#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 18/4/15 下午4:32
# @Author : cicada@hole
# @File : kMeans.py
# @Desc : 第10章 利用k均值聚类算法对未标注数据分组
# @Link :
from numpy import *
'''
=========从文本导入数据
1.文本每行由tab分割
'''
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
# print(curLine)
fltLine = float(curLine[0]), float(curLine[1])
print(fltLine)
dataMat.append(fltLine)
return dataMat
'''
======计算向量的欧式距离
(x1-x2)^2再开方
'''
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2)))
'''
=======为给定数据集构建包含K个随机质心的集合
'''
def randCent(dataSet, k):
numSamples, dim = matrix(dataSet).shape # dim列数
# n = dataSet.shape[1]
n = dim
centroids = matrix(zeros((k, n))) #k行n列
for j in range(n):
minJ = min(dataSet[:, j])
rangeJ = float(max(dataSet[:, j]) - minJ)
centroids[:, j] = minJ + rangeJ * random.rand(k, 1) #随机生成k行n列中心点
return centroids
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0] # 样本数
print("----样本数", m)
clusterAssment = matrix(zeros((m, 2))) # mx2矩阵 簇分配矩阵 两列,一列簇索引值,一列存储误差
centroids = createCent(dataSet, k) #随机选取中心
clusterChanged = True # 是否需要继续迭代
while clusterChanged:
clusterChanged = False
for i in range(m): #遍历样本
minDist = inf
minIndex = -1
for j in range(k): # 寻找最近的质心
distJI = distMeas(centroids[j, :], dataSet[i, :]) #计算样本和质心的距离
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
print(centroids)
# 更新质心的位置
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A == cent)[0]]
centroids[cent, :] = mean(ptsInClust, axis=0) # 计算均值
return centroids, clusterAssment
'''
展示数据点
'''
import matplotlib.pyplot as plt
def showData(dataSet):
x = []
y = []
plt.figure(figsize=(9, 6))
for i in dataSet:
x.append([float(i[0])])
y.append([float(i[1])])
plt.scatter(x, y, c='b', s = 25, alpha = 0.4, marker ='o')
# c:散点的颜色
# s:散点的大小
# alpha:是透明程度
plt.show()
def showCluster(dataSet, k, centroids, clusterAssment):
numSamples, dim = dataSet.shape
if dim != 2:
print("Sorry! I can not draw because the dimension of your data is not 2!")
return 1
# v 倒三角 s正方形 o圆 +加号
mark = ['vr', 'sb', 'og', '+k', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
return 1
# draw all samples
for i in range(numSamples):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
# D钻石
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
# draw the centroids
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize=12)
plt.show()
if __name__ == '__main__':
print("======第一步: 加载数据====")
dataMat = mat(loadDataSet('testSet.txt'))
# showData(dataMat)
k = 4
myCentroids, clustAssing = kMeans(dataMat, k)
print(myCentroids, clustAssing)
showCluster(dataMat,k,myCentroids,clustAssing)
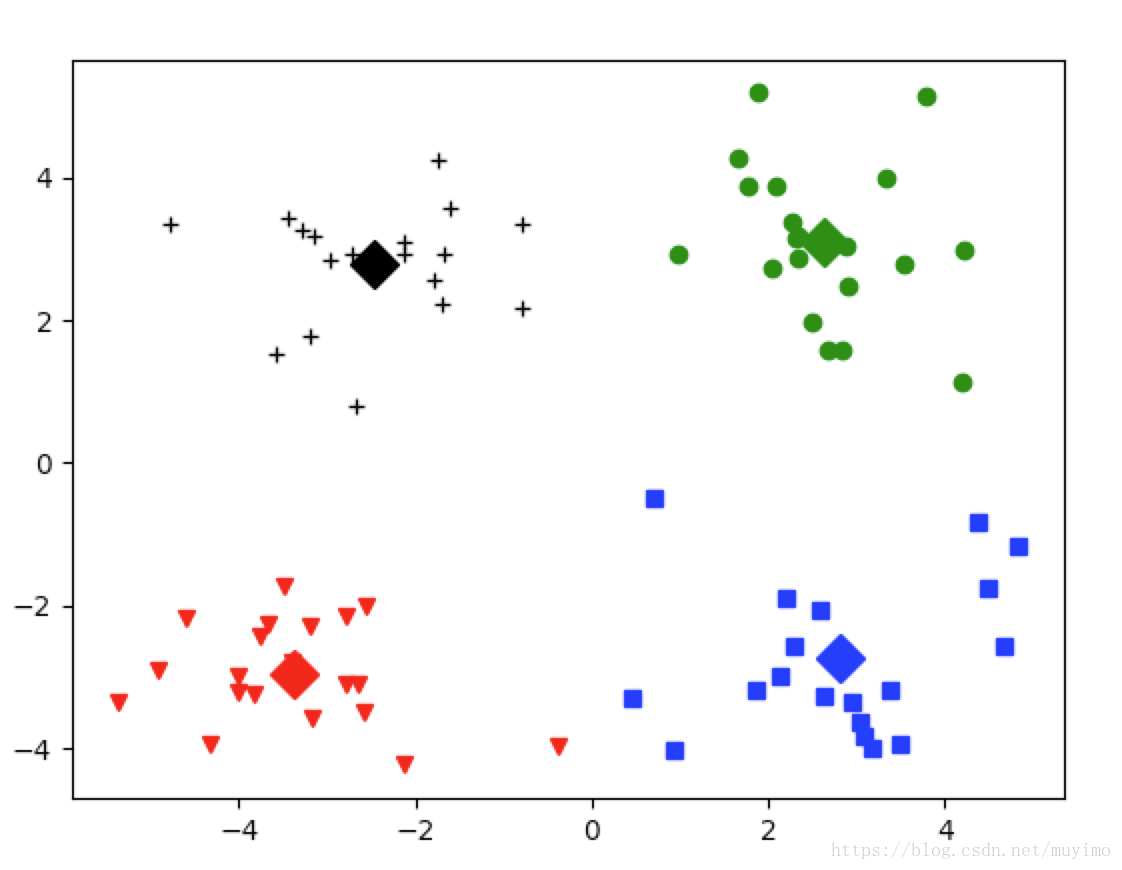





 本文介绍了一种无监督学习方法——K均值聚类算法,并通过Python代码实现了该算法。通过对未标注数据进行分组,K均值聚类能够找到数据内部的结构。文章详细解释了算法的工作原理,包括数据导入、距离计算、质心初始化及迭代过程。
本文介绍了一种无监督学习方法——K均值聚类算法,并通过Python代码实现了该算法。通过对未标注数据进行分组,K均值聚类能够找到数据内部的结构。文章详细解释了算法的工作原理,包括数据导入、距离计算、质心初始化及迭代过程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









