




概述
Ultralytics提供了一系列的解决方案,利用YOLO11解决现实世界的问题,包括物体计数、模糊处理、热力图、安防系统、速度估计、物体追踪等多个方面的应用。
YOLO11 在实时应用中表现出色,凭借其先进的算法和深度学习能力,可为人群分析、交通分析和移动监控等各种场景提供高效、精确的物体计数。本文使用Python实现了简单的演示界面,可以在图像中画线或者框,运行推理,输出计数结果。
Ultralytics提供了CLI和Python例子,展示如何使用计数解决方案。
CLI:
# Run a counting example
yolo solutions count show=True
# Pass a source video
yolo solutions count source="path/to/video.mp4"
# Pass region coordinates
yolo solutions count region="[(20, 400), (1080, 400), (1080, 360), (20, 360)]"
Python:
import cv2
from ultralytics import solutions
cap = cv2.VideoCapture("path/to/video.mp4")
assert cap.isOpened(), "Error reading video file"
# region_points = [(20, 400), (1080, 400)] # line counting
region_points = [(20, 400), (1080, 400), (1080, 360), (20, 360)] # rectangle region
# region_points = [(20, 400), (1080, 400), (1080, 360), (20, 360), (20, 400)] # polygon region
# Video writer
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
video_writer = cv2.VideoWriter("object_counting_output.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Initialize object counter object
counter = solutions.ObjectCounter(
show=True, # display the output
region=region_points, # pass region points
model="yolo11n.pt", # model="yolo11n-obb.pt" for object counting with OBB model.
# classes=[0, 2], # count specific classes i.e. person and car with COCO pretrained model.
# tracker="botsort.yaml", # choose trackers i.e "bytetrack.yaml"
)
# Process video
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or processing is complete.")
