






 本文探讨了坐标MLP中激活函数的作用,揭示正弦激活并非唯一有效选项。提出了一类非周期函数,它们在随机初始化下更稳健,特别强调了高斯激活在编码性能、收敛速度和架构深度上的优势。实验验证了新激活函数在无位置嵌入任务中的优越性。
本文探讨了坐标MLP中激活函数的作用,揭示正弦激活并非唯一有效选项。提出了一类非周期函数,它们在随机初始化下更稳健,特别强调了高斯激活在编码性能、收敛速度和架构深度上的优势。实验验证了新激活函数在无位置嵌入任务中的优越性。
Beyond Periodicity: Towards a Unifying Framework for Activations in Coordinate-MLPs (arXiv 2021)
Paper:https://arxiv.org/abs/2111.15135
2022/6/13: 这段时间都是把师弟之前推荐给我的论文看完,明天就要去另一个实验室了,到那边不知道发的钱能不能多一些。每个月再多发一千我就谢天谢地。
Abstract
基于坐标的MLPs正成为建模多维连续信号的有效工具,克服了许多与离散网格近似的缺点。然而,具有ReLU激活的坐标mlp,在其基本形式中,在高保真度表示信号时表现出较差的性能,促进了对位置嵌入层的需求。最近, Sitzmann等人[39]提出了一个使用正弦激活函数的SIREN,该函数能够在保持高信号保真度的同时,从坐标MLPs中省略位置嵌入。尽管具有潜力,ReLUs仍在坐标MLPs领域占据主导地位; 我们推测,这是由于网络对初始化方案的超敏感(使用这种正弦激活)。在这篇论文中,我们试图拓宽当前对坐标MLPs中激活作用的理解,并表明存在更广泛适合编码信号的一类激活。我们确认正弦波激活只是这个类中的一个例子,并提出了几个非周期函数,这些函数在随机初始化时比正弦波具有更强的鲁棒性能。最后,我们提倡向采用这些非传统激活函数的坐标MLPs转变,因为它们具有高性能和简单性。
1. Introduction
尽管传统的离散表示在机器学习中普遍存在并成功使用(例如图像、3D网格、3D点云等),坐标
MLP现在作为一种独特的工具出现,可以将多维信号表示为连续可微实体。坐标MLPs——也叫做隐式神经表示-是将连续信号编码为权重的全连接网络,使用低维坐标作为输入。和基于网格的离散表示方式相比,这种连续表示方法更为强大,因为他们可以查询到极高分辨率下的信号值。此外,基于网格的表示的内存消耗伴随着数据的维度和分辨率的指数增长速度,神经表征在上述因素之间表现出更为紧凑的关系。因此,这一最近的趋势引起了视觉相关研究的激增,包括纹理生成的研究、形状表示和多视点合成。
尽管有上述有点,基于坐标的MLPs,他们的基本形式,在配备了常用激活函数类似于ReLU的网络往往在编码信号的高频分量时表现不佳。这背后的一个基本原因是MLPs的光谱偏差。即MLPs对应的神经切线核(NTK)容易出现高频下降,影响其对高频函数的学习能力。 对这个问题的普遍解决方法包括在MLP之前应用一个位置嵌入层,其中低维输入使用傅里叶特征[42]投影到高维空间。
相比之下,Sitzmann等人[39]最近描述具有正弦激活函数的MLPs自然适合编码高频信号,从而消除了位置嵌入层的需要。尽管有其潜力,许多涉及坐标MLPs的研究仍然更喜欢位置嵌入而不是正弦激活。 我们认为这可能有两个原因。首先,Sitzmann等人将正弦激活的成功主要归因于其周期性,尽管这种关系的证据仍然不足。 因此,这种理解的缺乏混淆了其有效性背后的一些基本原则,并妨碍了在更广泛的应用中忠实地使用它。其次,正弦激活对MLP的初始化非常敏感,在没有严格遵守SIREN with Sin初始化引导的情况下,会出现显著的性能下降。 上述缺点使我们更加需要更严格的分析,以便更有效地使用坐标MLPs中的激活函数。

