







numpy库与python的基础语法有细微的区别,但大致上是一致的
NumPy(Numerical Python)是 Python 中一个基础且强大的科学计算库,为 Python 提供了高效的多维数组对象以及处理这些数组的工具。
numpy数组与python列表区别:
NumPy 数组是同质数据类型(homogeneous),即数组中的所有元素必须是相同的数据类型。数据类型在创建数组时指定,并且数组中的所有元素都必须是该类型
Python 列表是异质数据类型(heterogeneous),即列表中的元素可以是不同的数据类型。列表可以包含整数、浮点数、字符串、对象等各种类型的数据。
一.ndarray对象:
1.创建数组的方式:
(1)array创建数组
numpy.array(object, dtype = None, copy = True, order = None,ndmin = 0)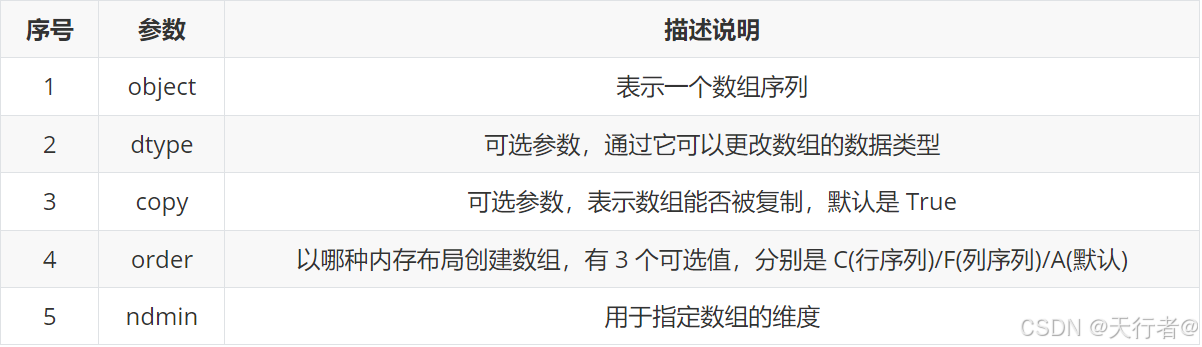
解释:
object:该参数可以是列表,元组,字典,集合,字符串,range()函数等可迭代对象
import numpy as np # 导入numpy库
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) # 列表
print(arr)
print(type(arr))
arr01 = np.array((1, 2, 3, 4, 5, 6, 7, 8)) # 元组
print(arr01)
print(type(arr01))
arr02 = np.array(range(10)) # range()函数
print(arr02)
print(type(arr02))
关于集合,字典作为object可迭代对象的参数,其打印结果有点不知其原因,
正在查找资料...
set01 = set(range(9))
arr03 = np.array(set01) # 集合
print(arr03)
print(type(arr03))
arr04 = np.array('qwertyuiop') # 字符串
print(arr04)
print(type(arr04))
arr05 = np.array({'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}) # 字典
print(arr05)
print(type(arr05))
dtype:可以改变数组的数据类型,默认为数据本身的类型,既可以在初始化时设置数据类型,也可以查看数据类型
import numpy as np
arr = np.array([1, 2, 3, 4, 5], dtype=str) # 原数据类型为整数型,转换为字符类型
print(arr) # ['1' '2' '3' '4' '5']
print(arr.dtype) # 查看数据类型 <U1,在NumPy中,U表示Unicode字符串,数字1表示字符串的最大长度这里每个字符串的最大长度为1d
print(type(arr))
copy: 可选参数,表示数组能否被复制,默认是 True。
当 copy=True 时,会创建输入数据的一个副本,对新数组的修改不会影响原始数据,反之亦然
当 copy=False 时,如果输入的数据本身就是一个 numpy.ndarray 对象,那么不会创建新的副本,而是返回对原数组的一个引用(视图)。此时,对新数组的修改会影响原始数组,反之亦然。
import numpy as np
original = np.array([1, 2, 3])
new_array = np.array(original, copy=True)
# 修改新数组
new_array[0] = 100
print(original) # 输出: [1 2 3]
print(new_array) # 输出: [100 2 3]import numpy as np
original = np.array([1, 2, 3])
new_array = np.array(original, copy=False)
# 修改新数组
new_array[0] = 100
print(original) # 输出: [100 2 3]
print(new_array) # 输出: [100 2 3]补充:切片和copy()方法
copy() 方法:numpy.ndarray 对象有一个 copy() 方法,调用该方法会创建数组的一个完整副本。
import numpy as np
original = np.array([1, 2, 3])
new_array = original.copy()
# 修改新数组
new_array[0] = 100
print(original) # 输出: [1 2 3]
print(new_array) # 输出: [100 2 3]切片:返回的是数组的视图,不会复制数据,只是提供了一种不同的方式来访问原数组的数据。
import numpy as np
original = np.array([1, 2, 3, 4, 5])
view = original[1:3]
# 修改视图
view[0] = 100
print(original) # 输出: [1 100 3 4 5]
print(view) # 输出: [100 3]注意:
冒号 : 的作用
-
表示范围: 冒号用于表示一个范围。例如,array[1:3] 表示从索引 1 到索引 3(不包括 3)的元素。
-
表示所有元素: 单独使用冒号表示所有元素。例如,array[:, 1] 表示所有行的第 1 列。
-
步长: 双冒号后面可以跟一个步长值,表示每隔多少个元素取一个。例如,array[::2] 表示每隔一个元素取一个。
注:冒号对于一维数组按索引号截取,二维数组按行和列截取。
省略号 ... 的作用
-
表示所有维度: 省略号用于表示数组的所有维度。例如,array[..., 1] 表示取所有行的第 1 列。
-
简化多维切片: 在多维数组中,省略号可以简化切片操作,避免显式地写出所有维度的索引。例如,一个4维的随机数组
arr,形状为(2, 3, 4, 5)。在切片操作arr[0, ...]中0表示选取第1个维度的第0个元素,...表示其余维度全选。这样就避免了显式写出arr[0, :, :, :]。
order: 以哪种内存布局创建数组,有三个常用的取值:'C'、'F' 和 'A' ,一个不太常用的 'K'
1. order='C'(C 风格顺序,C-style order)
-
含义:采用行优先(row-major)的存储方式。在多维数组中,先存储第一行的所有元素,接着是第二行的元素,依此类推。对于一个二维数组
arr,其元素在内存中是按行依次排列的,即arr[0, 0]、arr[0, 1]、arr[0, 2]...arr[1, 0]、arr[1, 1]... 。 -
适用场景:C 和 Python 语言通常使用行优先的存储方式,因此当与这些语言编写的代码交互或者进行按行访问的操作时,使用
order&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1632
1632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









