS的ODBC驱动程序;再通过调用驱动程序所支持的函数,实际存取数据库;得到的数据库的操作结果,也通过驱动程序返回给应用程序。如果应用程序要操纵不同的数据库,就要动态地链接到不同的驱动程序上。
目前的ODBC驱动程序,主要分为单束和多束两类:
- 单束一般是数据源和应用程序在同一台机器上,驱动程序直接完成对数据文件的I/O操纵,这时驱动程序相当于数据管理器。
- 多束下的驱动程序,支持客户机-服务器、客户机-应用服务器/数据库服务器等网络环境下的数据访问,这时,由驱动程序完成数据库访问请求的提交和结果集接收,应用程序使用驱动程序提供的结果集管理接口,操纵执行后的结果数据。
4. ODBC数据源管理
数据源是用户最终需要访问的数据,包含了数据库位置、数据库类型等信息,实际上是一种数据连接的抽象。
ODBC给每个被访问的数据源,指定唯一的数据源名 Data Source Name, DSN ,并映射到所有必要的、用来存取数据的底层软件。在连接中,用数据源名来代表用户名、服务器名、所连接的数据库名等。用户无须知道数据库管理系统或其他数据管理软件、网络以及有关ODBC驱动程序的细节,数据源对终端用户是透明的。
例如,假设某个学校在SQL Server和KingbaseES上创建了两个数据库:学校人事数据库和教学科研数据库。学校的信息系统要从这两个数据库中存取数据,为了方便地与两个数据库连接,为学校人事数据库创建一个数据源名 PERSON ,同样为教学科研数据库创建一个名为 EDU 的数据源名。此后,当要访问每一个数据库时,只要与 PERSON 和 EDU 数据源连接即可,不需要记住使用的驱动程序、服务器名称、数据库名称等。所以,在开发ODBC数据库应用程序时,首先要建立数据源并给它命名。
8.4.3 ODBC API基础
各个数据库厂商的ODBC应用程序编程接口 ODBC API ,都要符合两个方面的一致性:
- API一致性,包括核心级、扩展1级、扩展2级;
- 语法一致性,包括最低限度SQL语法级、核心SQL语法级、扩展SQL语法级
1. 函数概述
ODBC 3.0标准提供了76个函数接口,大致可以分为:
- 分配和释放环境句柄、连接句柄、语句句柄;
- 连接函数(
SQLDriverconnect等); - 与信息相关的函数(
SQLGetinfo、SQLGetFunction等); - 事务处理函数(
SQLEndTran等); - 执行相关函数(
SQLExecdirect、SQLExecute等); - 编目函数,ODBC 3.0提供了11个编目函数,如
SQLTables、SQLColumn等。应用程序可通过对编目函数的调用,获取数据字典的信息,如权限、表结构等。
注意:ODBC不同版本上的函数和函数的使用是有差异的!使用者必须注意使用的版本!
2. 句柄及其属性
句柄是32位整数值,代表一个指针。ODBC 3.0中,句柄可以分为环境句柄、连接句柄、语句句柄和描述符句柄四类,对于每种句柄,不同的驱动程序有不同的数据结构,这四种句柄的关系如下图所示:
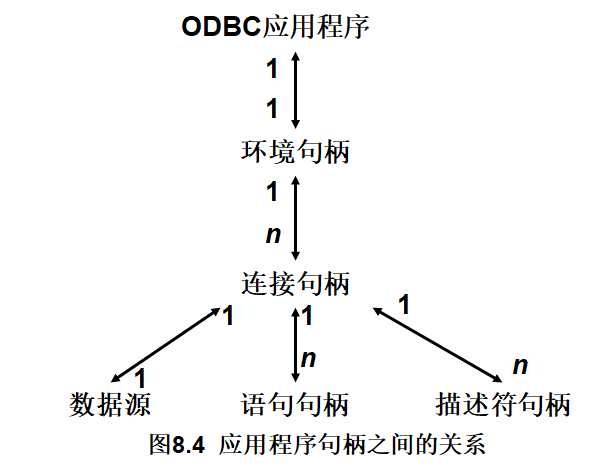
(1)每个ODBC应用程序,需要建立一个ODBC环境,分配一个环境句柄,存取数据的全局性背景,如环境状态、当前环境状态诊断、当前在环境上分配的连接句柄等。
(2)一个环境句柄可以建立多个连接句柄,每个连接句柄实现与一个数据源之间的连接。
(3)在一个连接中,可以建立多个语句句柄,它不只是一个SQL语句,还包括SQL语句产生的结果集、以及相关的信息等。
(4)在ODBC 3.0中又提出了描述符句柄的概念, 它是描述SQL语句的参数和结果集列的元数据集合。