Contributions: :我们对坐标MLP中激活函数的作用提供了更广泛的理论理解。特别地,我们证明了一个坐标MLPs的有效性与它的Lipschitz平滑性和隐藏层表示的特征值分布密切相关,这些度量的最优值取决于需要编码的信号的特征。我们进一步表明,上述属性内在地相互联系,通过控制一个属性,可以隐式地操纵另一个属性。我们进一步推导了将Lipschitz光滑性和本征值分布与激活函数性质联系起来的公式。这一发现的意义有两方面:(i)提供基于给定信号和调优激活函数超参数的指导方针,(ii)使实践者能够在实际实施之前,从理论上预测给定激活函数在坐标MLP中使用时的效果。 我们进一步表明,正弦激活只是满足这些约束的一个简单例子,而周期性不是决定激活函数有效性的一个关键因素。因此,我们提出了一个更广泛的非周期激活函数类,可以用于高保真的编码函数或信号,并证明它们的经验性质与理论预测相符。我们进一步说明,新提出的激活函数对不同的初始化方案是鲁棒的,不同于SIREN with Sin。此外,以高斯激活为例,我们证明了与ReLU-MLPs相比,具有这种激活函数的坐标mlps具有更好的结果、更快的收敛速度和更浅的架构。 最后,我们展示了这些激活允许在复杂的任务如3D视图合成中使用位置嵌入自由架构。据我们所知,这是第一个在没有位置嵌入的情况下成功地将坐标MLP应用于此类实验的实例。
2. Related Works
激活函数: (非线性)激活函数是任何旨在模拟复杂函数及其坐标之间关系的模型的重要组成部分。这些激活极大地扩展了人们可以近似的信号/函数的类别。自神经网络研究的早期,激活函数的作用就得到了广泛的研究[3,8,24,45]。也许,关于激活的理论性质的第一个值得注意的讨论是由Williams等人[45]提出的,其中探讨了输入的逻辑和序数保持变换下的非线性不变性。Dasgupta等人[6]比较了不同激活的前馈神经网络的逼近能力。最初的工作是一系列的分析研究,包括不连续的[12,13,19],基于多项式的[20]和Lipschitz有界的[4,16,17]激活函数。除此之外,大量的实证研究也发表了[14,29,32,36,37]。周期性非线性也在傅立叶特征网络[9,38]、循环神经网络[15,18]和分类任务方面进行了探索[41,46]。
基于坐标的MLPs: 近年来,人们对使用神经网络(也称为坐标MLPs)参数化信号越来越感兴趣,这主要归功于Mildenhall等人[22]的开创性工作。坐标MLPs的使用与传统MLPs有些不同:i)传统mlp通常处理高维输入,如图像、声音或3D形状,ii)主要用于分类目的,其中决策边界不必保持平滑。相反,使用坐标MLP将信号编码为权值,其中输入是低维坐标,输出必须保持平滑[49]。Mildenhall等人的工作中最显著的一个方面包括证明了这种神经信号表示的泛化特性,例如,一旦在某组视点图中训练良好,坐标MLP可以从任意角度重构出具有精细细节的视图投影。这一突破性的演示引发了一系列研究,其中包括将神经信号表征作为包括形状表征和新视点合成在内的许多应用程序的核心实体。:然而,为了获得最佳性能,这些坐标MLP必须使用位置嵌入,这允许它们对高频函数进行编码。相比之下,Sitzmann等人[39]提出了正弦激活,使坐标mlps能够在没有位置嵌入的情况下以更高的质量编码信号。然而,正弦波激活对MLPs的初始化方案极其敏感。此外,由Sitzmann等人开发的框架仅限于周期性激活。相反,我们的工作概括了当前对坐标MLP中激活效果的理解,从而提出了一类在随机初始化下鲁棒的非周期性激活。
3. Methodology
