






不知道大家有没有这样的体会,在读论文的时候经常会发现一些非常精妙的idea,作者在各个任务上都用这个结构达到非常好的performance。(ᗒᗨᗕ)看完论文之后,不禁为作者提出的这个idea拍手叫好(^ω^),但是打开作者的github一看,人都看傻了(也可能只是我是这样的 ╥﹏╥)。
因为看到这个简单的结构被嵌入到了各个任务的代码框架中,导致代码比较冗余,对于像我这样的小白(╯_╰),真的很难找到论文的核心代码。(明明我根本不care这些具体任务,为什么让我看这么多不相关的代码,天哪!!!),导致在论文和网络的核心思想理解上会有一定困难。
因此,我把最近看的Attention、MLP、Conv和Re-parameter论文的核心代码进行了整理和复现,方便各位读者理解。
项目会持续更新最新的论文工作,欢迎大家follow和star该工作,若项目在复现和整理过程中有任何问题,欢迎大家在issue中提出。(里面都是一些论文的核心代码 ,因为是自己复现的,所以也不能保证百分百正确,不过大家可以一起交流学习哈,有问题欢迎指出,我会及时回复哒,^ω^)
项目地址:https://github.com/xmu-xiaoma666/External-Attention-pytorch
在我爱计算机视觉公众号后台回复 “深度学习论文” 即可收到本文盘点的所有论文。
Contents
Attention Series
- 1. External Attention Usage
- 2. Self Attention Usage
- 3. Simplified Self Attention Usage
- 4. Squeeze-and-Excitation Attention Usage
- 5. SK Attention Usage
- 6. CBAM Attention Usage
- 7. BAM Attention Usage
- 8. ECA Attention Usage
- 9. DANet Attention Usage
- 10. Pyramid Split Attention (PSA) Usage
- 11. Efficient Multi-Head Self-Attention(EMSA) Usage
- 12. Shuffle Attention Usage
- 13. MUSE Attention Usage
- 14. SGE Attention Usage
- 15. A2 Attention Usage
- 16. AFT Attention Usage
- 17. Outlook Attention Usage
- 18. ViP Attention Usage
- 19. CoAtNet Attention Usage
- 20. HaloNet Attention Usage
- 21. Polarized Self-Attention Usage
- 22. CoTAttention Usage
MLP Series
- 1. RepMLP Usage
- 2. MLP-Mixer Usage
- 3. ResMLP Usage
- 4. gMLP Usage
Re-Parameter(ReP) Series
- 1. RepVGG Usage
- 2. ACNet Usage
- 3. Diverse Branch Block(DDB) Usage
Convolution Series
- 1. Depthwise Separable Convolution Usage
- 2. MBConv Usage
- 3. Involution Usage
▊ Attention Series
Pytorch implementation of "Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"
Pytorch implementation of "Attention Is All You Need---NIPS2017"
Pytorch implementation of "Squeeze-and-Excitation Networks---CVPR2018"