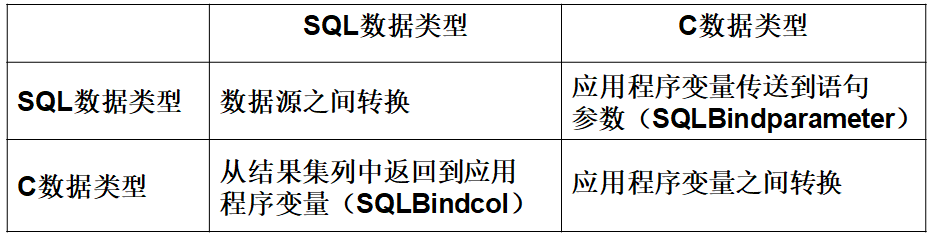
3. 数据类型
ODBC定义了两套数据类型,即SQL数据类型和C数据类型,SQL数据类型用于数据源,而C数据类型用于应用程序的C代码。它们之间的转换规则如下表所示。SQL数据通过 SQLBindcol 从结果集列中返回到应用程序变量;如果SQL语句含有参数,应用程序为每个参数调用 SQLBindparameter ,并把它们绑定至应用程序变量。应用程序可以通过 SQLGetTypeInfo ,获取不同驱动程序对数据类型的支持情况。
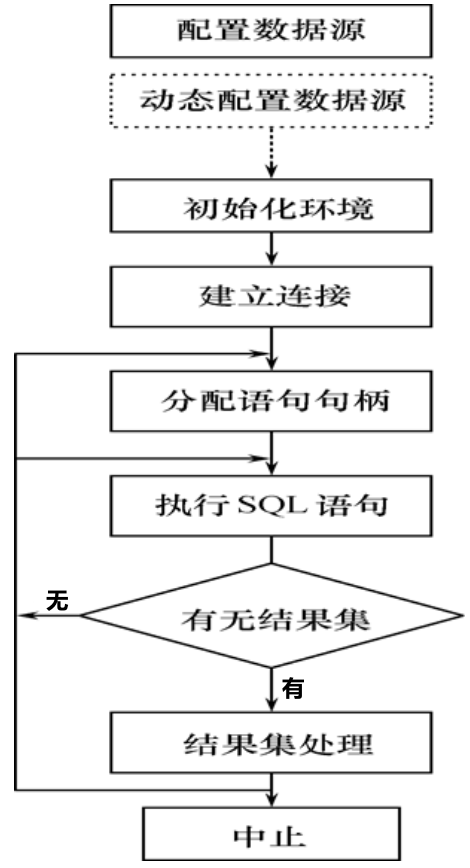
8.4.4 ODBC的工作流程
使用ODBC的应用系统大致的工作流程如下图所示。下面结合具体的应用实例,介绍如何使用ODBC开发应用系统。
【例8.12】在应用运行前,已经在KingbaseES和SQL Server中分别建立了 Student 关系表。要求创建一个应用程序,将 KingbaseES 数据库中 Student 表的数据备份到 SQL Server 数据库中。
答:该应用涉及两个不同的关系DBMS中的数据源,因此使用ODBC来开发应用程序,只要改变应用程序中连接函数 SQLConnect 的参数,就可以连接不同关系DBMS的驱动程序,连接两个数据源。应用程序要执行的操作是:
- 在KingbaseES上执行
select * from student;; - 把获取的结果集,通过多次执行
insert语句,插入到SQL Server的Student表中。
1. 配置数据源
配置数据源有两种方法:
(1)运行数据源管理工具来进行配置;
(2)使用 Driver Manager 提供的 ConfigDsn 函数,增加、修改或删除数据源。这种方法特别适用于在应用程序中创建的、临时使用的数据源。
【例8.13】采用第一种方法创建数据源。因为要同时用到KingbaseES和SQL Server,所以分别建立两个数据源,将其取名为 KingbaseES ODBC 和 SQL Server 。不同驱动器厂商提供了不同的配置数据源界面,建立这两个数据源的具体步骤从略。
部分程序源码如下:
#include <stdlib.h>
#include <stdio.h>
#include <windows.h>
#include <sql.h>
#include <sqlext.h>
#include <Sqltypes.h>
#define SNO_LEN 30
#define NAME_LEN 50
#define DEPART_LEN 100
#define SSEX_LEN 5
int main() {
/* Step1 定义句柄和变量 */
/* 以king开头的表示是连接Kingbase ES的变量 */
/* 以server开头的表示是连接SQL Server的变量 */
SQLHENV kinghenv, serverhenv; /* 环境句柄 */
SQLHDBC kinghdbc, serverhdbc; /* 连接句柄 */
SQLHSTMT kinghstmt, serverhstmt; /* 语句句柄 */
SQLRETURN ret;
SQLCHAR sSno[SNO_LEN], sName[NAME_LEN], sDepart[DEPART_LEN], sSex[SSEX_LEN];
SQLINTEGER sAge;
SQLINTEGER cbAge = 0, cbSno = SQL_NTS, cbName = SQL_NTS,
cbDepart = SQL_NTS, cbSex = SQL_NTS;
...