符号表示: 实 n n n维向量集表示为 R n \R^n Rn,向量使用小写粗体表示,例如 x \bf{x} x。 m × n m \times n m×n维的矩阵集表示为 R m × n \R ^{m \times n} Rm×n,矩阵使用大写粗体表示,例如 A \bf{A} A。 S r n \mathbb{S}^n_r Srn 和 B r n \mathbb{B}^n_r Brn代表半径为 r r r的 n n n维超球和 n n n维球的表面。 ∣ ∣ ⋅ ∣ ∣ || \cdot || ∣∣⋅∣∣表示向量范数, ∣ ∣ ⋅ ∣ ∣ F || \cdot ||_F ∣∣⋅∣∣F代表矩阵范数, ∣ ∣ ⋅ ∣ ∣ o || \cdot ||_o ∣∣⋅∣∣o代表算子范数。 J ( f ) x J(f)_x J(f)x代表 f f f在 x \bf{x} x处的雅克比矩阵值, A ⋅ x A \cdot \bf{x} A⋅x代表 A A A和 x \bf{x} x的矩阵乘法。
大纲: 本节的组织如下。在3.1节中,我们将重点讨论MLP记忆数据的能力,并建立其与隐含层表示秩的连接。第3.2节探讨了MLP的泛化,并将其与隐藏层表示的平滑性联系起来。在第3.3节中,我们展示了上述因素自然地相互联系,并面临着隐含的权衡。最后,第3.4节将前面章节得到的见解与激活函数的特性联系起来。
3.1 Rank and Memorization
坐标MLP的有效性很大程度上取决于它记忆训练数据的能力。本节的目的是找出影响记忆的关键因素。为了建立我们分析的基础,我们首先回顾MLP的制定。一个具有
k
−
1
k-1
k−1个非线性隐含层的MLP,其顶部为线性层,可以用以下方程描述:
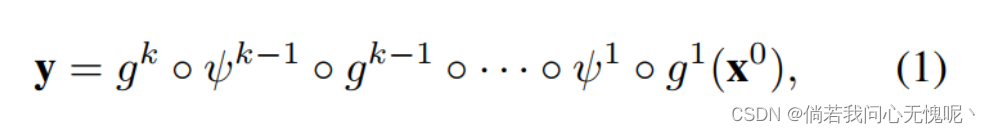
其中
g
i
:
x
→
A
i
⋅
x
+
b
i
g^i:x \rightarrow A^i \cdot \bf{x} +\bf{b}^i
gi:x→Ai⋅x+bi是带有训练权重
A
i
∈
R
d
i
m
(
x
i
)
×
d
i
m
(
x
i
−
1
)
A^i \in \R^{dim(x^i) \times dim(x^{i-1})}
Ai∈Rdim(xi)×dim(xi−1),和偏差
b
i
∈
R
d
i
m
(
x
i
)
b^i \in \R^{dim(x^i)}
bi∈Rdim(xi)的仿射投影,
ψ
i
\psi^i
ψi是非线性函数。最后一层本质上是一个线性分类器,作用于三维非线性嵌入
ϕ
(
x
0
)
\phi(\bf{x}^0)
ϕ(x0)将低维坐标
x
0
\bf{x}^0
x0投影到
R
D
\R^D
RD的一个子空间中,其中
d
i
m
(
x
k
−
1
)
=
D
dim(x^{k-1})=D
dim(xk−1)=D。若训练点个数为
N
N
N,则定义总(训练)嵌入矩阵为
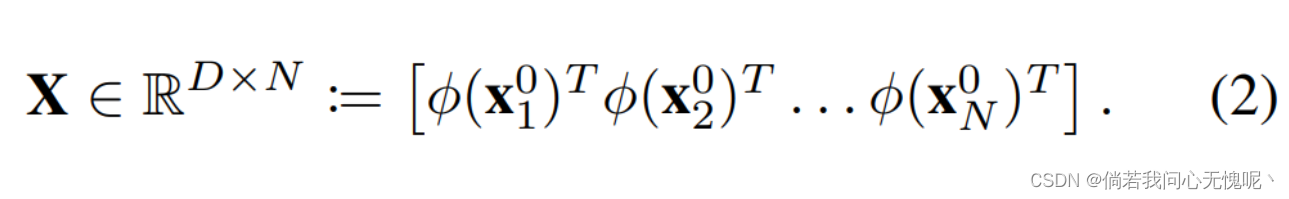
回想一下,MLP的最后一层(通常)是没有任何非线性的仿射投影。抛开对简化符号的偏见,我们得到,

其中
Y
∈
R
q
×
N
\bf{Y} \in \R^{q \times N}
Y∈Rq×N并且
q
q
q表示输出的维度。注意到Y的每一行都是X的每一行的线性组合。假设我们没有Y的先验知识,也就是说,Y的行可以是
R
N
\R^N
RN中的任意向量。另一方面,如果X的行是线性无关的,它们构成
R
N
\R^N
RN的一组基。 因此,当
r
a
n
k
(
x
)
=
N
rank(\bf{x})=N
rank(x)=N时,在假设完全收敛的情况下,可以保证MLP能够找到一个保证完全重构
Y
\bf{Y}
Y的权重矩阵
A
k
\bf{A}^k
Ak。严格地说,到目前为止,分析只考虑了倒数第二层。然而,根据收集到的见解,我们做出以下一般性的断言:隐层诱导高阶表示的潜力与坐标MLP的记忆能力有关。等价地,这个表达式的特征值应该是非零的。
然而,在上述分析中忽略了一个关键组件。在许多利用坐标MLPs的应用程序中,能够在不可见的测试坐标上预测值是一个重要的属性。 例如,在一个3D场景的新视图合成中,网络只观察少数视图,然后网络必须从新的角度预测视图。因此,直接的问题出现了拥有非零特征值就足够了吗? 在第3.2节中,我们将看到事实并非如此。