Pytorch implementation of "Selective Kernel Networks---CVPR2019"
Pytorch implementation of "CBAM: Convolutional Block Attention Module---ECCV2018"
Pytorch implementation of "BAM: Bottleneck Attention Module---BMCV2018"
Pytorch implementation of "ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"
Pytorch implementation of "Dual Attention Network for Scene Segmentation---CVPR2019"
Pytorch implementation of "EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"
Pytorch implementation of "ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"
Pytorch implementation of "SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"
Pytorch implementation of "MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"
Pytorch implementation of "Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"
Pytorch implementation of "A2-Nets: Double Attention Networks---NIPS2018"
Pytorch implementation of "An Attention Free Transformer---ICLR2021 (Apple New Work)"
Pytorch implementation of VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"
Pytorch implementation of Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23
Pytorch implementation of CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09
Pytorch implementation of Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral
Pytorch implementation of Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02
Pytorch implementation of Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26
1. External Attention Usage
1.1. Paper
"Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"
https://arxiv.org/abs/2105.02358
1.2. Overview
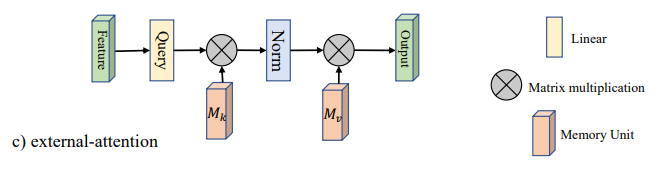
1.3. Code
from attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
2. Self Attention Usage
2.1. Paper
"Attention Is All You Need"
https://arxiv.org/pdf/1706.03762.pdf
2.2. Overview
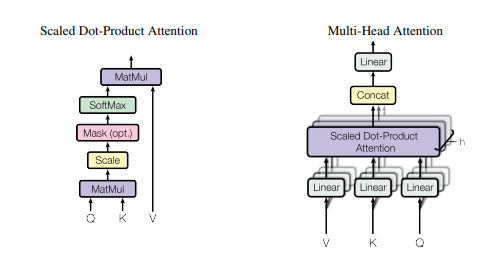
2.3. Code
from attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
3. Simplified Self Attention Usage
3.1. Paper
None
3.2. Overview
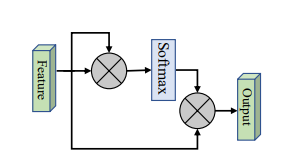
3.3. Code
from attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
4. Squeeze-and-Excitation Attention Usage
4.1. Paper
"Squeeze-and-Excitation Networks"
https://arxiv.org/abs/1709.01507
4.2. Overview
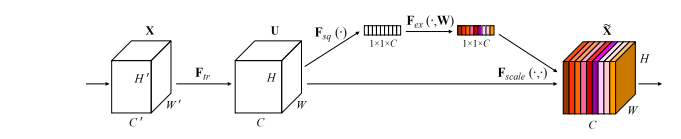
4.3. Code
from attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
5. SK Attention Usage
5.1. Paper
"Selective Kernel Networks"
https://arxiv.org/pdf/1903.06586.pdf
5.2. Overview
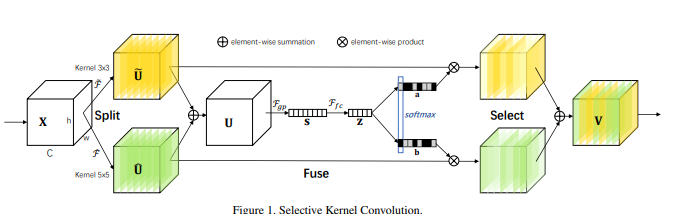
5.3. Code
from attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
6. CBAM Attention Usage
6.1. Paper
"CBAM: Convolutional Block Attention Module"
https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
6.2. Overview
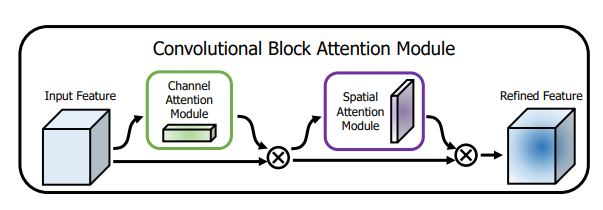
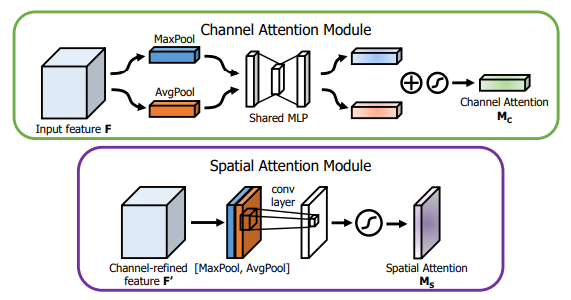
6.3. Code
from attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
7. BAM Attention Usage
7.1. Paper
"BAM: Bottleneck Attention Module"
https://arxiv.org/pdf/1807.06514.pdf
7.2. Overview
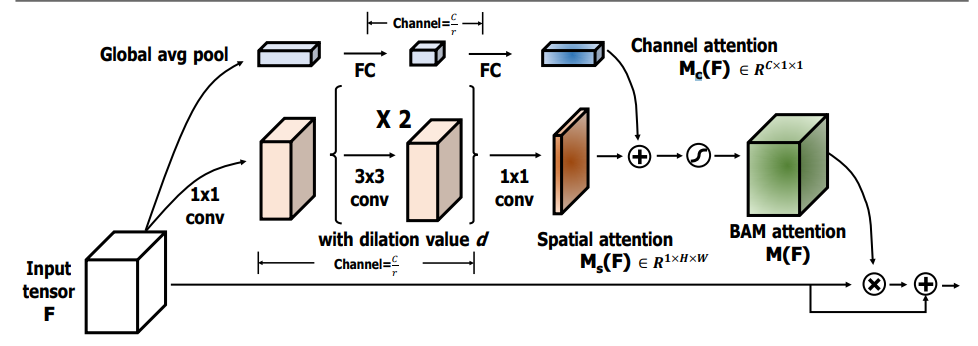
7.3. Code
from attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
8. ECA Attention Usage
8.1. Paper
"ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"
https://arxiv.org/pdf/1910.03151.pdf
8.2. Overview
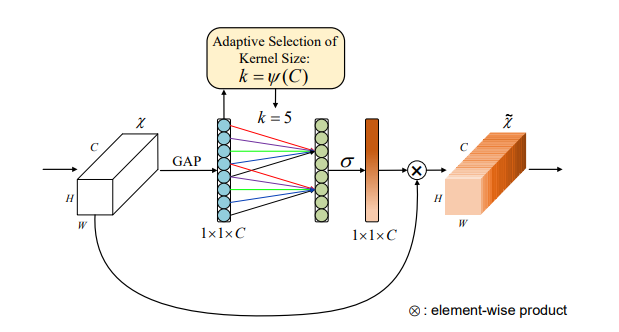
8.3. Code
from attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
9. DANet Attention Usage
9.1. Paper
"Dual Attention Network for Scene Segmentation"
https://arxiv.org/pdf/1809.02983.pdf
9.2. Overview
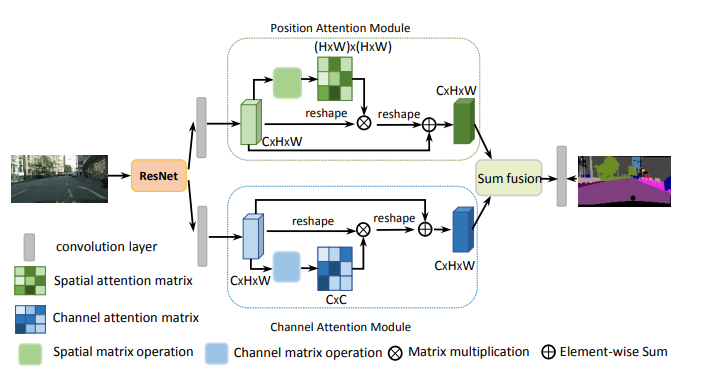
9.3. Code
from attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
10. Pyramid Split Attention Usage
10.1. Paper
"EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"
