







【导读】 本文为大家整理了10篇CVPR2020上被评为Oral的论文解读和代码汇总。
1.RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Motivation:
本文的目标是设计一种轻量级,计算效率高(computationally-efficient)、内存占用少(memory-efficient)的网络结构,并且能够直接处理大规模3D点云,而不需要诸如voxelization/block partition/graph construction等预处理/后处理操作。然而,这个任务非常具有挑战性,因为这种网络结构需要:
-
一种内存和计算效率高的采样方法,以实现对大规模点云持续地降采样,确保网络能够适应当前GPU内存及计算能力的限制;
-
一种有效的局部特征学习模块,通过逐步增加每个点的感受野的方式来学习和感知复杂的几何空间结构。
基于这样的目标,我们提出了一种基于简单高效的随机降采样和局部特征聚合的网络结构(RandLA-Net)。该方法不仅在诸如Semantic3D和SemanticKITTI等大场景点云分割数据集上取得了非常好的效果,并且具有非常高的效率(e.g. 比基于图的方法SPG快了接近200倍)。本文的主要贡献包括以下三点:
-
我们对现有的降采样方法进行了分析和比较,认为随机降采样是一种适合大规模点云高效学习的方法
-
我们提出一种有效的局部特征聚合模块,通过逐步增加每个点的感受野来更好地学习和保留大场景点云中复杂的几何结构
-
RandLA-Net在多个大场景点云的数据集上都展现出了非常好的效果以及非常优异的内存效率以及计算效率
详细解读见:https://zhuanlan.zhihu.com/p/105433460
2.Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
主要解决的问题:
目前基于Deep learning的方法构建的3D Cost Volume需要3D卷积来做cost aggregation消耗显存非常大,为了节省内存一般最终输出的depth/disparity map限制为输入的1/4。
本文提出的方法:
- 把模型中单一的Cost Volume的形式更换为一种及联的多个Cost Volume,并且越靠后阶段的Cost Volume其depth/disparity hypothesis越少(依靠前阶段预测的结果),空间分辨率越高(使用更高分辨率的2D特征来恢复更多细节)。
实验结果:
- 在MVS上,相对于MVSNet,我们到模型在DTU上精度提升25%,GPU Mem使用量降低50.6%,运行时间降低59.3%。
- 在公开的benchmark上:DTU上性能排名第一,在Tank and Temples所有深度模型效果排名第一。
- 在KITTI Stereo上使用我们Cascade Cost Volume的形式将GwcNet从 29名提升到17名。
3.BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
4.AdderNet: Do We Really Need Multiplications in Deep Learning?
没有乘法的神经网络,你敢想象吗?去年年底,来自北京大学、华为诺亚方舟实验室、鹏城实验室的研究人员将这一想法付诸实践,他们提出了一种只用加法的神经网络AdderNet(加法器网络)。一作是华为诺亚方舟实习生,正在北大读博三。
在加法器网络的新定义下,AdderNet的特征可视化以及特征向量的空间分布也和CNN有很大的不同。
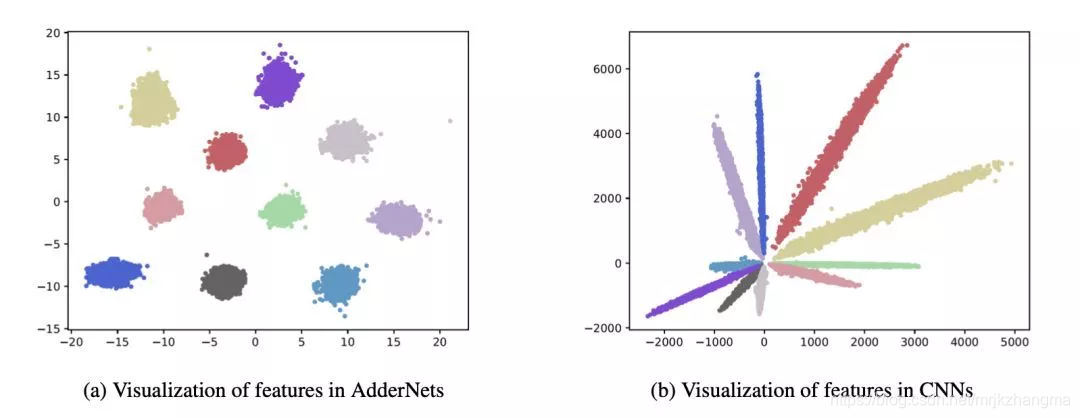
在CIFAR-10的图像分类任务中,AdderNet相比当初Bengio等人提出的加法神经网络BNN性能有大幅提升,并且已经接近了传统CNN的结果。在ImageNet的图像分类任务中,AdderNets可以达到74.9%的top-1正确率和91.7%的top-5正确率,与CNN接近。
5.Reinforced Feature Points: Optimizing Feature Detection and Description for a High-Level Task