3.2 Smothness and generalization
在本节中,我们展示了一个坐标MLP的泛化与关于输出变化的表示的局部平滑性紧密相关。
Proposition 1: 令
f
(
x
)
:
R
→
R
f(x): \R \rightarrow \R
f(x):R→R且
y
=
[
y
1
,
y
2
,
⋯
,
y
n
]
\bf{y} = [y_1,y_2,\cdots,y_n]
y=[y1,y2,⋯,yn]和
x
=
[
x
1
,
x
2
,
⋯
,
x
n
]
\bf{x} = [x_1,x_2,\cdots,x_n]
x=[x1,x2,⋯,xn]是从
f
f
f函数的输入和目标中分别采样得到的。令
ϕ
(
x
i
)
:
R
→
R
D
\phi(x_i): \R \rightarrow \R^D
ϕ(xi):R→RD是一个D维的嵌入。假设我们训练一个线性分类器,得到
A
∈
R
1
×
D
\bf{A} \in \R^{1 \times D}
A∈R1×D使得
y
i
=
A
ϕ
(
x
i
)
,
∀
y
i
∈
y
,
x
i
∈
x
y_i = \bf{A} \phi(x_i), \forall y_i \in \bf{y},x_i \in x
yi=Aϕ(xi),∀yi∈y,xi∈x。为了保持对不可见点的回归
(
y
ˉ
,
x
ˉ
)
(\bar{y},\bar{x})
(yˉ,xˉ)作为
y
ˉ
=
A
ϕ
(
x
ˉ
)
\bar{y} = \bf{A} \phi(\bar{x})
yˉ=Aϕ(xˉ),其中
y
ˉ
=
f
(
x
ˉ
)
\bar{y}=f(\bar{x})
yˉ=f(xˉ)且
x
j
<
x
ˉ
<
x
i
x_j < \bar{x} <x_i
xj<xˉ<xi,平滑约束
∣
∣
ϕ
(
x
i
)
−
ϕ
(
x
j
)
∣
∣
=
K
∣
x
i
−
x
j
∣
||\phi(x_i)-\phi(x_j)||=K|x_i-x_j|
∣∣ϕ(xi)−ϕ(xj)∣∣=K∣xi−xj∣应该在局部保持。(这里的意思是这个函数应该在局部内是平滑的而不是存在断点或者说不可导的地方) 这里,
x
i
,
x
j
x_i,x_j
xi,xj表示
x
ˉ
\bar{x}
xˉ左右两边的一个开区间。则结论为
∣
x
i
−
x
j
∣
→
0
,
K
∝
d
(
f
(
x
)
)
/
d
x
f
o
r
x
j
<
x
<
x
I
|x_i -x_j | \rightarrow 0, K \propto d(f(x))/dx \quad for \quad x_j <x<x_I
∣xi−xj∣→0,K∝d(f(x))/dxforxj<x<xI。
尽管上述条件似乎过于严格,回想一下,嵌入
ϕ
(
⋅
)
\phi(\cdot)
ϕ(⋅)是通过隐藏层学习的,而不是通过分析设计的。因此,相对于明确地强制上述约束,相应地减少参数的搜索空间就足够了。因此,我们可以稍微放宽上述等式为不等式的Lipschitz平滑性。更确切地说,在实践中,这足以确保
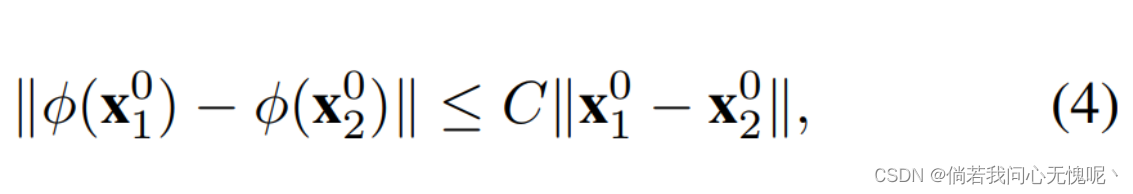
在局部,非负常数C依赖于编码信号的局部一阶导数(即频率)的大小(因为在命题1中C是K的替代品)。即编码高频信号时,C需要更高,反之亦然。从这一点开始,我们去掉
x
i
\bf{x}_i
xi的上标,以避免混乱的符号。
到目前为止,我们已经确定了X的特征值与可见坐标的记忆性有关, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)的平滑度与MLP的泛化性能有关。因此,研究这两种力量在基本层面上是否存在联系是很有趣的,因为这样的分析有可能提供有价值的见解,从而有效地操纵这些因素。
