




前言
目前停车场管理相关技术已经比较成熟,特别是随着深度学习技术的深入应用,在停车场出入口进行车辆特征、车牌号码识别等方面,产品日臻成熟。在大型地下车库,也发展了包括超声波、视频检测、区域空位显示等多种技术手段,进行车位检测和停车引导,但是在大型的室外停车场,特别是景区停车场以及大型活动的临时停车场,人们倾向于把车辆停放的离出入口较近的位置,导致大型停车场各个区域停车不均衡,停车位资源得不到有效利用。使用人工方式巡查和引导车辆有一定的效果,但是无法持久。通过在每个停车位安装检测器,能够解决车位检测的问题,但是往往投资较高,维护工作量较大,没有得到广泛应用。
对于固定停车场,通过在高处安装一定数量的摄像机,使用视频技术实时分析较大区域的车辆停放情况,能够提供物美价廉的解决方案。对于大型活动的临时停车,通过使用无人机获取各个区域的图像,也能够获得同样效果。
YOLO11停车场管理方案
Ultralytics YOLO11提供了一个停车场管理方案。


Ultralytics提供了一个简单Python程序,演示如何对停车场进行车位标注。当然 ,在使用这些演示代码前,需要先配置Python运行环境,主要是使用pip install ultralytics安装ultralytics运行所需的所有库文件,依赖库较多,安装需要较长时间。环境配置完成后,就可以按照下面的步骤测试这些例子代码。
首先,需要获得一幅停车场的图片,可以是拍照或截取摄像机图像帧。
其次,运行演示代码,调出图形界面,打开上述图片,然后使用鼠标在每个停车位的顶点点击生成多边形,点击4个点自动连线成四边形。
from ultralytics import solutions
solutions.ParkingPtsSelection()
点击"Upload Image",选择一张图片打开,就是停车场的标注界面。使用鼠标点击就可以完成车位标注。
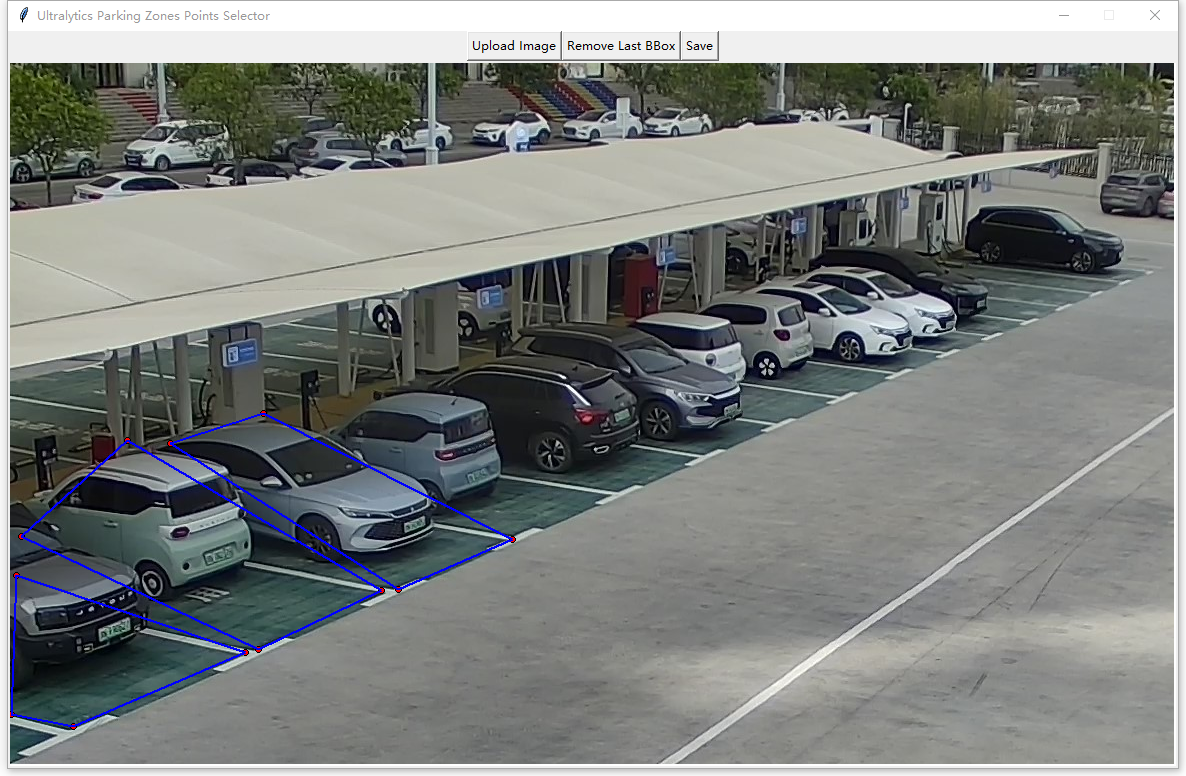
完成后,点击“Save”,将把标注保存到bounding_boxes.json。文件数据结构如下:
[
{
"points": [
[
16,
510
],
[
237,
584
],
[
61,
666
],
[
10,
651
]
]
},
......
]
标注完成后,可以使用下面的代码进行演示。
import cv2
from ultralytics import solutions
# Video capture
cap = cv2.VideoCapture("test.mp4")
assert cap.isOpened(), "Error reading video file"
# Video writer
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
video_writer = cv2.VideoWriter("parking management.avi", cv2.VideoWriter_fourcc(*"mp4v"), fps/30, (w, h))
# Initialize parking management object
parkingmanager = solutions.ParkingManagement(
model="yolo11n.pt", # path to model file
json_file="bounding_boxes.json", # path to parking annotations file
)
while cap.isOpened():
ret, im0 = cap.read()
if not ret:
break
i = 0
while cap.isOpened():
ret, im0 = cap.read()
if not ret:
break
if (i%30==0):
results = parkingmanager(im0)
# print(results) # access the output
video_writer.write(results.plot_im) # write the processed frame.
i += 1
cap.release()
video_writer.release()
cv2.destroyAllWindows() # destroy all opened windows
运行时可以查看视频每一帧的检测结果及使用的时间。
运行完成后,输出视频文件parking management.avi。播放这个文件,可以看到每帧的检测情况。