break
results = counter(im0)
# print(results) # access the output
video_writer.write(results.plot_im) # write the processed frame.
cap.release()
video_writer.release()
cv2.destroyAllWindows() # destroy all opened windows
ObjectCounter参数
基本参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
model | str | None | Ultralytics YOLO 模型文件的路径。 |
show_in | bool | True | 是否在视频流中显示输入计数。 |
show_out | bool | True | 是否在视频流中显示输出计数。 |
region | list | [(20, 400), (1260, 400)] | 定义计数线或区域。 |
ObjectCounter支持使用track参数:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
tracker | str | 'botsort.yaml' | 指定要使用的跟踪算法, bytetrack.yaml 或 botsort.yaml. |
conf | float | 0.3 | 设置检测的置信度阈值;数值越低,跟踪的物体越多,但可能会出现误报。 |
iou | float | 0.5 | 设置交叉重叠 (IoU) 阈值,用于过滤重叠检测。 |
classes | list | None | 按类别索引筛选结果。例如 classes=[0, 2, 3] 只跟踪指定的类别(class在COCO数据集定义)。 |
verbose | bool | True | 控制跟踪结果的显示,提供被跟踪物体的可视化输出。 |
device | str | None | 指定用于推理的设备(例如: cpu, cuda:0 或 0). 允许用户选择CPU 、特定GPU 或其他计算设备运行模型。 |
可视化参数:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
show | bool | False | 如果 True在一个窗口中显示注释的图像或视频。有助于在开发或测试过程中提供即时视觉反馈。 |
line_width | None or int | None | 指定边界框的线宽。如果 None则根据图像大小自动调整线宽,使图像更加清晰。 |
show_conf | bool | True | 在标签旁显示每次检测的置信度得分。让人了解模型对每次检测的确定性。 |
show_labels | bool | True | 在可视输出中显示每次检测的标签。让用户立即了解检测到的物体。 |
GUI演示
这里使用Tkinter编写一个简单界面,演示物体计数应用。
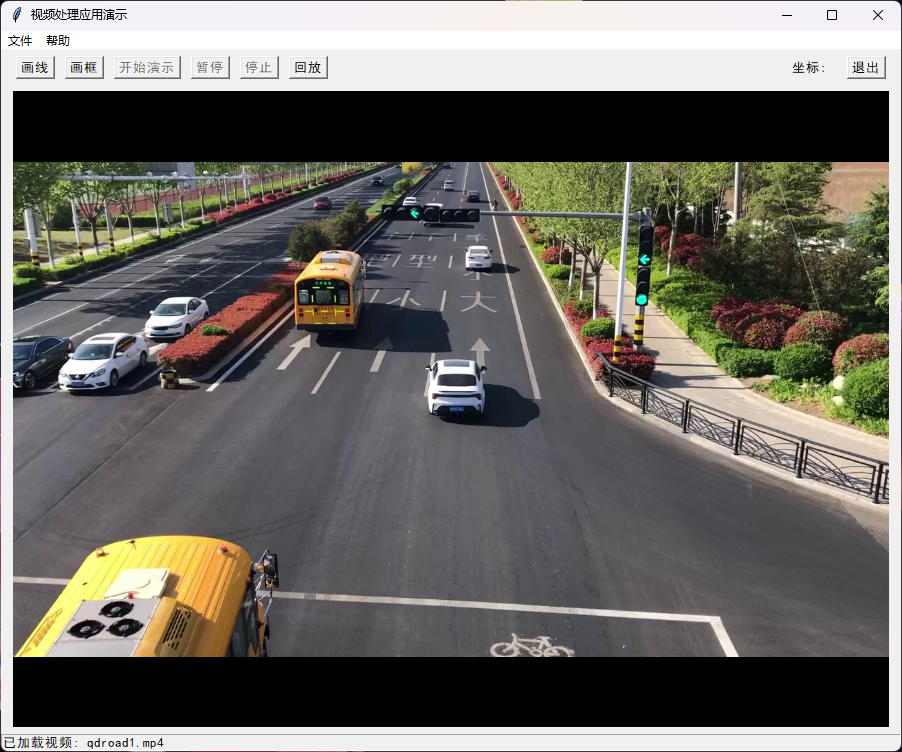
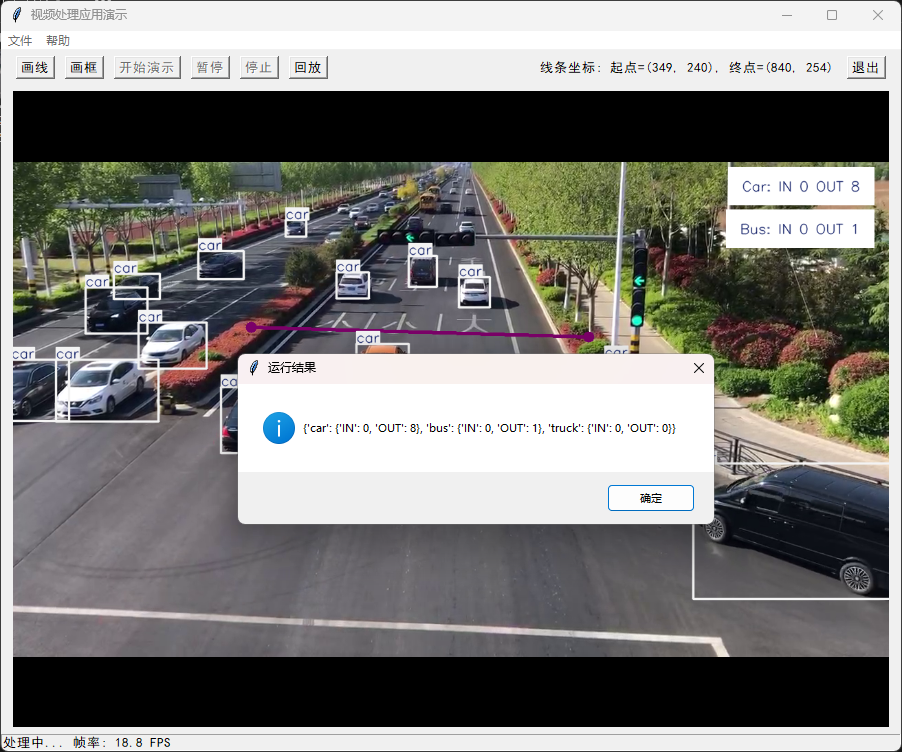
从文件菜单打开一个mp4文件,显示第一帧图像,在图像上画检测线或者框。