3.3 Smoothness vs. eigenvalue distribution
这一节致力于探索平滑性和隐藏表示的特征值分布之间的相互关系。为了简单起见,假设坐标
x
i
\bf{x}_i
xi在给定的小邻域内,则相应的
{
ϕ
(
x
i
)
}
i
=
1
N
\{\phi(\bf{x}_i)\}_{i=1}^N
{ϕ(xi)}i=1N在
S
r
D
\mathbb{S}^D_r
SrD上。进一步假设
ϕ
(
⋅
)
\phi(\cdot)
ϕ(⋅)是一个常数
C
C
C的Lipschitz界,那么,
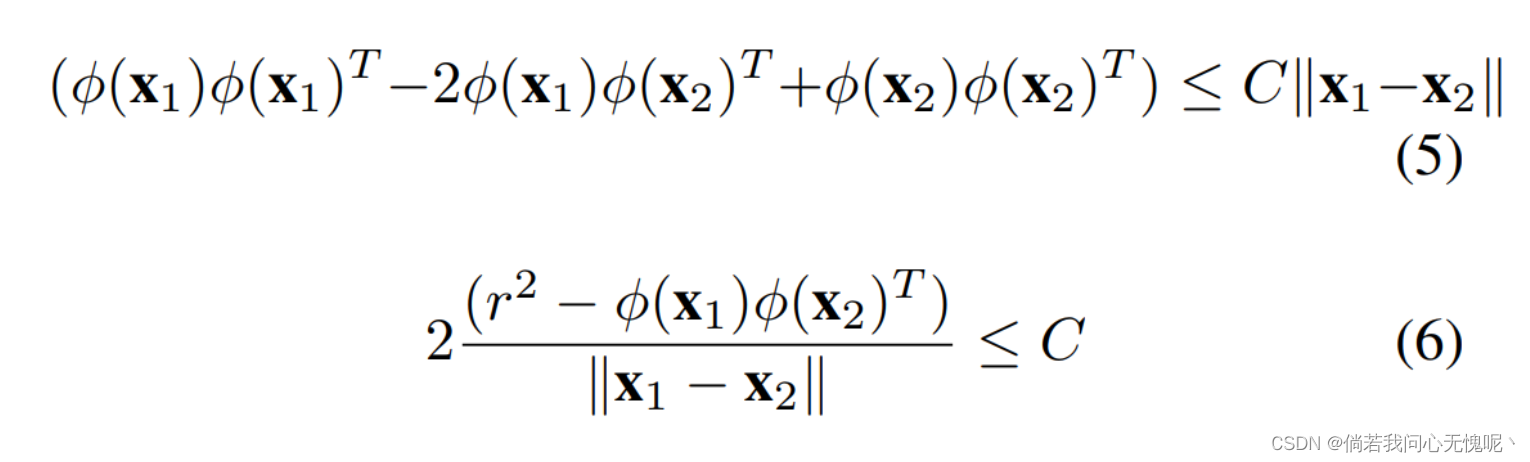
有了公式6,让我们考虑
X
\bf{X}
X的两种情况。
Case 1: X的行是正交的
在这种情况下,X的行是相互垂直的,
X
T
X
\bf{X}^T \bf{X}
XTX的特征值
{
λ
i
}
i
=
1
N
\{\lambda_i\}_{i=1}^{N}
{λi}i=1N是同分布的。同样,人们可以看到 (这里是根据公式6计算得到的,下面项和上面右边项都会无限趋近于0)
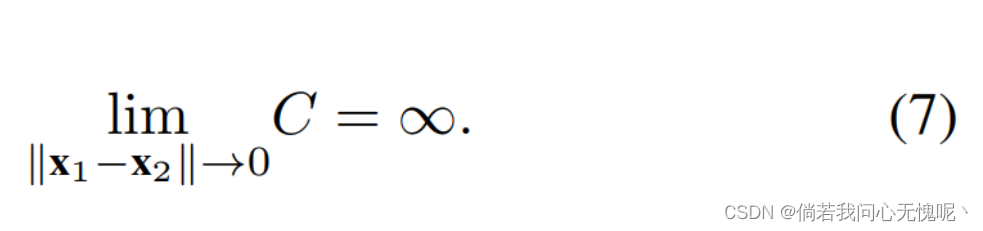
换句话说,拥有(近似)均匀分布的特征值违反了网络的Lipschitz光滑性。
Case 2: X \bf{X} X的行是线性无关的,行与行之间的夹角上界为 0 < α < π / 2 0 < \alpha <\pi/2 0<α<π/2。
在这种情况下,
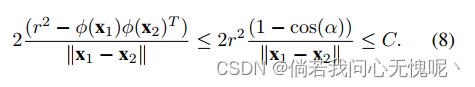
注意,如果α非常小,它会导致非常小的Lipschitz常数,这可能会难以编码具有高频成分的函数。 此外,在这种情况下,特征值的总能量主要集中在前几个分量上。当
α
\alpha
α变大时,Lipschitz常数变大,允许在特征值之间均匀分散能量的自由。但是,请注意严格地说,拥有一个更大的Lipschitz常数不能自动确保在特征值之间有一个高能量分布,因为等式6的右边只是一个上界。然而,我们观察到,在实践中,
α
\alpha
α和
C
C
C之间的单调关系几乎总是成立的。这种分析提供了一种重要的直觉:由坐标MLP的隐藏层诱导的函数的Lipschitz常数
C
C
C隐式地与
X
T
X
\bf{X}^{T} \bf{X}
XTX的特征值分布有关。
Remark 1: 考虑一组坐标 { x i } i = 1 N \{x_i\}_{i=1}^N {xi}i=1N和一个MLP的一个隐藏层诱导的函数 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)。令 { λ } i = 1 N \{\lambda\}_{i=1}^N {λ}i=1N为 X T X \bf{X}^T \bf{X} XTX的特征值,这里 X = [ ϕ ( x 1 ) T ϕ ( x 2 ) T ⋯ ϕ ( x N ) T ] \bf{X} = [\phi(x_1)^T\phi(x_2)^T\cdots\phi(x_N)^T] X=[ϕ(x1)Tϕ(x2)T⋯ϕ(xN)T]。然后, S ( X ) = ∑ i = 1 N λ i m a x i ( λ i ) \mathcal{S}(X)=\sum_{i=1}^{N} \frac{\lambda_i}{\mathop{max}\limits_{i}(\lambda_i)} S(X)=∑i=1Nimax(λi)λi是 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)的Lipschitz平滑度的替代测度或近似度量。更精确的说,如果 S ( X ) \mathcal{S}(\bf{X}) S(X)是很大的,则 C C C也会趋向变大,反之亦然。
