




一 简介
初期接触LLM即大语言模型,觉得虽然很强大,但是有时候AI会一本正经的胡说八道,这种大模型的幻觉对于日常使用来说具有很大的误导性,特别是如果我们要用在生成环境下,由于缺少精确性而无法使用。 为什么会造成这种结果那,简单来说就是模型是为了通用性设计的,缺少相关知识,所以导致回复的结果存在胡说八道的情况,根据香农理论,减少信息熵,就需要引入更多信息。
从这个角度来说,就有两个途径,一是重新利用相关专业知识再次训练加强模型,或进行模型微调; 模型训练的成本是巨大的,微调也需要重新标记数据和大量的计算资源,对于个人来说基本不太现实; 二是在问LLM问题的时候,增加些知识背景,让模型可以根据这些知识背景来回复问题;后者即是知识库的构建原理了。
有个专门的概念叫RAG(Retrieval-Augmented Generation),即检索增强生成,是一种结合检索技术和生成模型的技术框架,旨在提升模型生成内容的准确性和相关性。其核心思想是:在生成答案前,先从外部知识库中检索相关信息,再将检索结果与用户输入结合,指导生成模型输出更可靠的回答。
二 RAG原理
简单概述,利用已有的文档、内部知识生成向量知识库,在提问的时候结合库的内容一起给大模型,让其回答的更准确,它结合了信息检索和大模型技术;
分步骤来说,首先是检索阶段,当用户输入一个问题时,系统会从外部数据库或文档中检索相关的信息或文档片段。然后,在生成阶段,这些检索到的信息会和原始问题一起输入到生成模型中,生成最终的答案。这样,模型不仅依赖于内部知识,还能利用外部实时或特定的数据。
我们日常简单通过chat交互方式使用大模型如下图: 我们搭建了RAG后,整体架构如下图:
我们搭建了RAG后,整体架构如下图: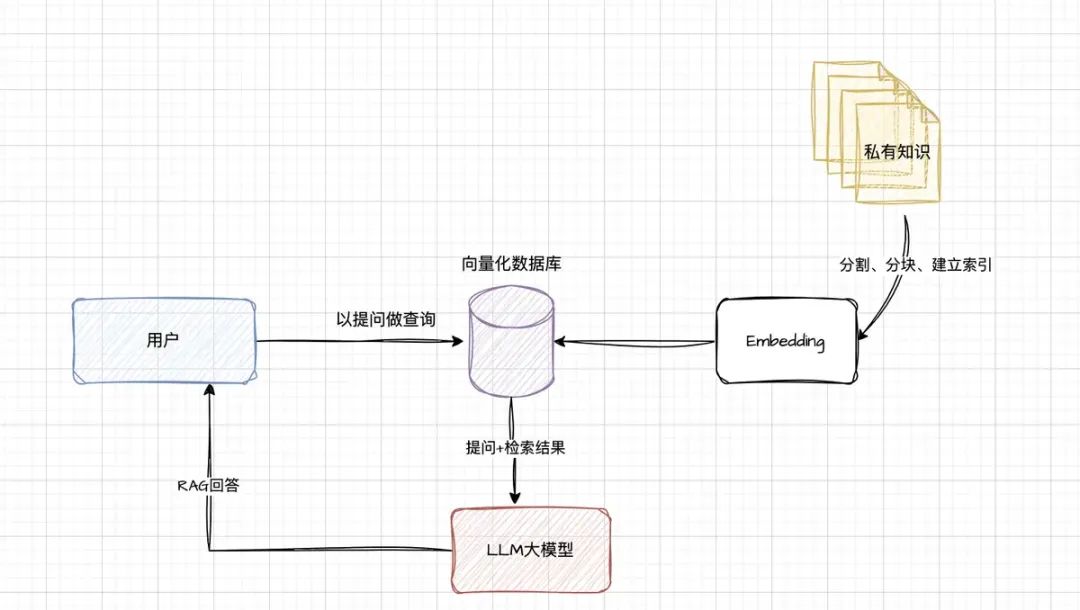
说明:
建立索引: 需要将日常的业务知识,以文件形式给分成较短的块(chunk),然后进行编码,向量化存入到向量化的库中;nomic-embe
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6448
6448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