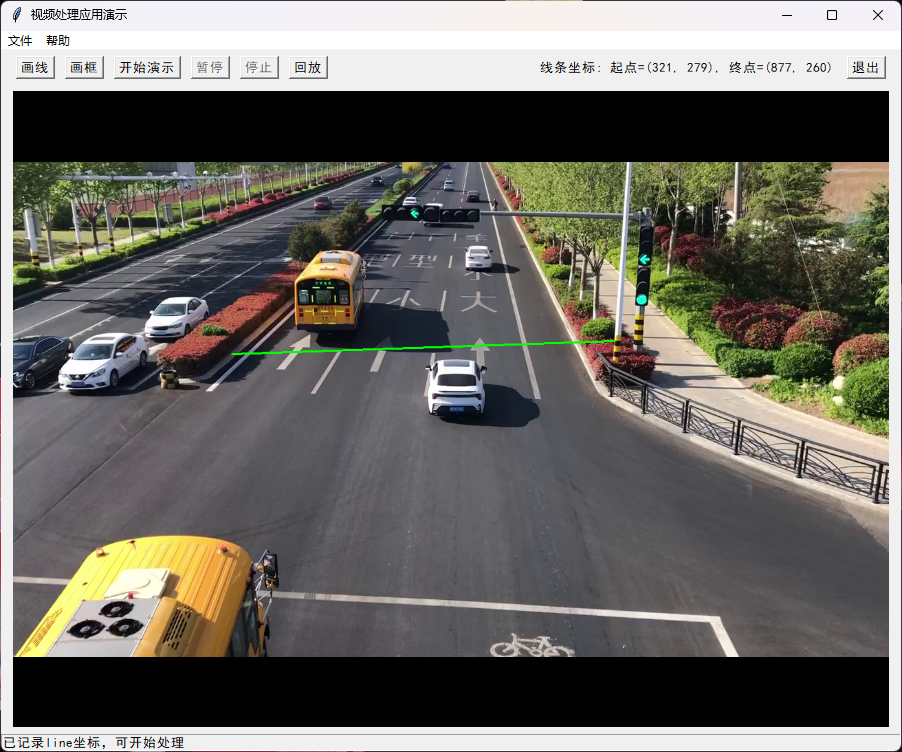
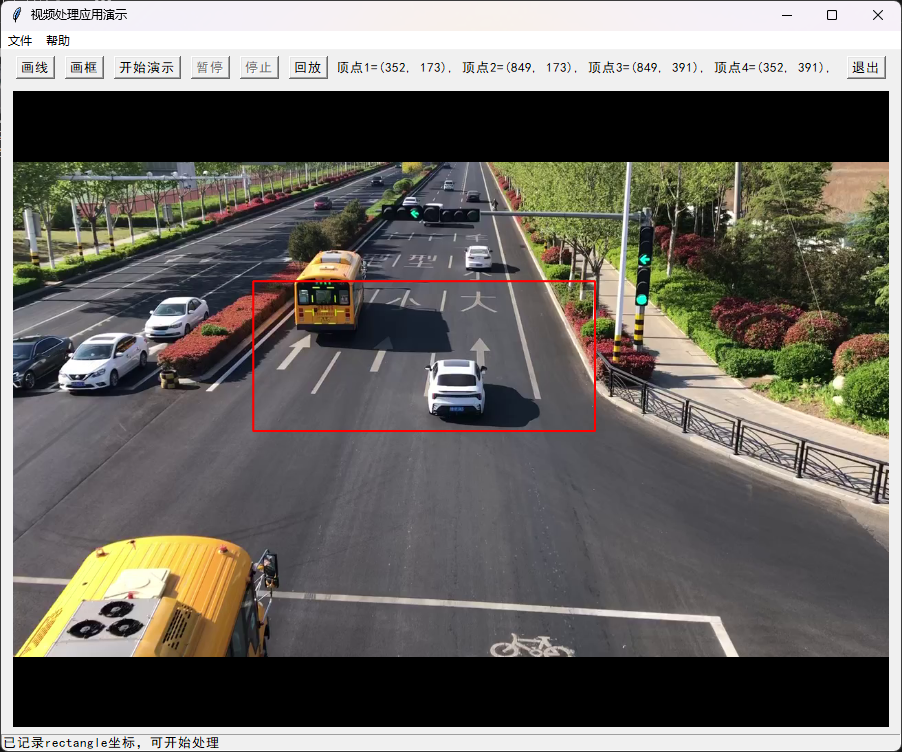
矩形绘制完成后,可以使用鼠标右键拖动改变角度。
然后“开始演示”,计数结果叠加在图像右上角。图像中每个被检测的物体都标注了方框和类名称。
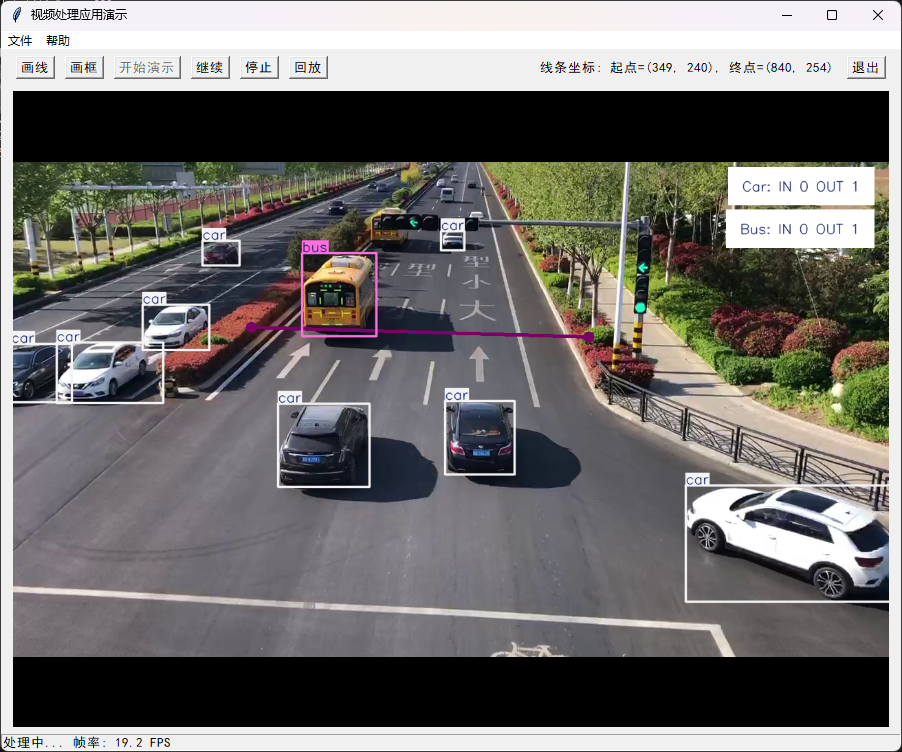
如果verbose为True,控制台输出当前帧的信息。
0: 384x640 15 cars, 24.0ms
Speed: 1.7ms preprocess, 24.0ms inference, 2.2ms postprocess per image at shape (1, 3, 384, 640)
🚀 Results ****: SolutionResults(out_count=9, classwise_count={'car': {'IN': 0, 'OUT': 8}, 'bus': {'IN': 0, 'OUT': 1}, 'truck': {'IN': 0, 'OUT': 0}}, total_tracks=15)
GUI演示程序代码
本演示程序定义了两个类:VideoProcessorApp类和VideoProcessor类。
class VideoProcessorApp:
def __init__(self, root):
self.root = root
self.root.title("视频处理应用演示")
self.root.geometry("900x700")
# 设置中文字体
self.font = ('SimHei', 10)
# 视频和图像处理相关变量
self.cap = None
self.video_path = ""
self.original_frame = None
self.current_frame = None
self.processed_frames = []
self.is_playing = False
self.is_processing = False
self.is_paused = False
self.draw_mode = None # 'line' 或 'rectangle'
self.start_point = None
self.end_point = None
self.drawing = False
self.output_file = ""
self.rect_angle = 0 # 矩形旋转角度
self.rect_center = None # 矩形中心点
self.rect_points = None # 矩形四个顶点
self.pause_event = threading.Event()
self.video_processor = None
self._dt_buffer = []
self._last_time = time.perf_counter()
self.count = 0
self.count_read = 0
self.frame_reading_done = False # 标志位
self.object_count = {}
# 多线程相关
self.frame_queue = Queue(maxsize=60)
self.result_queue = Queue(maxsize=60)
