




 DSRG网络结合CAM和深籽区域增长算法,利用种子区域进行图像语义分割,通过逐步迭代扩展未知区域,优化分割效果。该方法在CVPR 2018发表,相较于SEC框架,DSRG在平衡前景背景损失、迭代种子扩展方面进行了改进。
DSRG网络结合CAM和深籽区域增长算法,利用种子区域进行图像语义分割,通过逐步迭代扩展未知区域,优化分割效果。该方法在CVPR 2018发表,相较于SEC框架,DSRG在平衡前景背景损失、迭代种子扩展方面进行了改进。
DSRG
paper: Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing
文章被18年的CVPR收录,文章的出发点是:CAM能够提供物体最具辨识度的区域,但是对于物体辨识度较低的区域没有识别出来,所以如何正确划分这些待定区域是主要要解决的问题。
作者考虑将CAM的结果作为初始种子,之后不断生长,为附近的待定的区域打上标签,以使得整张图像每个点都有确定的类别划分。
generate seed area S
- 使用CAM获得图像III的高置信度的前景区域RCR_CRC,在使用基于saliency的传统算法得到背景的高置信度区域R0R_0R0。
- 将R=RC+R0R=R_C+R_0R=RC+R0作为种子,这些区域大概了占到了整张图像的40%,所以剩下60%的待定区域就需要通过种子生长确定类别。将R作为初始种子区域SSS。
train network
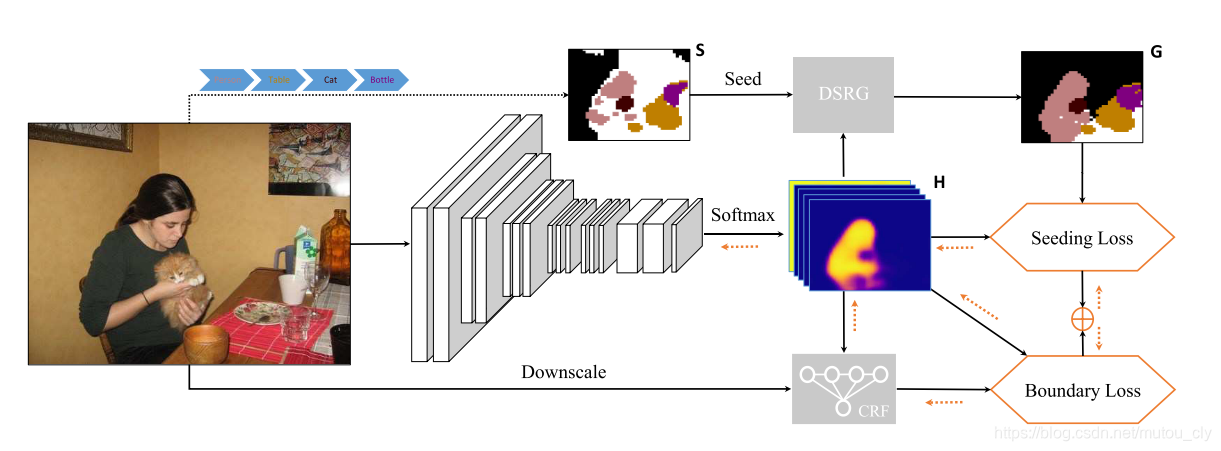
图中S表示由CAM获得的类别识别区域。主干网络接受RGB图像III,输出对应(N+1)(N+1)(N+1)个类别的(N+1)(N+1)(N+1)张feacher maps/score maps/heat maps/attention maps,分别记作Hc’,(c=0,1,2,...,N)H_{c’},(c=0,1,2,...,N)Hc’,(c=0,1,2,...,N)。
- 将(n+1)(n+1)(n+1)张feature maps 融合成最后的一张分割图记作HHH。Hu,cH_{u,c}Hu,c表示在HHH的像素uuu被判定为类别ccc的置信度。
Hu,c=argmaxHu,c′H_{u,c}=\arg \max H_{u,c'} Hu,c=argmaxHu,c′ - DSRG模块接受HHH和SSS作为输入,从种子区域SSS开始,依照HHH的信息进行扩展,扩展规则如下:
- 对于位置uuu被识别为类别ccc的种子区域记作Su,cS_{u,c}Su,c,遍历ScS_cSc临近的(8个邻接位置)中的还没被标识类别的待定位置记作Su′S_{u'}Su′。
- 如果Hu’H_{u’}Hu’也是被判定为类别ccc,且Hu′,cH_{u',c}Hu′,c的置信度高于阈值θ\thetaθ,则将点u′u'u′标识为类别ccc,更新Sc=Sc∪u′S_c=S_c\cup u'Sc=Sc∪u′。
- 结束所有的类别ccc的扩展后,会有很多待定区域被打上类别标识。尽管可能还有些区域还是待定。但是不管,在后续迭代中可能会被标识。
- 扩展之后我们得到了更新后的分割图GGG,对应之前的SSS有了更多的标识区域。
- GGG中现在有确定类别的点和待定的点,确定类别的点的置信度都设为1。将GGG作为label计算和HHH的交叉熵作为seed loss,注意计算交叉熵时只看确定标识的点。下式中CCC为前景类别,C‾\overline{C}C表示背景。