2. 初始化环境
由于还没有和具体的驱动程序相关联,所以不是由具体的DBMS驱动程序来进行管理,而是由 Driver Manager 进行控制并配置环境属性。直到应用程序通过调用连接函数、和某个数据源进行连接后,Driver Manager 才调用所连的驱动程序中的 SQLAllocHandle ,真正分配环境句柄的数据结构。
这部分程序源码如下:
...
/* Step2 初始化环境 */
ret = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &kinghenv); /* 分配环境句柄 */
ret = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &serverhenv); /* 分配环境句柄 */
ret = SQLSetEnvAttr(kinghenv, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);
ret = SQLSetEnvAttr(serverhenv, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);
...
3. 建立连接
应用程序调用 SQLAllocHandle 分配连接句柄,通过 SQLConnect 或 SQLDriverConnect 或 SQLBrowseConnect 与数据源连接。其中,SQLConnect 是最简单的连接函数,输入参数为配置好的数据源名称、用户ID和口令。本例中 KingbaseES ODBC 为数据源名字,SYSTEM 为用户名,MANAGER 为用户密码,注意系统对用户名和密码大小写的要求。
这部分程序源码如下:
...
/* Step3 建立连接 */
ret = SQLAllocHandle(SQL_HANDLE_DBC, kinghenv, &kinghdbc); /* 分配连接句柄 */
ret = SQLAllocHandle(SQL_HANDLE_DBC, serverhenv, &serverhdbc); /* 分配连接句柄 */
ret = SQLConnect(kinghdbc, "KingbaseES ODBC", SQL_NTS, "SYSTEM", SQL_NTS, "MANAGER", SQL_NTS);
if (!SQL_SUCCEEDED(ret)) /* 连接失败时返回错误值 */
return -1;
ret = SQLConnect(serverhdbc, "SQLServer", SQL_NTS, "sa", SQL_NTS, "sa", SQL_NTS);
if (!SQL_SUCCEEDED(ret)) /* 连接失败时返回错误值 */
return -1;
...
4. 分配语句句柄
在处理任何SQL语句之前,应用程序还需要分配一个语句句柄。语句句柄含有具体的SQL语句,以及输出的结果集等信息。在后面的执行函数中,语句句柄都是必要的输入参数。本例中分配了两个语句句柄,一个用来从KingbaseES中读取数据产生结果集 kinghstmt ,另一个用来向SQL Server插入数据 serverhstmt 。应用程序还可以通过 SQLSetStmtAttr 设置语句属性(如【例8.12】中结果集绑定的方式为按列绑定),或使用默认值。
这部分程序源码如下:
...
/* Step4 初始化语句句柄 */
ret = SQLAllocHandle(SQL_HANDLE_STMT, kinghdbc, &kinghstmt);
ret = SQLSetStmtAttr(kinghstmt, SQL_ATTR_ROW_BIND_TYPE, (SQLPOINTER)SQL_BIND_BY_COLUMN, SQL_IS_INTEGER);
ret = SQLAllocHandle(SQL_HANDLE_STMT, serverhdbc, &serverhstmt);
...
