 Hadoop2.0 MapReduce作业执行流程与调优
Hadoop2.0 MapReduce作业执行流程与调优





 本文详细介绍了Hadoop2.0时代MapReduce作业的执行流程,包括作业提交、初始化、任务分配和执行,以及shuffle和排序过程。在调优方面,建议根据实际情况调整mapper和reducer的内存、个数,处理数据倾斜问题,并提供了关键参数的默认值和含义。此外,还提到了mapred.job.shuffle.input.buffer.percent和mapred.job.shuffle.merge.percent等参数对性能的影响。
本文详细介绍了Hadoop2.0时代MapReduce作业的执行流程,包括作业提交、初始化、任务分配和执行,以及shuffle和排序过程。在调优方面,建议根据实际情况调整mapper和reducer的内存、个数,处理数据倾斜问题,并提供了关键参数的默认值和含义。此外,还提到了mapred.job.shuffle.input.buffer.percent和mapred.job.shuffle.merge.percent等参数对性能的影响。
1.作业执行流程
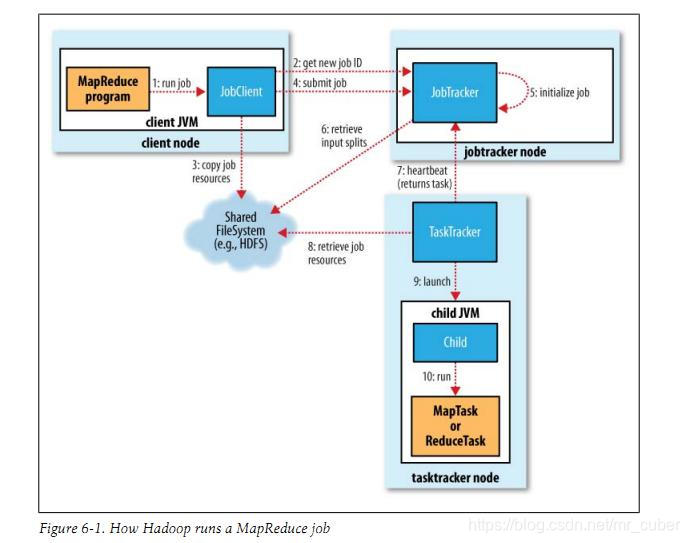
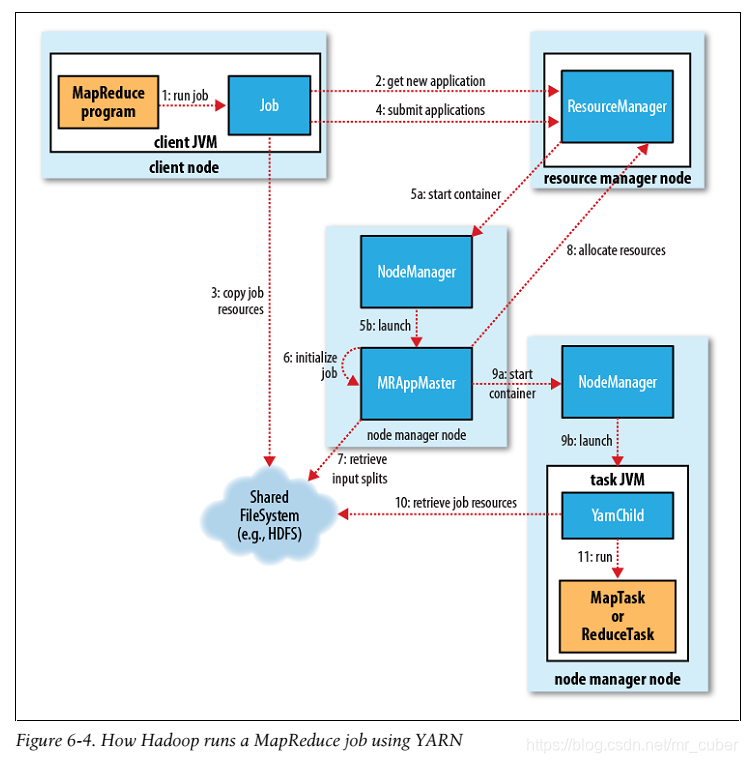
分别列了Hadoop 1.0时代、2.0时代的大体工作流
详述,仅关心2.0:
作业提交
1.客户端提交Job
2.向资源管理器请求一个application ID,等于job ID。
3.Job client核对job的输出规范,计算输入划分(input split),复制job resource(包括job JAR、配置文件和划分信息) 到HDFS,目录以job ID命名
4.最后通过调用资源管器的submitApplication()来提交job
5.当资源管理器收到一个submitApplication()请求,它会原封不动的传给scheduler。scheduler 分配一个容器,然后资源管理器运行主程序(application master)进程,在节点管理器的管理下
作业初始化
6.MapReduce jobs的application master 是一个主类为MRAppMaster的java程序。它通过创建一些保存job进度的对象来初始化job,同样的它将会收到从task提交的进度和完成报告
7.接受来自HDFS的、在客户端计算的输入分割(input split)
任务分配
8.如果一个任务不是uber task(小任务,AM选择和自己在同一个JVM上运行任务),application master 将会从资源管理器为job中所有的map reduce task 请求container,map任务还有数据本地化的局限,最好在分片所在的节点上,如果不行,就rack local。
mapper, reducer内存大小可以分别设置,默认都是1024M。
任务执行
9.当一个任务被资源管理器的scheduler分配了container之后,application master将会与node manager 联系来启动container。
10.这个任务被一个主类是YarnChild的JAVA 程序执行。在运行这个任务之前,它需要从HDFS复制运行任务需要的JAR 文件,配置文件等
11.开始运行map或者reduce task
shuffle和排序详解 http://shiyanjun.cn/archives/588.html
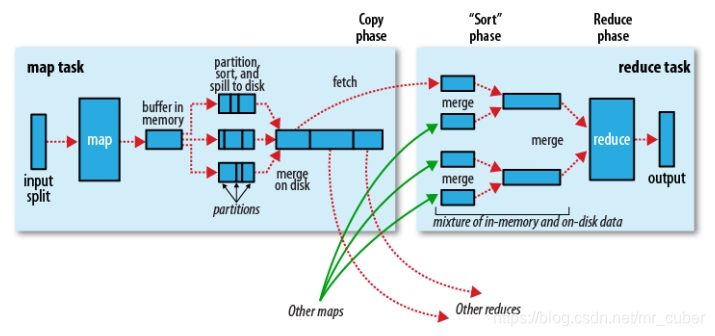
基本执行过程,描述如下:
- 一个InputSplit输入到map,会运行我们实现的Mapper的处理逻辑,对数据进行映射操作。
- map输出时,会首先将输出中间结果写入到map自带的buffer中(buffer默认大小为100M,可以通过io.sort.mb配置)。
- map自带的buffer使用容量达到一定门限(默认0.80或80%,可以通过io.sort.spill.percent配置),一个后台线程会准备将buffer中的数据写入到磁盘。
- 这个后台线程在将buffer中数据写入磁盘之前,会首先将buffer中的数据进行partition(分区,partition数为Reducer的个数),对于每个的数据会基于Key进行一个in-memory排序(快排)。
- 排序后,会检查是否配置了Combiner,如果配置了则直接作用到已排序的每个partition的数据上,对map输出进行化简压缩(这样写入磁盘的数据量就会减少,降低I/O操作开销)。