本方案需要对各个停车位进行精确标注,对于固定停车场,能够提供精确的检测结果,但是很多场景下是无法事先标注的,而且对较大的停车场进行标注,也是很大的工作量,因此,不标注车位,而是使用YOLO自动检测车辆和空位,有更好的场景适应性。
使用YOLO检测停车场车辆和空位
使用深度学习进行目标检测,一般流程是训练、验证、测试后输出模型,然后使用模型对输入的数据进行预测并输出结果。
YOLO11是YOLO系列最新的稳定版本,支持多种计算机视觉功能,包括对象检测、分段、分类、姿势、OBB(定向边框对象检测、跟踪等。YOLO11 基于深度学习和计算机视觉领域的尖端技术,在速度和准确性方面相比之前的版本具有显著提升。其流线型设计使其适用于各种应用,并可轻松适应从边缘设备到云 API 等不同硬件平台。YOLO11 融入了计算机视觉研究的最新进展,为实际应用提供了更好的速度-精度权衡。面对开发者,YOLO11提供了更友好的应用界面,包括CLI和Python接口。
对于停车场管理,最直接的是使用YOLO的对象检测功能,即在图片或视频中检测识别对象的位置和类别。对于停车场,我们可以只检测车辆或者检测车辆+空闲车位。本文以检测检测车辆+空闲车位进行描述。
准备数据集
首先需要准备数据集。可以自己收集应用场景的图片,进行标注,也可以下载公开数据集,用于检测训练。
停车场是复杂场景,包括在不同光照条件下的检测、遮挡处理、多角度和不同尺寸停车位的识别等,解决这些问题,除了算法的改进,还需要不断扩充和优化用于训练模型的数据集,以提高模型的泛化能力。
YOLO11需要的标注文件格式:
classID x y w h
数据需要经过归一化处理。
例如:
1 0.3671875 0.5 0.28125 0.228125
0 0.17890625 0.73515625 0.2921875 0.2609375
定义data.yaml
path: #数据集所在的根目录
train: train
val: val
names:
0: car
1: free
数据集目录结构
path
|-- datasets
|-- train
| |-- images
| |-- labels
|-- val
|-- images
|-- labels
训练和验证
Ultralytics官方文档给出了几种使用方法:用户可以使用Python或者CLI训练数据集。
Python:
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.yaml") # 从 YAML文件构建新模型
#model = YOLO("yolo11n.pt") # 使用预训练模型进行训练
#model = YOLO("yolo11n.yaml").load("yolo11n.pt") # 使用YAML和预训练模型构建新模型
# Train the model
results = model.train(data="coco8.yaml", epochs=100, imgsz=640) #不传入device参数时,系统根据机器配置自动使用GPU或CPU,优先选用GPU
CLI
# 使用YAML训练新模型
yolo detect train data=coco8.yaml model=yolo11n.yaml epochs=100 imgsz=640
# 使用预训练模型进行训练
yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640
# 使用YAML和预训练模型构建新模型
yolo detect train data=coco8.yaml model=yolo11n.yaml pretrained=yolo11n.pt epochs=100 imgsz=640
我这里使用Python进行训练。代码如下:
import datetime
from ultralytics import YOLO
def yolo11_detect_train():
model = YOLO('./models/yolo11n.yaml').load('./models/yolo11n.pt') # build from YAML and transfer weights
model.info()
# data.yaml在当前目录,数据集在./datasets
data='data.yaml'
start_time = datetime.datetime.now()
print(f"开始训练 {start_time.strftime('%Y-%m-%d %H:%M:%S')}")
model.train(data=data, epochs=100, imgsz=640, batch=4, workers=4)
end_time = datetime.datetime.now()
print(f"训练结束 {end_time.strftime('%Y-%m-%d %H:%M:%S')}")
if __name__ == '__main__':
#Park lot detection, detect car(occupied) and free spot
yolo11_detect_train()
执行100轮次训练,需要比较长的时间,具体时间根据机器配置、训练数据集规模具有比较大的差异。
训练结束后,输出一系列训练结果文档,包括各种lables分布图、PR曲线、F1曲线、mAP50、mAP50-95等各种图表,用于对训练结果进行评价分析。当然,最重要的是训练权重文件:best.pt和last.pt。
预测(推理)
YOLO11可以对图像、视频文件甚至实时视频里进行推理。
-
性能:专为实时、高速处理而设计,同时不影响精度。
-
易用性:直观的Python 和CLI 界面,便于快速部署和测试。
-
高度可定制:各种设置和参数可根据具体要求调整模型的推理行为。
我们可以使用训练模型对各种数据源进行预测/推理。以下是参考代码:
import os
import shutil
from ultralytics import YOLO
from functions import process_images
def yolo11_detect_predict(repo_path, model, conf, iou):
modelname = os.path.basename(model)
# Remove folder if it exists
if os.path.exists(os.path.join(repo_path, f'results/{modelname[:-3]}/')):
shutil.rmtree(os.path.join(repo_path, f'results/{modelname[:-3]}/'))
dest_path=modelname[:-3]
model = YOLO(model)
source=os.path.join(repo_path, 'data/images')
project=os.path.join(repo_path, 'results/')
name=dest_path+"/yolo_images"
#为了减少内存需求,设置stream-True
print(f"开始预测 {name}")
model.predict(source=source, save_txt=True, save=True, exist_ok=True, imgsz=1280, conf=conf, iou=iou, project=project, name=name, stream=True)
print("运行预测完成")
if __name__ == '__main__':
repo_path = os.getcwd()
model = "./models/best.pt"
# Execute the yolo11 predict
yolo11_detect_predict(repo_path, model, conf=0.4, iou=0.45)
程序执行完成后,在results/yolo_images目录下,是叠加了检测结果数据的图像文件,同时labels目录下是检测结果数据。
小而规则的场景:

大而不规则的场景:

本方案对各种停车场有比较好的场景适应性,对不同大小的检测区域能够提供精确或者比较精确的车位状态,对于分区域停车指挥和调度,提供了物美价廉的解决方案。


















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









