 CRF++ 实现中文实体识别
CRF++ 实现中文实体识别





 本文介绍如何使用 CRF++ 工具包在 Windows 平台上进行中文实体识别的任务,具体包括时间、人物、地点及组织机构名称的提取。文章提供了详细的步骤指导,从工具包与语料的下载、数据预处理、配置文件设置,到模型训练与测试的全过程。
本文介绍如何使用 CRF++ 工具包在 Windows 平台上进行中文实体识别的任务,具体包括时间、人物、地点及组织机构名称的提取。文章提供了详细的步骤指导,从工具包与语料的下载、数据预处理、配置文件设置,到模型训练与测试的全过程。
本文选用crf++工具包在windows上实现中文实体识别。任务是提取时间、人物、地点及组织机构名。
文件下载:
工具包下载:
官网:http://chasen.org/~taku/software/CRF++/#features
百度网盘:https://pan.baidu.com/s/1apZx8wd3xXGgMs_WUQeuSg
提取码:o7fh
语料文件下载
百度网盘:https://pan.baidu.com/s/1w-f_FJt3cZUWGenQzUPE3g
提取码:7dru
语料文件是人民日报1998中文标注语料库,工具包是crf+±0.58。
数据处理
- 数据编码格式
原始数据文件编码格式是gbk,需要将编码格式改为utf-8 - tags对应关系
/t 表示时间
/nr表示人名
/ns表示地名
/nt表示组织机构名 - 名字中的姓和名进行合并,如 江/nr 某某/nr 合并为 江某某/nr。
- 需要将语料转换为对应的标注,并将形如[华北/ns 电管局/n]nt进行合并,合并为华北电管局/nt
- 对时间进行合并,如12月/t 31日/t 合并为 12月31日/t
- 对特殊字符进行转换,对文中的全角字符转为半角字符。
- 特殊位置处理 ,对带有/的词处理,对未标注的词进行处理
- 用的是BMEWO做标注体系
以上处理流程在代码中均有显示。
代码地址:
百度网盘:https://pan.baidu.com/s/1c6rYRZK7Q1C2iNUyoK7FHQ
提取码:2195
配置文件
配置temple文件,内容如下:
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
# Bigram
B
模型训练
在解压的工具下,新建文件夹test,将crf_test.exe、crf_learn.exe、libcrfpp.dll同时拷贝到test下,将temple文件、train.data文件拷贝到test文件下,打开cmd文件,进入test文件夹,执行下列命令:
crf_learn -p 8 template train.data model
- -f, –freq=INT使用属性的出现次数不少于INT(默认为1)
- -p, –thread=INT线程数(默认1),利用多个CPU减少训练时间
训练过程如下:
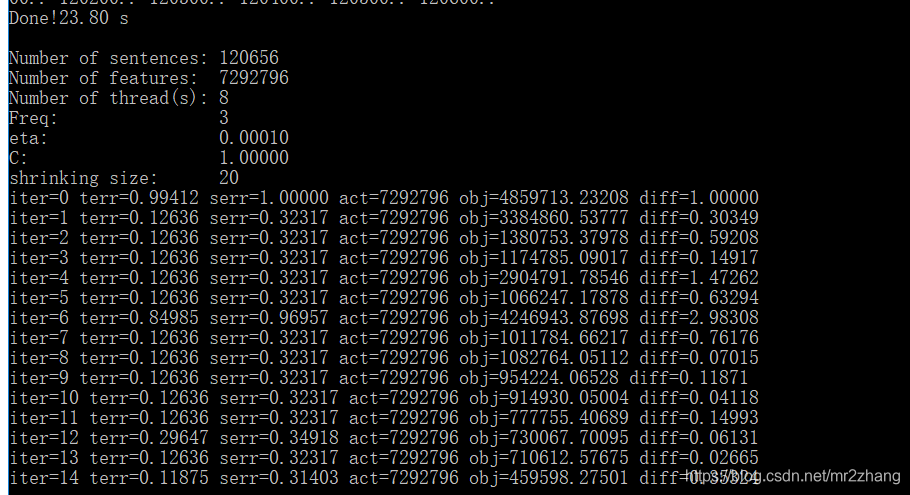
- ter:迭代次数 terr:标记错误率
- serr:句字错误率
- obj:当前对象的值。当这个值收敛到一个确定值的时候,训练完成
- diff:与上一个对象值之间的相对差
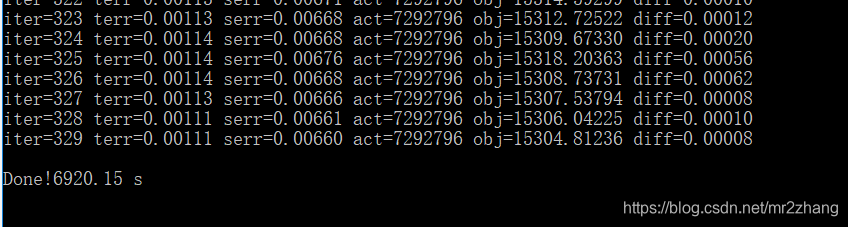
训练完成如图:
测试
执行下列命令:
crf_test -m model test.data > test.txt
查看test.txt文件即可,为最终的生成标识。这篇文章主要带大家简单粗暴实现流程,真正的优化过程见后续内容。

















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