- 现在可以将经过处理的buffer中的数据写入磁盘,生成一个文件(每次buffer容量达到设置的门限,都会对应着一个写入到磁盘的文件)。
- map任务结束之前,会对输出的多个文件进行合并操作,合并成一个文件(若map输出至少3个文件,在多个文件合并后写入之前,如果配置了Combiner,则会运行来化简压缩输出的数据,文件个数可以通过min.num.splits.for.combine配置;如果指定了压缩map输出,这里会根据配置对数据进行压缩写入磁盘),这个文件仍然保持partition和排序的状态。
- reduce阶段,每个reduce任务开始从多个map上拷贝属于自己partition(map阶段已经做好partition,而且每个reduce任务知道应该拷贝哪个partition;拷贝过程是在不同节点之间,Reducer上拷贝线程基于HTTP来通过网络传输数据)。
- 每个reduce任务拷贝的map任务结果的指定partition,也是先将数据放入到自带的一个buffer中(buffer默认大小为Heap内存的70%,可以通过mapred.job.shuffle.input.buffer.percent配置),如果配置了map结果进行压缩,则这时要先将数据解压缩后放入buffer中。实践中若reduce阶段OOM频发,可以减小mapred.job.shuffle.input.buffer.percent
- reduce自带的buffer使用容量达到一定门限(默认0.66或66%,可以通过mapred.job.shuffle.merge.percent配置),或者buffer中存放的map的输出的数量达到一定门限(默认1000,可以通过mapred.inmem.merge.threshold配置),buffer中的数据将会被写入到磁盘中。实践中若reduce阶段OOM频发,可以减小mapred.job.shuffle.merge.percent,保证即使慢,任务也能运行成功。
- 在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。
- 当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件,这时开始执行合并操作,并保持每个map输出数据中Key的有序性,将多个文件合并成一个文件(在reduce端可能存在buffer和磁盘上都有数据的情况,这样在buffer中的数据可以减少一定量的I/O写入操作开销)。
- 最后,执行reduce阶段,运行我们实现的Reducer中化简逻辑,最终将结果直接输出到HDFS中(因为Reducer运行在DataNode上,输出结果的第一个replica直接在存储在本地节点上)。
2.调优
1.mapper, reducer内存、个数。通常mapper内存不需要很大,保持默认即可。如果mapper阶段内存不足,首先检查map逻辑是否有问题,如确有必要再增加。mapper如果执行时间过长(比如10分钟以上),可以考虑修改参数(减小blockSize或者减小mapred.min.split.size),以增大mapper数目。
mapreduce.reduce.memory.mb=4096;// container内存
mapreduce.map.memory.mb=2048;// container内存
mapreduce.reduce.java.opts='-Xmx7168m'; j//vm内存参数
mapreduce.map.java.opts='-Xmx1536m'; //jvm内存参数
2.数据倾斜
临床遇到倾斜,一般不管三七二十一先增大reducer数目、增大reducer内存,把任务重跑起来。再详细分析。如果是shuffle阶段失败,可以尝试减小mapred.job.shuffle.input.buffer.percent和mapred.job.shuffle.merge.percent,提前让reducer buffer中的数据写入磁盘,然后在reducer的逻辑中,对那些超多value的key做过滤,这样是有实际意义的。比如一个map key是用户id, 聚合发现此id单日的访问次数超过10000,肯定不合理。可以在reducer逻辑中提前过滤掉,避免所有数据读入内存中造成oom。
mapred.job.shuffle.input.buffer.percent
mapred.job.shuffle.merge.percent
3.mapreduce参数大全,参数名、默认值、含义

















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









