







Caffe学习(七)MTCNN人脸检测(caffe回归、多分类)
前言
本篇主要是叙述经典人脸识别MTCNN网络的原理,以及如何进行训练和测试。
准备阶段
caffe
MTCNN ( https://github.com/CongWeilin/mtcnn-caffe)
MTCNN
原文链接:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
MTCNN(多任务级联卷积神经网络)
MTCNN是2016年由中国科学院深圳研究院提出的用于人脸检测任务的多任务神经网络模型,其包含3个模型Pnet、Rnet、Onet。
其中开始阶段以及模型和模型之间用了图像金字塔、边框回归、非最大值抑制等技术。
整体流程
图像金字塔 - Pnet - NMS - Rnet - NMS - Onet
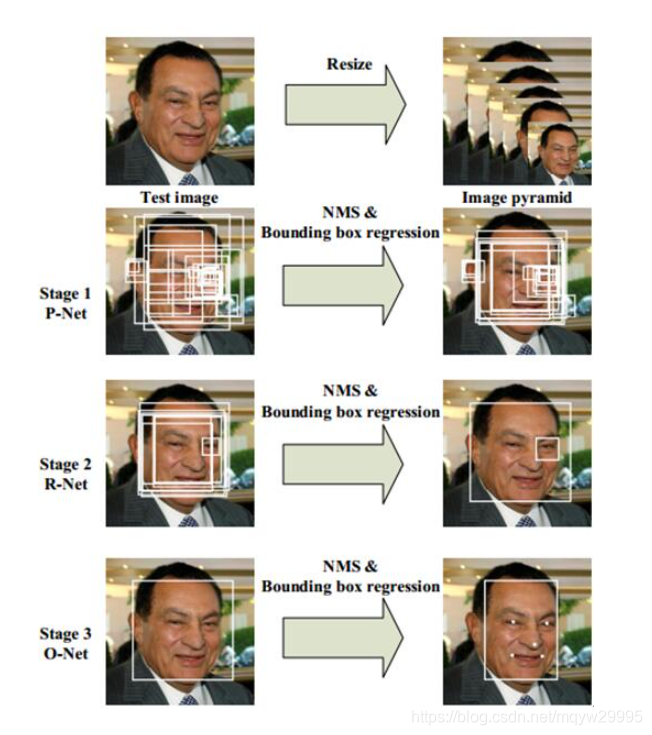
图像金字塔
图像金字塔:就是给定多个按一定比例缩放后原图像(大白话),比较正规的说法是:为了让适应不同大小的人脸,构建包含不同比例的图像金字塔送入网络中。
官方选择的缩放因子为0.709 ≈ sqrt(2) / 2 (应该是经过推理这是最佳选择的)
Pnet
经过金字塔缩放的图片会送入Pnet,也就会第一次进行分类和定位的过程。
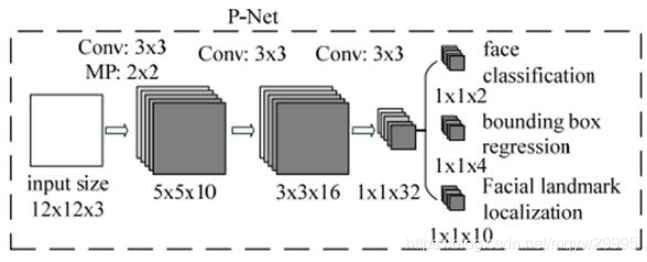
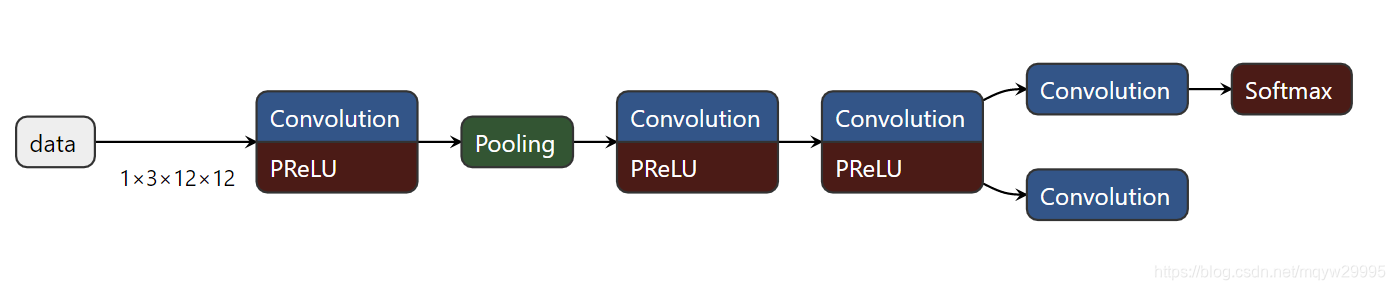
这是官方提供的网络模型结构,可以看到Pnet最后是采用卷积连接而没有添加全连接,这样就可以支持多尺度输入以及初步定位人脸的位置。事实上我们再做Pnet训练的时候只采用了类别判断和回归框修正两条分支,而Pnet由于输入的是多张缩放图且其实根据缩放大小的不同而进行图像的扫描定位,所以导致在Pnet后出来的人脸回归框必然比较多的。这个时候就需要使用NMS来剔除重合度比较高的部分。
Rnet
在Pnet的结果进过NMS剔除重合度高的回归框后,剩下的回归框就会被送入Rnet,Rnet实际上是对Pnet的结果再筛选的过程。
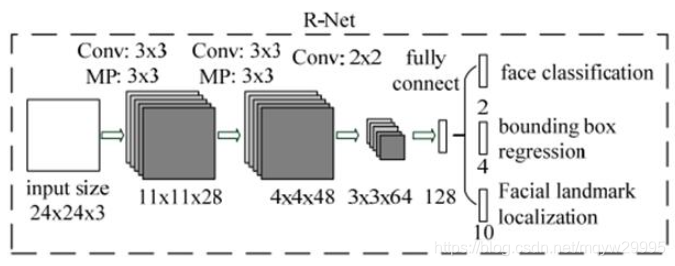

可以看到Rnet最后有引入全连接层,也就是Rnet必须保证输入的尺度是1324*24,且返回结果也只有一个结果(但是输入的回归框有多个,所以结果最后可能不唯一)。到Rnet出来的结果也是只有分类判断结果和回归框结果,并且结果还是通过NMS进行筛选,此时输出的结果一般就不会太多了。
Onet
在Rnet的结果进过NMS剔除重合度高的回归框后,剩下的回归框就会被送入Onet,Onet是最后一步筛选以及确定回归框,以及关键点。
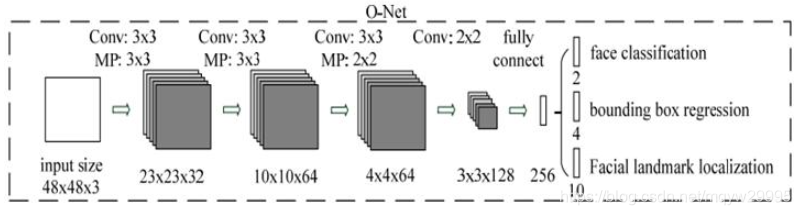

Onet比前两个网络多了一个关键点的输出,最后会输出回归框的修正值,关键点的预测值,以及分类的结果(类别,置信值)。
总结
特别说明:
NMS(非极大抑制):即排除不是最大值的值,该处理是剔除定位重合率高且相对更不准确的回归框,也就是这个处理很可能会剔除高重叠度的人脸。
