 复合索引详解
复合索引详解





 本文深入解析复合索引的概念,探讨其在减少开销、提高查询效率及实现覆盖索引方面的优势,并阐述最左匹配原则及创建复合索引时的列选择策略。
本文深入解析复合索引的概念,探讨其在减少开销、提高查询效率及实现覆盖索引方面的优势,并阐述最左匹配原则及创建复合索引时的列选择策略。
-
什么是复合索引
基于表的多列上创建的索引,也叫联合索引。
-
为什么使用复合索引
减少开销:建一个复合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引:对复合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from newtable where col1=1 and col2=2。可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高:索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select * from newtable where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
-
什么是最左匹配原则
最左优先,以查询条件最左边为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。上面说到建立一个复合索引(col1,col2,col3)相当于建立了三个索引,但除此之外其他的条件组合方式不能使用这个复合索引。
比如:(col1,col3)、(col2m,col3)、(col2)、(col3)这四种条件无法使用索引
Q1:IN查询会不会引起停止匹配
A1:不会
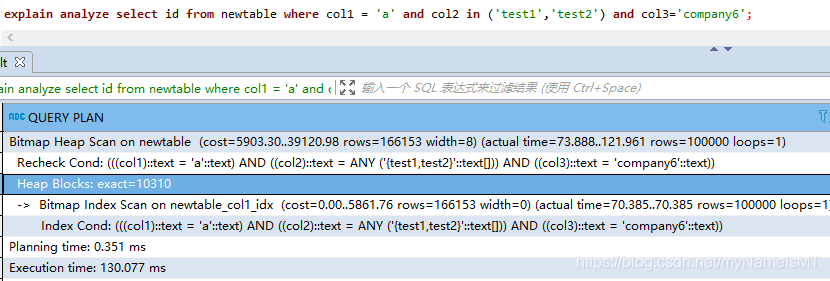
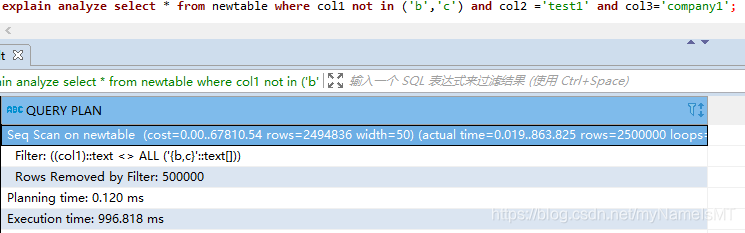
Q2: NOT IN查询条件导致索引停止匹配
A2:会,因为NOT IN或者<>会导致索引失效,所以不仅是停止匹配,同时NOT IN字段也不会使用索引
-
创建复合索引时列的选择原则
- 经常用的列优先(最左匹配原则)
- 离散度高的列优先(离散度高原则)
- 宽度小的列优先(最少空间原则)
列的离散性计算:count(distinct col)/ count(col)
创建复合索引时列的选择原则引自:https://www.cnblogs.com/wangkaihua/p/10220462.html

















 2841
2841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