度量 S ( ⋅ ) \mathcal{S}(\cdot) S(⋅)也被称为矩阵的稳定秩。这是一个有用的结果,因为计算一个MLP的精确Lipschitz常数是一个NP-hard问题[35]。虽然可以有效地获得Lipschitz常数的上界,但这需要计算函数的梯度。相反,我们可以在运行时通过观察 S \mathcal{S} S对特定层的Lipschitz平滑的表现有一个粗略的了解。
为了获得最佳的编码性能,应该选择 C C C应在与编码信号的一阶梯度的幅度相匹配的合适范围内。更确切地说,这两个因素相互之间保持着单调的关系。然而,自然信号的导数(或频率)在其定义域内并不保持一致。例如,图像可能只包含像素子集内的高变化。因此,MLP的隐藏层必须具有在不同区间上具有不同Lipschitz平滑度的函数建模的灵活性。换句话说,我们感兴趣的是由隐藏层引起的局部Lipschitz平滑。在第3.4节中,我们将看到MLP可以通过适当选择激活函数来获得这种灵活性。在第3.4节中,我们研究了隐层的局部Lipschitz平滑性,并将其与激活函数的性质联系起来。
3.4 Local Lipschitz smoothness
有空再写吧,这么一大段公式不想看了
我们现在有兴趣研究隐藏层的局部李普希茨平滑性。我们正式定义局部Lipschitz光滑性如下:
Definition 1: 如果对于所有的 x ∈ B δ m x \in \mathbb{B}^m_\delta x∈Bδm存在一个常数满足 ∣ ∣ f ( x ) − f ( x 0 ) ∣ ∣ ≤ C ∣ ∣ x − x 0 ∣ ∣ ||f(x)-f(x_0)|| \leq C||x-x_0|| ∣∣f(x)−f(x0)∣∣≤C∣∣x−x0∣∣,其中 x 0 x_0 x0是 B δ m \mathbb{B}^m_{\delta} Bδm的中心,则一个函数 f : R m → R n f: \R^{m} \rightarrow \R^{n} f:Rm→Rn在 x 0 ∈ R m x_0 \in \R^{m} x0∈Rm周围是局部LIpschitz的。那么,满足上述不等式的最小的 C C C值称为 f f f在 x 0 x_0 x0附近的Lipschitz常数,记作 L x 0 , δ ( f ) L_{x_0,\delta}(f) Lx0,δ(f)。
隐藏层是仿射函数和非线性函数的组合。因此,隐层的复合局部Lipschitz常数有上界
L
x
0
,
δ
(
ψ
∘
g
)
≤
L
x
0
,
δ
(
ψ
)
L
x
0
,
δ
(
g
)
L_{x_0,\delta}(\psi \circ g) \leq L_{x_0,\delta}(\psi) L_{x_0,\delta}(g)
Lx0,δ(ψ∘g)≤Lx0,δ(ψ)Lx0,δ(g)。因此,当δ趋于零时,我们研究这些性质。仿射变换是可微的,因此在构造上是局部Lipschitz的。令
x
∈
B
δ
m
\bf{x} \in \mathbb{B}^{m}_{\delta}
x∈Bδm,中心为
x
0
\bf{x_0}
x0。当
lim
δ
→
0
\lim\limits_{\delta\to 0}
δ→0lim
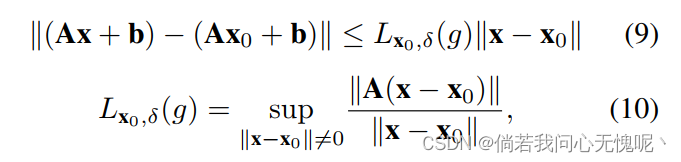
这是权矩阵A的算子范数。我们认为,控制MLP的仿射投影并不是一个理想的方法,因为它可能导致完全连接层的搜索空间急剧减少,从而导致较差的函数逼近。相反,我们避免控制仿射部分
L
x
0
,
δ
(
g
)
L_{x_0,\delta}(g)
Lx0,δ(g)而专注于非线性函数部分
L
x
0
,
δ
(
ψ
)
L_{x_0,\delta}(\psi)
Lx0,δ(ψ)。
因为
ψ
\psi
ψ是一个连续可微函数,应用泰勒展开式
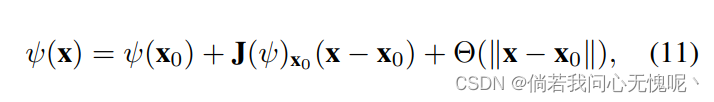 当
x
→
x
0