5. 执行SQL语句
应用程序处理SQL语句的方式有两种:预处理(SQLPrepare 、SQLExecute 适用于语句的多次执行)或直接执行(SQLExecdirect )。如果SQL语句含有参数,应用程序为每个参数调用 SQLBindParameter ,并把它们绑定至应用程序变量。这样,应用程序可直接通过改变应用程序缓冲区的内容,从而在程序中动态改变SQL语句的具体执行。接下来的操作,则会根据语句类型来进行相应处理:
- 对于有结果集的语句(
select或是编目函数),则进行结果集处理; - 对于没有结果集的函数,可直接利用本语句句柄,继续执行新的语句,或者获取行计数(本次执行所影响的行数)之后继续执行;
在本例中,使用 SQLExecdirect 获取KingbaseES中的结果集,并将结果集根据各列不同的数据类型,绑定到用户程序缓冲区。在插入数据时,采用了预编译的方式,首先通过 SQLPrepare 预处理SQL语句,然后将每一列绑定到用户缓冲区。
这部分程序源码如下:
...
/* Step5 两种方式执行语句 */
/* 预编译带有参数的语句 */
ret = SQLPrepare(serverhstmt, "insert into Student(Sno, Sname, Ssex, Sage, Sdept) values(?, ?, ?, ?, ?, ?)", SQL_NTS);
if (ret == SQL_SUCCESS || ret == SQL_SUCCESS_WITH_INFO) {
ret = SQLBindParameter(serverhstmt, 1, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR, SNO_LEN,
0, sSno, 0, &cbSno);
ret = SQLBindParameter(serverhstmt, 2, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR, NAME_LEN,
0, sName, 0, &cbName);
ret = SQLBindParameter(serverhstmt, 3, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR, 2,
0, sSex, 0, &cbSex);
ret = SQLBindParameter(serverhstmt, 4, SQL_PARAM_INPUT, SQL_C_LONG, SQL_INTEGER, 0,
0, &sAge, 0, &cbAge);
ret = SQLBindParameter(serverhstmt, 5, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR, DEPART_LEN,
0, sDepart, 0, &cbDepart);
}
/* 执行SQL语句 */
ret = SQLExecDirect(kinghstmt, "select * from student", SQL_NTS);
if (ret == SQL_SUCCESS || ret == SQL_SUCCESS_WITH_INFO) {
ret = SQLBindCol(kinghstmt, 1, SQL_C_CHAR, sSno, SNO_LEN, &cbSno);
ret = SQLBindCol(kinghstmt, 2, SQL_C_CHAR, sName, NAME_LEN, &cbName);
ret = SQLBindCol(kinghstmt, 3, SQL_C_CHAR, sSex, SSEX_LEN, &cbSex);
ret = SQLBindCol(kinghstmt, 4, SQL_C_LONG, &sAge, 0, &cbAge);