IOU:两个区域重叠的部分除以两个区域的集合部分得出的结果,简单说来就是交集/合集。
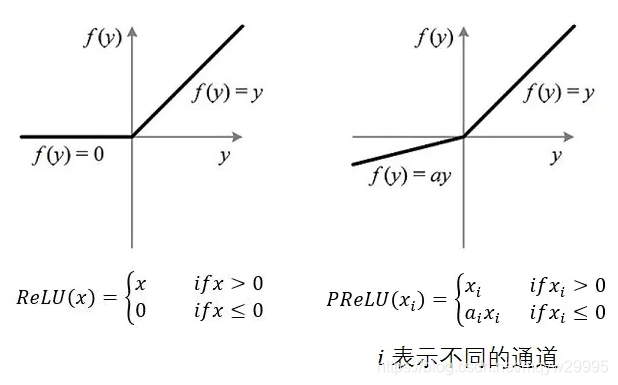
PRelu:带参数的Relu,跟Relu主要差别在负值的处理。
一些理解:
MTCNN(Multi-task Cascaded Convolutional Networks):采用的是三个网络分批次进行定位,第一个网络Pnet输入为1212的尺度,且网络一共4层卷积这里主要是为了以极小的代价初步定位出人脸的相对位置,然后再通过Rnet(输入为2424的尺度,网络有4层卷积、1层全连接)再次进行对回归框的筛选和大小修正,最后再通过Onet(输入为24*24的尺度,网络有4层卷积、2层全连接)来确定回归框和人脸以及人脸的关键点。
这里MTCNN是采用3个网络层层递进的处理方案,先用小的网络进行初步筛选,再用相对合理的网络进行再次的筛选,最后再用相对复杂的网络进行最后回归框的修正以及给出人脸的定位点(需要注意的是Pnet是再整张图上定位,Rnet和Onet是再定位到的回归框上进行修正和判断)。
训练
caffe回归和多分类
参考网址:
https://blog.youkuaiyun.com/wwww1244/article/details/81034045
PS:这里caffe多分类和回归用的lmdb的并且修改了之后可能会导致原来单分类不能使用,所以最好再备份一个caffe
1、修改 tools/convert_imageset.cpp:主要是为了生成多标签lmdb数据
line:28
#include <iostream>
#include <boost/tokenizer.hpp>
line:79
std::vector<std::pair<std::string, std::vector<float> > > lines;
std::string line;
size_t pos;
std::vector<float> labels;
line:85
std::vector<std::string> tokens;
boost::char_separator<char> sep(" ");
boost::tokenizer<boost::char_separator<char> > tok(line, sep);
tokens.clear();
std::copy(tok.begin(), tok.end(), std::back_inserter(tokens));
for (int i = 1; i < tokens.size(); ++i)
labels.push_back(atof(tokens.at(i).c_str()));
lines.push_back(std::make_pair(tokens.at(0), labels));
labels.clear();
// This program converts a set of images to a lmdb/leveldb by storing them
// as Datum proto buffers.