\bf{x} \to \bf{x_0}
x→x0时,其中
Θ
(
∣
∣
x
−
x
0
∣
∣
)
\Theta(||\bf{x}-\bf{x}_0||)
Θ(∣∣x−x0∣∣)是一个快速衰减函数。重新排列公式11,我们得到
当
x
→
x
0
\bf{x} \to \bf{x_0}
x→x0时,其中
Θ
(
∣
∣
x
−
x
0
∣
∣
)
\Theta(||\bf{x}-\bf{x}_0||)
Θ(∣∣x−x0∣∣)是一个快速衰减函数。重新排列公式11,我们得到
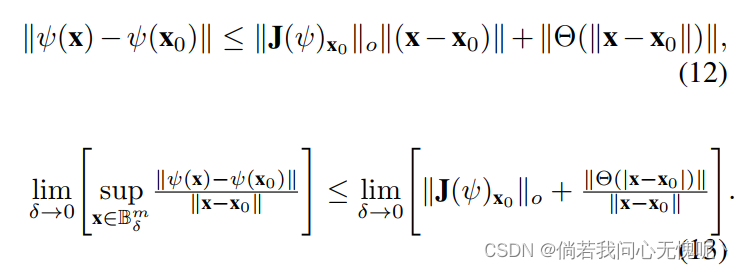
公式13的左边是
ψ
(
⋅
)
\psi (\cdot)
ψ(⋅)在
x
0
\bf{x}_0
x0点处的Lipschitz常数。另外,
lim
δ
→
0
∣
∣
Θ
(
∣
x
−
x
0
∣
)
∣
∣
∣
∣
x
−
x
0
∣
∣
\lim\limits_{\delta\to0}\frac{||\Theta(|x-x_0|)||}{||x-x_0||}
δ→0lim∣∣x−x0∣∣∣∣Θ(∣x−x0∣)∣∣根据定义也为0。
ψ
(
⋅
)
\psi (\cdot)
ψ(⋅)在
x
0
\bf{x_0}
x0处的点向Lipschitz常数记为
L
x
0
(
ψ
)
L_{\bf{x}_0} (\psi)
Lx0(ψ),我们得到
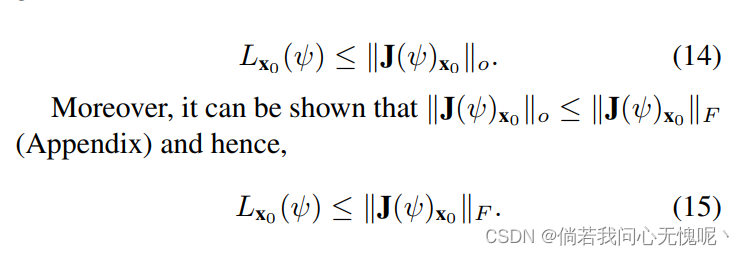
现在,我们提出以下重要的注释,为坐标MLP选择合适的激活函数提供了指南。
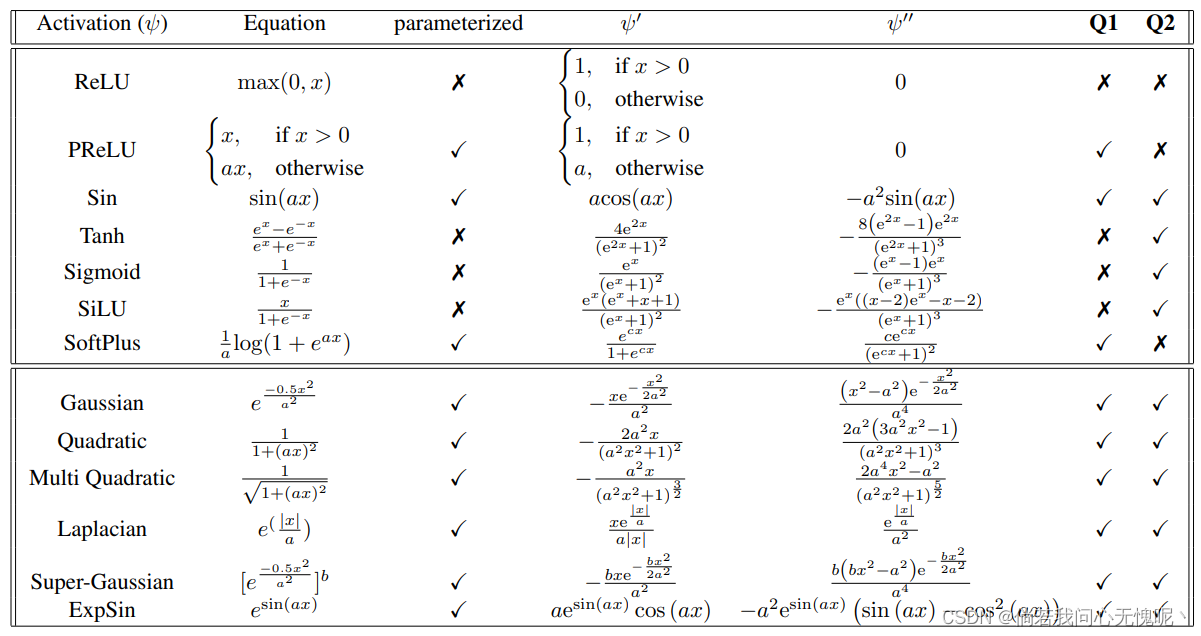
Remark 2: 理想情况下,激活函数应该具有两个重要特性: (Q1) 局部的Lipschitz常数在整个域上应该有足够的下界和上界。等价地, ∣ ∣ J ( ψ ) x ∣ ∣ ||J(\psi)_x|| ∣∣J(ψ)x∣∣的范围应该与被编码信号的一阶导数的大小适当匹配。(Q2)局部Lipschitz常数应该在激活函数的范围内平滑变化,因此由隐藏层诱导的复合函数可以将点集投影到适当的子空间,并在边界之间实现任意的局部平滑。等价地, ψ ( ⋅ ) \psi (\cdot) ψ(⋅)的二阶偏导数应该是非零的,并且在定义域内一定区间内连续。
如公式15所示,如果一组点非常紧密地聚集在一起,这些点的Lipschitz常数可以通过激活函数在相应点附近的雅可比范数得到。这给了我们一个重要的工具,可以得到一个网络可以达到的最大局部Lipscitz常数。例如,让我们选择一个逐点(点级)激活函数。那么
J
(
f
)
x
J(f)_{\bf{x}}
J(f)x是一个对角矩阵,我们可以用以下方法来约束
L
x
L_{\bf{x}}
Lx:
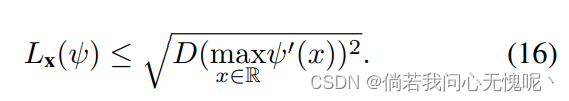
对于给定的层宽度
D
D
D,
x
∈
R
D
x \in \R^{D}
x∈RD。对于给定的网络,
D
D
D是一个常数,

为我们提供了测试Q1的代理指标。
直观地说,一个MLP的一层网络的性能上界可以通过(通过仿射变换)将点投影到激活函数存在最高一阶导数的小邻域来得到。Q2的检验很简单:如果激活函数的二阶导数在相当长的一段时间内不可忽略(等价地,如果局部Lipschits常数在激活域内平滑变化),则Q2是满足的。表格1比较了现有的和我们提出的几种新的激活函数。
4. Experiments
在本节中,我们将以实验验证我们通过框架得到的观点。
4.1 Comparison of activation functions
我们比较了配以不同激活函数的坐标mlp编码信号的容量。图2说明了一个示例,其中图像被编码为MLP的权值。如图所示,新提出的高斯、拉普拉斯、ExpSin和二次激活函数能够以更清晰的梯度(高Lipschitz常数)以显著更好的保真度编码图像,与现有的激活相比,例如ReLU, Tanh, SoftPlus和SiLU。同时,需要注意的是,对于所提出的激活函数,隐藏表示的稳定秩(本征值之间的能量分布)要比其他激活函数高。这与我们备注1的理论预测相吻合。