ret = SQLBindCol(kinghstmt, 5, SQL_C_CHAR, sDepart, DEPART_LEN, &cbDepart);
}
...
6. 结果集处理
应用程序可通过 SQLNumResultCols 获取结果集中的列数,通过 SQLDescribeCol 或是 SQLColAttribute 函数获取结果集中每一列的名称、数据类型、精度和范围。以上两步,对于信息明确的函数是可以省略的。
ODBC中使用游标来处理结果集数据。游标可分为 forward-only 游标和可滚动 scroll 游标——前者只能在结果集中向前滚动,是ODBC的默认游标类型;后者又分为静态 static 、动态 dynamic 、键集驱动 keyset-driven 和混合型 mixed 四种类型。不同于嵌入式SQL,ODBC游标的打开方式不是显式声明,而是系统自动产生一个游标——当结果集刚刚生成时,游标指向第一行数据之前。
应用程序可以通过 SQLBindCol 把查询结果绑定到应用程序缓冲区中,通过 SQLFetch 或 SQLFetchScroll 来移动游标,获取结果集中的每一行数据。对于如图像这类特别的数据类型,当一个缓冲区不足以容纳所有数据时,可通过 SQLGetdata 分多次获取。最后通过 SQLClosecursor 关闭游标。
这部分源码如下:
/* Step6 处理结果集并执行预编译后的语句 */
while ((ret = SQLFetch(kinghstmt)) != SQL_NO_DATA_FOUND) {
if (ret == SQL_ERROR)
printf("Fetch error\n");
else // 执行预编译后的语句
ret = SQLExecute(serverhstmt);
}
7. 中止处理
处理结束后,应用程序首先释放语句句柄,然后与数据库服务器断开、释放数据库连接(句柄),最后释放ODBC环境。这部分源码如下:
/* Step7 终止处理 */
SQLFreeHandle(SQL_HANDLE_STMT, kinghstmt);
SQLDisconnect(kinghdbc);
SQLFreeHandle(SQL_HANDLE_DBC, kinghdbc);
SQLFreeHandle(SQL_HANDLE_ENV, kinghenv);
SQLFreeHandle(SQL_HANDLE_STMT, serverhstmt);
SQLDisconnect(serverhdbc);
SQLFreeHandle(SQL_HANDLE_DBC, serverhdbc);
SQLFreeHandle(SQL_HANDLE_ENV, serverhenv);
return 0;
}
8.5 OLE DB
对象链接与嵌入数据库 Object Linking and Embedding Database, OLD DB ,也是微软提出的数据库连接访问标准。
8.5.1 OLE DB概述
OLE DB是基于组件对象模型 Component Object Model, COM 来访问各种数据源的 ActiveX 的通用接口,它提供访问数据的一种统一手段,而不管存储数据时使用的方法如何。与ODBC和JDBC类似,OLE BD支持的数据源可以是数据库,也可以是文本文件、Excel表格、ISAM等各种不同格式的数据存储。OLE DB可以在不同的数据源中进行转换。客户端的开发人员,利用OLE DB进行数据访问时,不必关心大量不同数据库的访问协议。
OLE DB基于组件 Component 概念,构造和设计各种标准接口,作为COM组件对象的公共方法,供开发应用程序所用。对各种数据库管理系统服务进行封装,并允许创建软件组件,实现这些服务。OLE DB组件包括数据提供程序(包含和表现数据)、数据使用者(使用数据)和服务组件(处理和传送数据,如查询处理器和游标引擎)。OLE DB包含了一个连接ODBC的“桥梁”,对现用的各种ODBC关系型数据库驱动程序提供支持。