// Usage:
// convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
//
// where ROOTFOLDER is the root folder that holds all the images, and LISTFILE
// should be a list of files as well as their labels, in the format as
// subfolder1/file1.JPEG 7
// ....
#include <algorithm>
#include <fstream> // NOLINT(readability/streams)
#include <string>
#include <utility>
#include <vector>
#include "boost/scoped_ptr.hpp"
#include "gflags/gflags.h"
#include "glog/logging.h"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/db.hpp"
#include "caffe/util/format.hpp"
#include "caffe/util/io.hpp"
#include "caffe/util/rng.hpp"
#include <iostream> //###
#include <boost/tokenizer.hpp> //###
using namespace caffe; // NOLINT(build/namespaces)
using std::pair;
using boost::scoped_ptr;
DEFINE_bool(gray, false,
"When this option is on, treat images as grayscale ones");
DEFINE_bool(shuffle, false,
"Randomly shuffle the order of images and their labels");
DEFINE_string(backend, "lmdb",
"The backend {lmdb, leveldb} for storing the result");
DEFINE_int32(resize_width, 0, "Width images are resized to");
DEFINE_int32(resize_height, 0, "Height images are resized to");
DEFINE_bool(check_size, false,
"When this option is on, check that all the datum have the same size");
DEFINE_bool(encoded, false,
"When this option is on, the encoded image will be save in datum");
DEFINE_string(encode_type, "",
"Optional: What type should we encode the image as ('png','jpg',...).");
int main(int argc, char** argv) {
#ifdef USE_OPENCV
::google::InitGoogleLogging(argv[0]);
// Print output to stderr (while still logging)
FLAGS_alsologtostderr = 1;
#ifndef GFLAGS_GFLAGS_H_
namespace gflags = google;
#endif
gflags::SetUsageMessage("Convert a set of images to the leveldb/lmdb\n"
"format used as input for Caffe.\n"
"Usage:\n"
" convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME\n"
"The ImageNet dataset for the training demo is at\n"
" http://www.image-net.org/download-images\n");
gflags::ParseCommandLineFlags(&argc, &argv, true);
if (argc < 4) {
gflags::ShowUsageWithFlagsRestrict(argv[0], "tools/convert_imageset");
return 1;
}
const bool is_color = !FLAGS_gray;
const bool check_size = FLAGS_check_size;
const bool encoded = FLAGS_encoded;
const string encode_type = FLAGS_encode_type;
std::ifstream infile(argv[2]);
// std::vector<std::pair<std::string, int> > lines;
std::vector<std::pair<std::string, std::vector<float> > > lines; //###
std::string line;
size_t pos;
// int label; //###
std::vector<float> labels; //###
while (std::getline(infile, line)) {
//###
// pos = line.find_last_of(' ');
// label = atoi(line.substr(pos + 1).c_str());
// lines.push_back(std::make_pair(line.substr(0, pos), label));
//###
std::vector<std::string> tokens;
boost::char_separator<char> sep(" ");
boost::tokenizer<boost::char_separator<char> > tok(line, sep);
tokens.clear();
std::copy(tok.begin(), tok.end(), std::back_inserter(tokens));
for (int i = 1; i < tokens.size(); ++i)
labels.push_back(atof(tokens 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4455
4455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