本文解决了计算机视觉的核心问题之一:用于图像匹配的2D特征点的检测和描述。长期以来,像SIFT这样的算法在准确性和效率上都是无与伦比的。近年来,出现了使用神经网络来实现检测和描述学习型特征检测器,但用于训练这些网络low-level matching scores的改进并不一定会在高级视觉任务中有着更好的性能。本文提出了一种新的训练方法,该方法将特征检测器嵌入完整的视觉管道中,并以端到端的方式训练可学习的参数。并利用这一方法解决了一对图像之间的姿态估计任务。该训练方法几乎没有学习任务的限制,并且适用于预测key point heat maps以及descriptors for key point locations
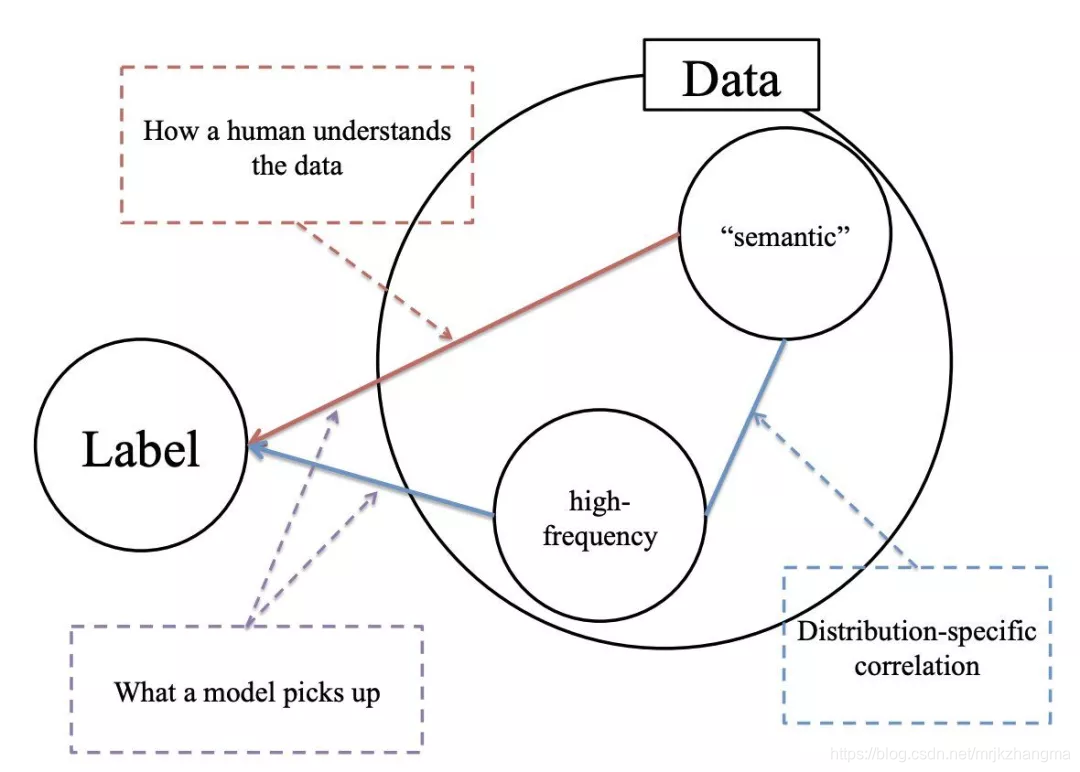
6.High Frequency Component Helps Explain the Generalization of Convolutional Neural Networks
本文研究了图像数据的频谱与卷积神经网络(CNN)的泛化之间的关系。我们首先注意到CNN捕获图像高频分量的能力。这些高频分量几乎是人类无法察觉的。因此,观察结果导致了与CNN泛化相关的多种假设,包括对对抗性示例的潜在解释,对CNN鲁棒性和准确性之间的权衡的讨论,以及在理解训练启发式方法方面的一些证据。
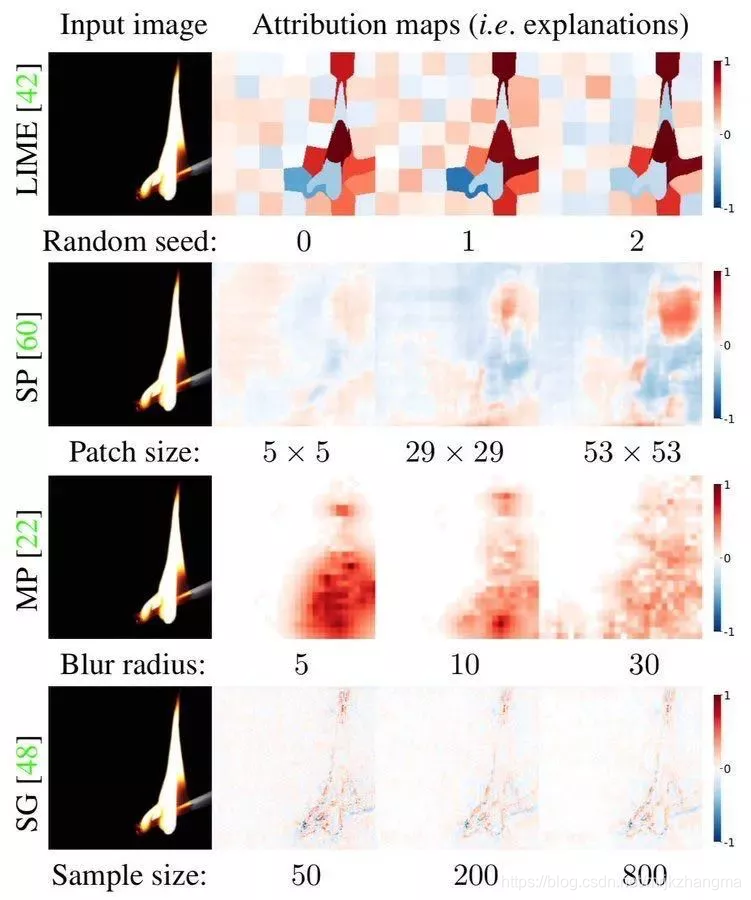
7. SAM: The Sensitivity of Attribution Methods to Hyperparameters
本文中对现有归因方法的敏感性进行了透彻的实证研究,发现了一个趋势:许多方法对它们共同的超参数的变化高度敏感,例如即使更改随机种子也会产生不同的解释!有趣的是,这种敏感性没有反映在文献中通常报道的数据集的average explanation accuracy scores 中。
8. Learning to Shade Hand-drawn Sketches
本文提供了一种全自动方法,可以从成对的线描草图和照明方向生成详细而准确的艺术阴影。还提供了一个新的数据集,其中包含了用照明方向标记的成对的线描和阴影的一千个示例。值得一提的是,生成的阴影可以快速传达草绘场景的基础3D结构。因此,本文的方法产生的阴影是可以直接使用的。本文生成的阴影尊重手绘线和基础3D空间,并包含复杂且准确的细节,例如自阴影效果。此外,生成的阴影还包含艺术效果,例如边缘照明或背光产生的光晕,这也是传统3D渲染方法可以实现的。