self.writer_queue = Queue(maxsize=60)
self.stop_threads = False
# 创建界面组件
self.create_menu()
self.create_widgets()
# 绑定鼠标事件
self.canvas.bind("<Button-1>", self.on_mouse_click)
self.canvas.bind("<B1-Motion>", self.on_mouse_drag)
self.canvas.bind("<ButtonRelease-1>", self.on_mouse_release)
self.canvas.bind("<Button-3>", self.on_right_click)
self.canvas.bind("<B3-Motion>", self.on_right_drag)
self.canvas.bind("<ButtonRelease-3>", self.on_right_release)
VideoProcessor类专门处理视频帧,其中调用了solutions.ObjectCounter类:
class VideoProcessor:
"""视频处理器类,负责处理视频帧"""
def __init__(self, coords=None):
self.coords = coords # 存储线条或矩形的坐标
if coords['type'] == 'line':
pts = [coords['start'], coords['end']]
else:
pts = coords['points']
# 初始化
self.counter = solutions.ObjectCounter(
show=False,
model="yolo11n.pt",
region=pts,
classes=[0,2,5,7],
device='cuda' if torch.cuda.is_available() else 'cpu',
half=True if torch.cuda.is_available() else False,
verbose = False
)
dummy_frame = np.zeros((640, 640, 3), dtype=np.uint8)
for _ in range(3): # 连续运行几次来触发所有内部初始化
self.counter(dummy_frame)
def process_frame(self, frame):
"""处理单帧图像"""
if not self.coords:
return frame
results = self.counter(frame)
return results.plot_im, results.classwise_count
由于读写视频文件和进行神经网络推理均需要较大的计算量,本演示代码使用多线程分别处理读、写、显示和推理,以最大化利用计算机资源,提高处理速度。
def start_processing(self):
if self.cap is None or not self.cap.isOpened():
messagebox.showerror("错误", "请先打开视频文件")
return
if self.video_processor is None:
messagebox.showerror("错误", "请先绘制线条或矩形")