ℓ seed =−1∑c∈C∣Sc∣∑c∈C∑u∈SclogHu,c−1∑c∈C‾∣Sc∣∑c∈C‾∑u∈SclogHu,c\begin{aligned} \ell_{\text { seed }}=&-\frac{1}{\sum_{c \in \mathcal{C}}\left|S_{c}\right|} \sum_{c \in \mathcal{C}} \sum_{u \in S_{c}} \log H_{u, c}-\frac{1}{\sum_{c \in \overline{\mathcal{C}}}\left|S_{c}\right|} \sum_{c \in \overline{\mathcal{C}}} \sum_{u \in S_{c}} \log H_{u , c} \end{aligned}ℓ seed =−∑c∈C∣Sc∣1c∈C∑u∈Sc∑logHu,c−∑c∈C∣Sc∣1c∈C∑u∈Sc∑logHu,c - 为了获得更好的边界信息,所以作者在下面加了个CRF模块输入HHH,得到refined HHH,用于生成损失函数lboundaryl_{boundary}lboundary。作者没有详细说明,但估计使用细节与SEC中的lconstrainl_{constrain}lconstrain相同。
- 最终的loss即:
ℓ=ℓseed+ℓboundary\ell=\ell_{\text {seed}}+\ell_{\text {boundary}}ℓ=ℓseed+ℓboundary
compare to SEC
可以看到本文的框架和SEC有很大的相似之处。都包含了种子的损失lseedl_{seed}lseed和边界损失lboundaryl_{boundary}lboundary/lconstrainl_{constrain}lconstrain。
相同点:
- 种子的初始区域都是由CAM提供。
- 边界损失函数都是基于CRF。
不同点:
- 虽然两者的前景种子区域都是由CAM提供,但是获得背景种子区域使用的方法不同。
- 本文DSRG中的种子的损失函数lseedl_{seed}lseed是考虑了前景和背景的balance,而在SEC中没有考虑。实验表明balance带来了1.1%的优化。
- 为了获得扩展区域SEC是引入了lexpandl_{expand}lexpand刺激DCNN生成更大的区域,而本文DSRG是通过逐步迭代种子扩展,生成优化的label,更新SSS区域从而影响lseedl_{seed}lseed刺激DCNN生成更大的区域。
addition
- 基础框架使用VGG-16和Resnet101。
- 在DCNN收敛后能够获得语义分割图,那这些DCNN生成的分割图暴力上采样回原图大小后,作为label使用全监督的做法训练从头训练一个网络,这一retrain做法能带来1.4%的优化。但是在拿生成的分割图监督又一个新的网络没有得到明显的优化。
performance
| VOC val12 | VOC test12 | |
|---|---|---|
| baseline(SEC) [VGG16] | 52.5 | - |
| +BSL(balance) [VGG16] | 53.6 | - |
| +DSRG [VGG16] | 57.6 | - |
| Retrain [VGG16] | 59.0 | 60.4 |
| [Resnet101] | 61.4 | 63.2 |

















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