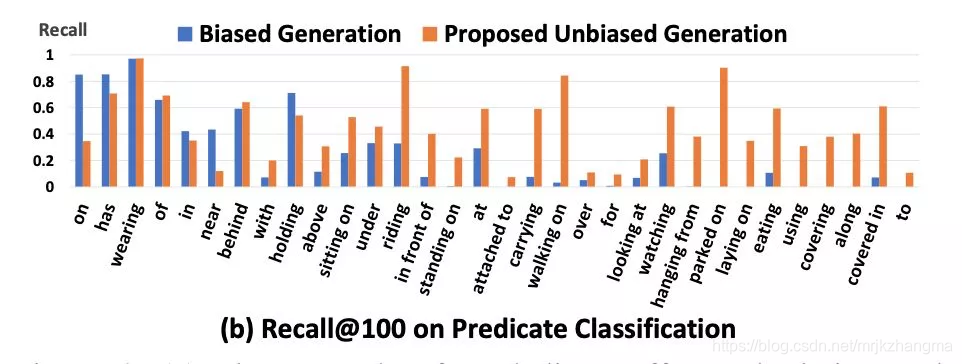
9.Scene Graph Generation开源框架
本文提出了一种基于因果推理的新颖SGG框架。选择2019年热门框架facebookresearch/maskrcnn-benchmark作为基础,在其基础上搭建了Scene-Graph-Benchmark.pytorch。该代码不仅兼容了maskrcnn-benchmark所支持的所有detector模型,且得益于facebookresearch优秀的代码功底,更大大增加了SGG部分的可读性和可操作性。
10.PolarMask: 一阶段实例分割新思路
PolarMask基于FCOS,把实例分割统一到了FCN的框架下。FCOS本质上是一种FCN的dense prediction的检测框架,可以在性能上不输anchor based的目标检测方法,让行业看到了anchor free方法的潜力。本工作最大的贡献在于:把更复杂的实例分割问题,转化成在网络设计和计算量复杂度上和物体检测一样复杂的任务,把对实例分割的建模变得简单和高效。
两种实例分割的建模方式:
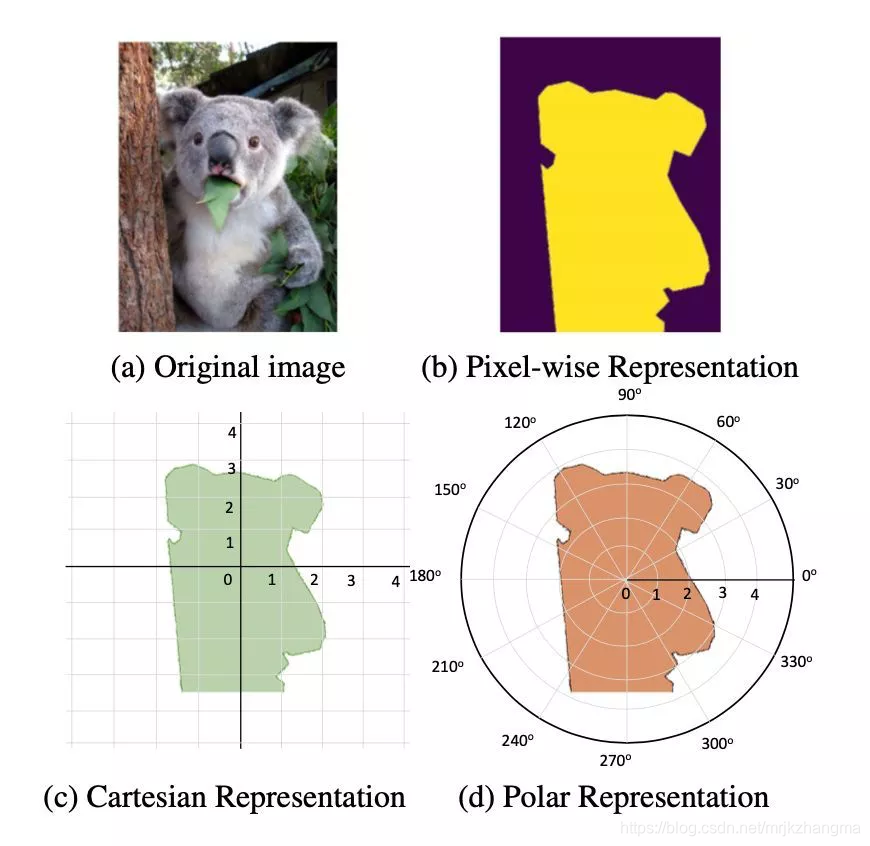
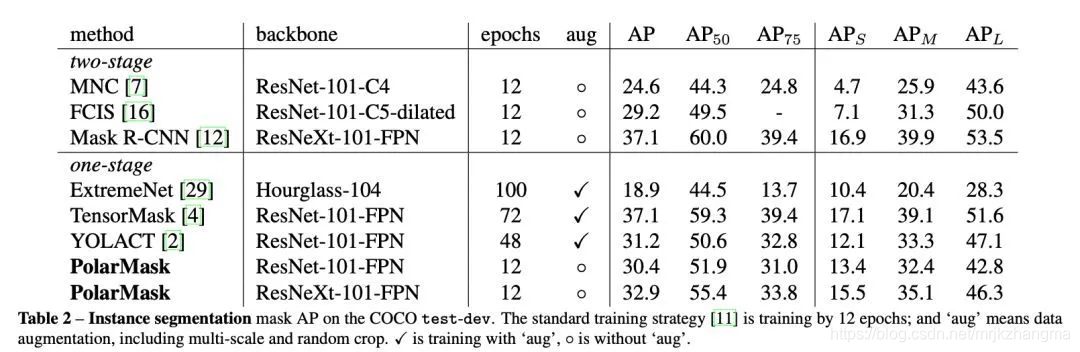
实验结果:
欢迎各位Cver加入计算机视觉微信交流大群,目前本群已有上百人,本群旨在交流图像分类、目标检测、点云/语义分割、目标跟踪、机器视觉、GAN、超分辨率、人脸检测与识别、动作行为/时空/光流/姿态/运动、模型压缩/量化/剪枝、迁移学习、人体姿态估计等内容。更有真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流等,欢迎加群交流学习!


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