8.5.2 OLE DB体系结构
下图是一个基于「OLE DB体系结构」设计程序的编程模型。OLE DB体系结构中包含消费者 consumer 和提供者 provider 两部分,二者是OLE DB的基础,也是描述OLE DB的一个上下文相关概念——消费者通过提供者,可以访问某个数据库中的数据;提供者对应用访问数据源的接口,实施标准封装。开发人员主要使用OLE DB提供者来实现应用。
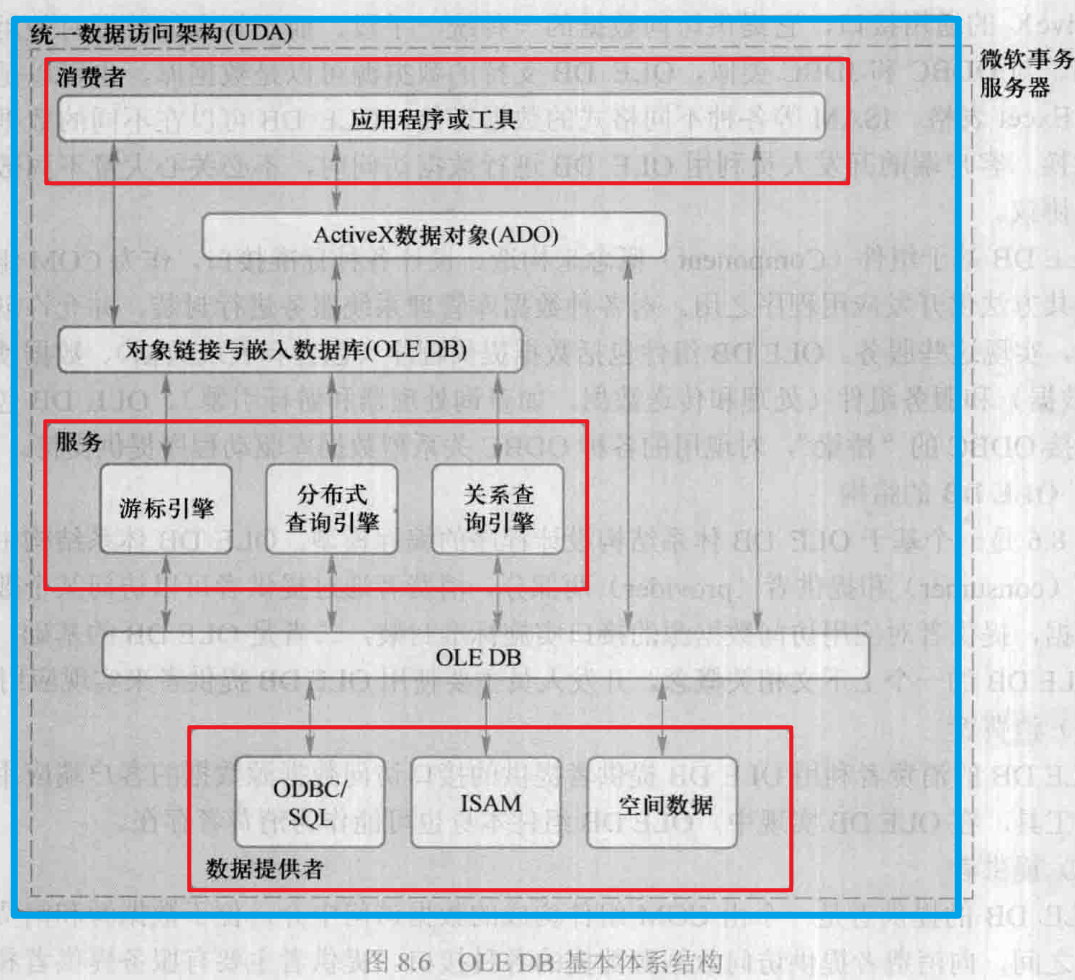
(1)消费者:OLE DB的消费者,利用OLE DB提供者提供的接口,访问数据源数据的客户端应用程序或其他工具。在OLE DB实现中,OLE DB组件本身也可能作为消费者存在。
(2)提供者:OLE DB的提供者,是一个由COM组件构成的数据访问中介,位于数据源和消费者应用程序之间,向消费者提供访问数据源数据的各种接口。提供者主要有服务提供者和数据提供者:
① 服务提供者:这类提供者自身没有数据,它通过OLE DB接口封装服务,从下层获取数据并向上层提供数据,具有提供者和消费者双重身份。一个服务提供者,还可以和其他服务提供者或组件组合起来,定义新的服务组件。比如,在OLE DB体系中,游标服务 cursor service 就是一个典型的服务类提供者。
② 数据提供者:数据提供者自己拥有数据,并通过接口形成表格形式的数据。它不依赖于其他服务类或数据类的提供者,直接向消费者提供数据。
③ OLE DB2.5还引入了一种文档源 document source 提供者,可用来管理文件夹和文档。
消费者的需求可能很复杂、也可能比较简单,针对不同的要求,提供者可以返回原始数据,也可以在数据上进行附加操作。任何OLE DB提供者都必须提供数据库所要求的、最小功能接口集,不需要支持全部OLE DB接口,除必需接口外的可选接口,仅用来提供附加功能,提高易用性。提供的所有接口,都是可访问的标准接口。
8.5.3 OLE DB编程模型
OLE DB基于COM对象技术,形成了一个支持数据访问的通用编程模型:数据管理任务必须由消费者访问数据,由提供者发布 deliver 数据。OLE DB编程模型有两种:Rowset 模型和 Binder 模型。Rowset 编程模型假定数据源中的数据比较规范,提供者以行集 record set 形式发布数据;Binder 编程模型主要用于提供者不提供标准表格式数据的情况,这时OLE DB采用 Binder 编程模型,将一个统一资源定位符 Uniform Resource Locator, URL 和一个OLE DB对象相关联或绑定,并在必要时创建层次结构的对象。
8.6 JDBC编程
JDBC是Java的开发者Sun制定的、Java数据库连接技术的简称,建立在 X/Open SQL CLI 基础上,为DBMS提供「支持无缝连接应用」的技术。JDBC在应用程序中的作用,和ODBC十分类似,是Java实现数据库访问的应用程序编程接口。
JDBC是面向对象的接口标准,一般由具体的数据库厂商提供。它通过对象,定义了一系列与数据库系统进行交互的类和接口,主要功能是管理存放在数据库中的数据。通过接口对象,应用程序可以完成与数据库的连接、执行SQL语句、从数据库中获取结果、获取状态及错误信息、终止事务和连接等。
JDBC与ODBC类似,它为Java程序提供统一、无缝地操作各种数据库的接口。因为实际应用中,我们常常无法确定用户想访问什么类型的数据库,程序员使用JDBC编程时,可以不关心它要操作的数据库是哪家厂商的产品,从而提高了软件的通用性。只要系统上安装了正确的驱动程序,JDBC应用程序就可以访问其相关的数据库。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











