







 本文介绍了谷歌在ICML 2021发表的论文,提出了名为ALIGN的模型,该模型使用18亿图像-文本对进行预训练,无需昂贵的数据过滤,能在多个视觉和视觉语言任务中达到SOTA性能,包括图像检索、零样本视觉分类等。
本文介绍了谷歌在ICML 2021发表的论文,提出了名为ALIGN的模型,该模型使用18亿图像-文本对进行预训练,无需昂贵的数据过滤,能在多个视觉和视觉语言任务中达到SOTA性能,包括图像检索、零样本视觉分类等。
关注公众号,发现CV技术之美
本文分享ICML 2021 收录论文『Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision』。由谷歌学者提出《ALIGN》能够进行跨模态检索,性能优于 SOTA。
详细信息如下:

论文链接:https://arxiv.org/abs/2102.05918
项目链接:尚未开源
导言:

学习良好的视觉和视觉语言表征对于解决计算机视觉问题(图像检索、图像分类、视频理解)是至关重要的,目前,预训练的特征在许多NLP任务中已经展现了非常大的潜力。虽然NLP中的表示学习已经可以用没有人工注释的原始文本训练,但视觉和视觉语言表示仍然严重依赖于昂贵或需要专家知识的训练数据集。
对于视觉任务,特征表示的学习主要依赖具有显式的class标签的数据集,如ImageNet或OpenImages。对于视觉语言任务,一些使用广泛的数据集像Conceptual Captions、MS COCO以及CLIP都涉及到了数据收集和清洗的过程。这类数据预处理的工作严重阻碍了获得更大规模的数据集。在本文中,作者利用了超过10亿的图像文本对的噪声数据集,没有进行数据过滤或后处理步骤 。
基于对比学习损失,使用一个简单的双编码器结构来学习对齐图像和文本对的视觉和语言表示 。作者证明了,语料库规模的巨大提升可以弥补数据内部存在的噪声,因此即使使用简单的学习方式,模型也能达到SOTA的特征表示。当本文模型的视觉表示转移到ImageNet和VTAB等分类任务时,也能取得很强的性能。对齐的视觉和语言表示支持zero-shot的图像分类,并在Flickr30K和MSCOCO图像-文本检索基准数据集上达到了SOTA的结果。
01
Motivation
在现有工作中,视觉和视觉语言表示学习大多是分别使用不同的训练数据源进行研究的。在视觉领域,对大规模监督数据(如ImageNet、OpenImages和JFT-300M)进行预训练对提高下游任务的性能是至关重要的。获得这种预训练的数据集需要在数据收集、采样和人工标注方面进行大量的工作,数据获取成本非常大,因此难以扩展。
预训练也是视觉语言建模的方法。然而,视觉语言的预训练数据集,如Conceptual Captions、Visual Genome Dense Captions和 ImageBERT,需要在人类标注、语义解析、清理和平衡方面进行更重的工作。因此,这些数据集的规模仅在10M个样本左右。这至少比视觉领域的数据集小一个数量级,而且比预训练的NLP数据集也小得多。
在这项工作中,作者利用了超过10亿个有噪声的图像文本对的数据集来扩展视觉和视觉语言表示学习。作者采用了Conceptual Captions的方式来获取一个大的噪声数据集。与其不同的是,作者没有用复杂的数据滤波和后处理步骤来清理数据集,而是只应用简单的基于数据频率的过滤。虽然得到的数据集有噪声,但比Conceptual Captions数据集大两个数量级。作者发现,在这样的大规模噪声数据集上预训练的视觉和视觉语言表示在广泛的任务上取得了非常强的性能。
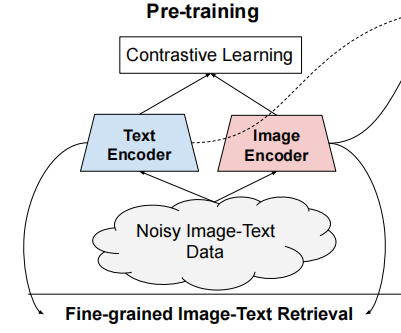
作者基于在一个共享的embedding空间中对齐视觉和语言表示的训练目标,使用一个简单的双编码器体系结构来训练模型。作者将这个模型命名为ALIGN(A L arge-scale I maG e and N oisy-text embedding),图像和文本编码器是通过对比损失函数学习的,将匹配的图像文本对的embedding推在一起,同时将不匹配的图像文本对的embedding分开。这也是自监督和监督表示学习的最有效的损失函数之一。
考虑到ALIGN用文本作为图像的细粒度标签,因此图像对文本的对比损失类似于传统的基于标签的分类目标;关键的区别在于这里的label是由文本编码器生成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3358
3358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