图片描述:正如Remark 2所预测的那样,所提出的激活更适合于高保真编码信号。如备注1所述,所提议的激活的稳定等级更高,表明更大的局部李普希茨常数允许更尖锐的梯度
4.2 Novel view synthesis
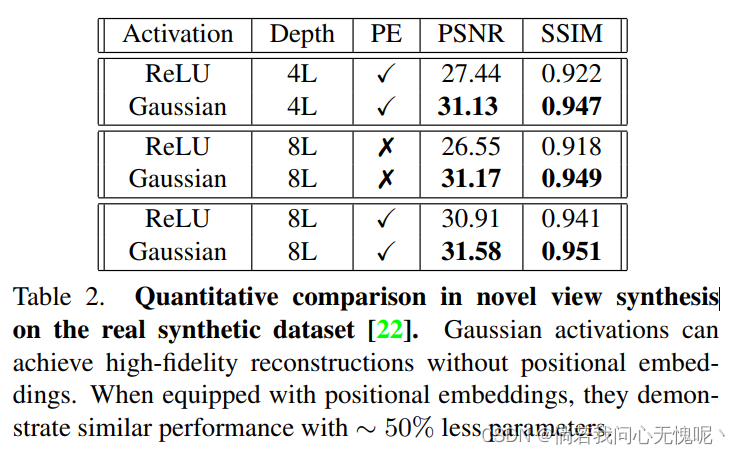
没有位置嵌入: 我们利用[22]发布的真实合成数据集来测试高斯激活编码高维信号的能力。图像3对比了ReLU和没有位置嵌入的高斯激活函数的性能。当位置嵌入不被使用时,ReLU-MLPs在捕捉高频细节方面表现不佳。相反,在没有位置嵌入的情况下,高斯激活可以获得更高保真度的信息。我们相信这是一个有趣的结果,它打开了无位置嵌入架构的可能性。

高斯激活可以完全忽略位置嵌入,同时产生明显更好的保真度结果。相反,当不使用位置嵌入时,ReLU-MLPs的性能会严重下降。本实验采用8层MLPs。
含有位置嵌入: 虽然适当选择的激活函数可以省略位置嵌入,两者的结合仍然可以使浅层网络可以学习高频函数。图4描述了一个具有4层MLP的示例。显然,当网络较浅时,ReLU MLPs表现出质量下降,而高斯激活MLPs的性能与较深的ReLU MLPs相当。这提倡在使用适当设计的激活函数时,从业人员可以享受更便宜的架构。表2描述了包括上述比较的定量结果。
4.3 Convergence
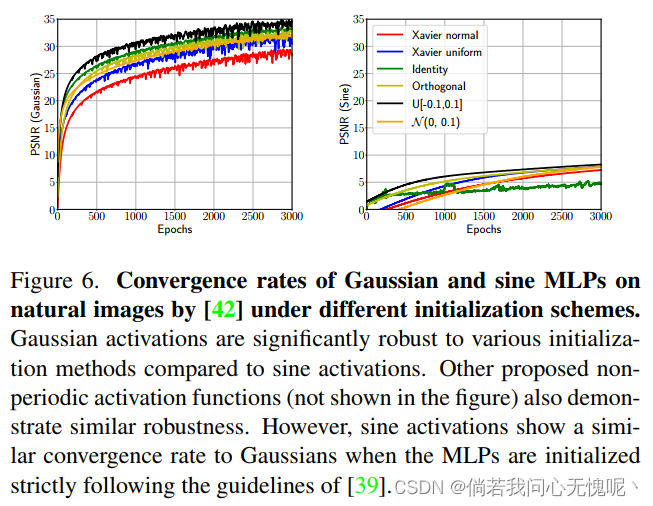
Sitzmann等人综合论证了正弦激活使MLPs能够精细地编码信号。但是,正弦激活的一个缺点是MLP对初始化非常敏感。相比之下,提出的非周期激活函数不存在这样的问题。图5说明了一个定性的例子。当MLP的初始化方法不严格遵循中Sitzmann等人提出的方法时,正弦激活的MLPs即使在3000个时代之后也不收敛。相比之下,高斯激活表现出更快的收敛速度。图6显示了收敛性的定量比较。 我们在[42]发布的自然图像数据集上训练网络,每次迭代后的平均PSNR值如图6所示。很明显,高斯激活对不同的MLP初始化方案具有较高的鲁棒性。

4.4 Local Lipschitz smoothness
如式15所示,局部Lipschitz光滑性依赖于对应点的雅可比范数。在第3.4节中,我们证明了一个很好的Lipschitz常数的代理测度是激活函数的一阶导数的范围。我们进一步肯定了为了获得更好的性能,应该适当地选择Lipschitz常数,即过高或过低的Lipschitz常数都可能使网络无法正确地学习信号。图7说明了证实这一说法的示例。
σ
\sigma
σ增大时,高斯活化的
R
a
n
g
e
∣
ψ
′
∣
Range|\psi^{'}|
Range∣ψ′∣减小,使Lipschitz常数减小(见公式17)。一个较低的Lipschitz常数会导致模糊的边缘,其不允许局部发生剧烈变化。另一方面,一个非常大的Lipschitz常数会有不必要的波动。因此,选择一个合适的参数范围对获得更好的性能至关重要。图8显示了适当选择参数编码高斯激活信号后的局部Lipschitz常数分布。


5. Conclusion
我们试图扩展当前对激活函数的理解,以允许坐标MLP对函数进行高保真程度编码。 我们表明,之前提出的正弦波激活[40]只是一个使坐标MLP编码高频信号的激活函数广泛类中的一个例子。此外,我们开发了通用指南来设计和调优坐标MLP的激活函数,并提出了几个非周期激活函数作为示例。最后,从提出的列表中选择高斯激活,我们展示了各种信号编码任务的引人注目的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