return
if self.is_processing:
messagebox.showinfo("提示", "正在处理视频,请等待")
return
self.processed_frames.clear()
self.is_processing = True
self.is_playing = True
self.is_paused = False
self.stop_threads = False
self.process_button.config(state=tk.DISABLED)
self.pause_button.config(state=tk.NORMAL)
self.stop_button.config(state=tk.NORMAL)
self.pause_event.set()
# 启动多线程
self.reader_thread = threading.Thread(target=self.frame_reader)
self.processor_thread = threading.Thread(target=self.frame_processor)
self.display_thread = threading.Thread(target=self.result_display)
self.writer_thread = threading.Thread(target=self.video_writer_worker)
# 设置线程优先级
try:
self.reader_thread.priority = 'ABOVE_NORMAL'
self.processor_thread.priority = 'HIGH'
self.writer_thread.priority = 'ABOVE_NORMAL'
except:
pass
# 启动线程
self.reader_thread.start()
self.processor_thread.start()
self.display_thread.start()
self.writer_thread.start()
其中的推理线程代码如下:
def frame_processor(self):
"""专用模型推理线程"""
while not self.stop_threads:
if self.is_paused:
time.sleep(0.01)
continue
try:
start_time = time.time()
frame = self.frame_queue.get(timeout=0.1)
processed, self.object_count = self.video_processor.process_frame(frame)
self.count += 1
if not self.stop_threads:
self.result_queue.put(processed, timeout=0.1)
except Empty:
continue
except Exception as e:
print(f"Frame processor error: {str(e)}")
break
视频播放完成后,显示计数结果。


















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









