




自从 Google 于 2017 年提出 Transformer,它已成为 NLP 和生成式 AI 模型的主流架构,彻底颠覆了传统 RNN、CNN 结构的局限。Transformer 最大的创新点在于:完全基于注意力机制,无需循环与卷积,实现高效的并行训练和全局信息捕获。
本文将围绕四个维度全面拆解 Transformer:
-
原理解析:三种核心注意力机制
-
模块架构:编码器与解码器的层级结构
-
数据流向表:结构与计算路径总览
-
模拟代码框架:模块划分与伪代码演示
一、Transformer 模型架构
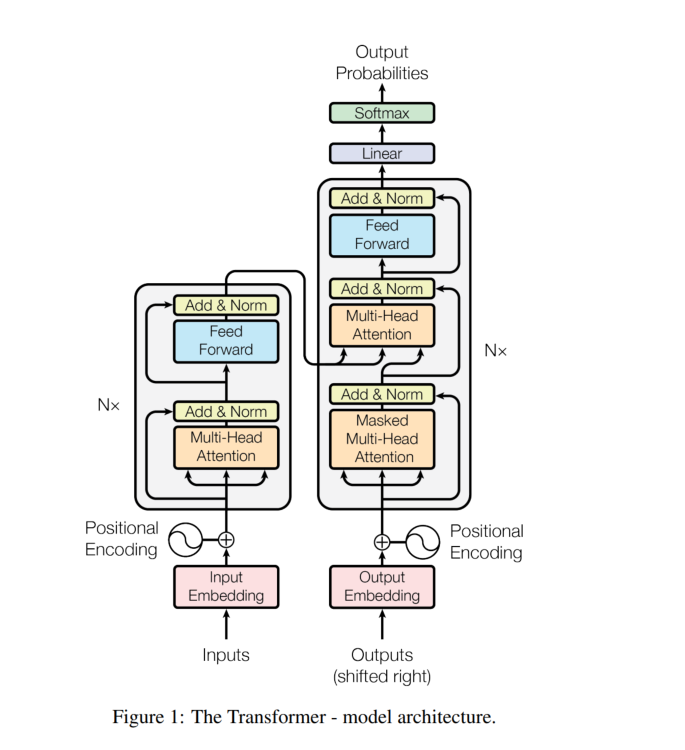
二、核心原理:注意力机制全解
Transformer 最核心的思想是 Attention is All You Need —— 注意力即一切。它使用注意力机制直接在输入序列的所有位置之间建立连接,从而有效建模长距离依赖。
✅三种关键注意力机制:
| 类型 | 使用位置 | Query 来源 | Key/Value 来源 | 是否 Mask | 用途说明 |
|---|---|---|---|---|---|
| 自注意力(Self-Attention) | 编码器 | 当前 token | 当前 token | ❌ 否 | 提取当前输入与上下文的关系 |
| 多头注意力(Multi-Head Attention) | 解码器 | 当前 token | 当前 token | ✅ 是 | 防止看到未来 token,保证生成顺序性 |
| 编码器-解码器注意力(融合注意力) | 解码器 | decoder token | encoder 输出 | ❌ 否 | 解码器融合编码器上下文信息 |
✅注意力机制公式

三、模块架构:编码器与解码器
Transformer 使用典型的 Encoder-Decoder 架构,每部分由若干重复层堆叠构成。
✅编码器结构(Encoder)
每层包括:
-
多头自注意力(Self-Attention)
-
残差连接 + LayerNorm
-
前馈网络(FFN)
-
残差连接 + LayerNor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2956
2956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