https://arxiv.org/pdf/2105.14447.pdf
10.2. Overview
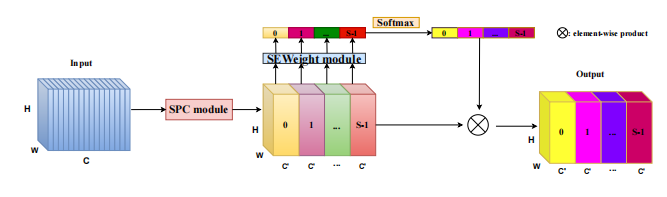
10.3. Code
from attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
11. Efficient Multi-Head Self-Attention Usage
11.1. Paper
"ResT: An Efficient Transformer for Visual Recognition"
https://arxiv.org/abs/2105.13677
11.2. Overview
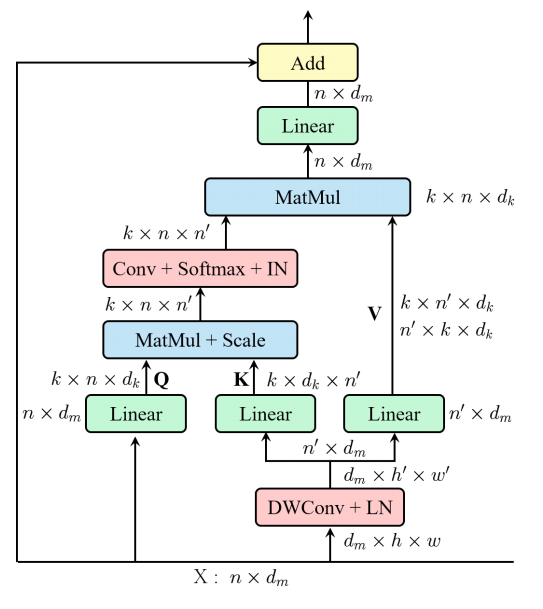
11.3. Code
from attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
12. Shuffle Attention Usage
12.1. Paper
"SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"
https://arxiv.org/pdf/2102.00240.pdf
12.2. Overview
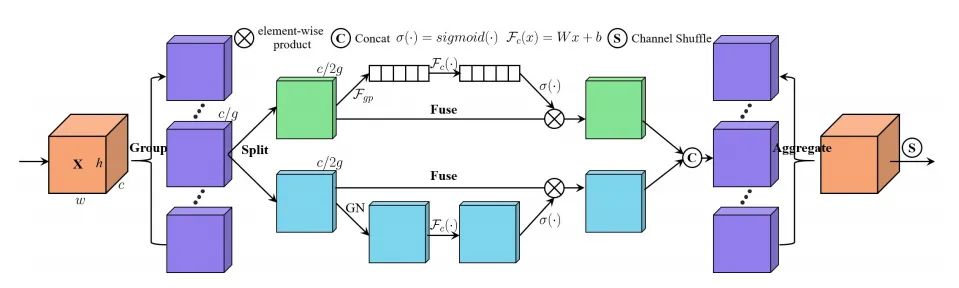
12.3. Code
from attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
13. MUSE Attention Usage
13.1. Paper
"MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"
https://arxiv.org/abs/1911.09483
13.2. Overview
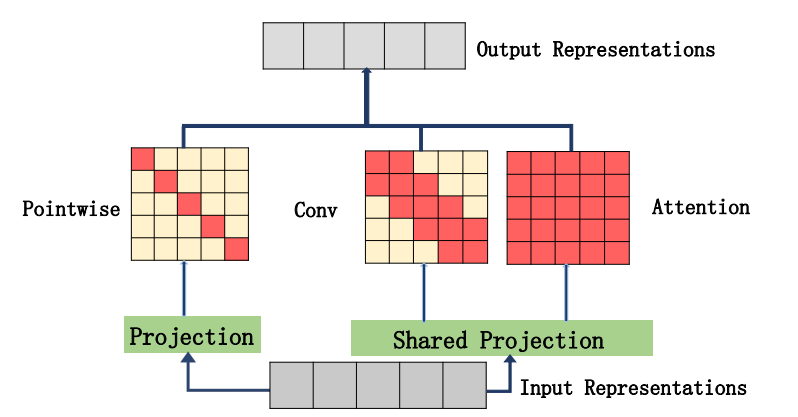
13.3. Code
from attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
14. SGE Attention Usage
14.1. Paper
Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
https://arxiv.org/pdf/1905.09646.pdf
14.2. Overview
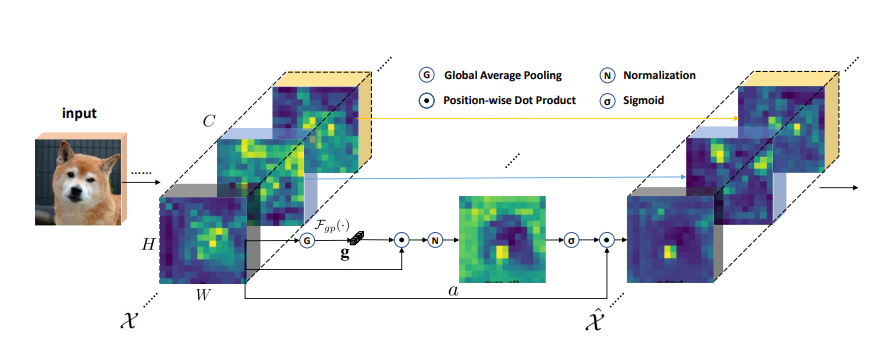
14.3. Code
from attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
15. A2 Attention Usage
15.1. Paper
A2-Nets: Double Attention Networks
https://arxiv.org/pdf/1810.11579.pdf
15.2. Overview
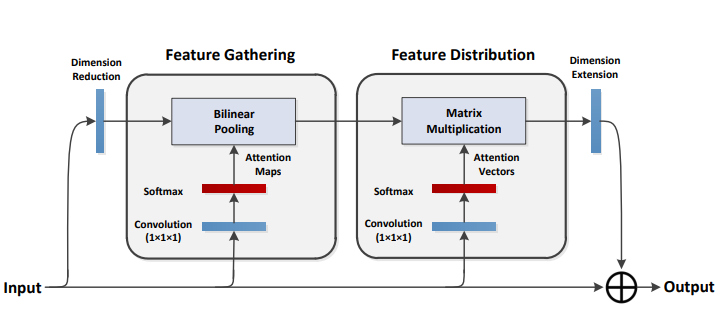
15.3. Code
from attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
16. AFT Attention Usage
16.1. Paper
An Attention Free Transformer
https://arxiv.org/pdf/2105.14103v1.pdf
16.2. Overview

16.3. Code
from attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
17. Outlook Attention Usage
17.1. Paper
VOLO: Vision Outlooker for Visual Recognition"
https://arxiv.org/abs/2106.13112
【论文解析】https://zhuanlan.zhihu.com/p/385561050
17.2. Overview
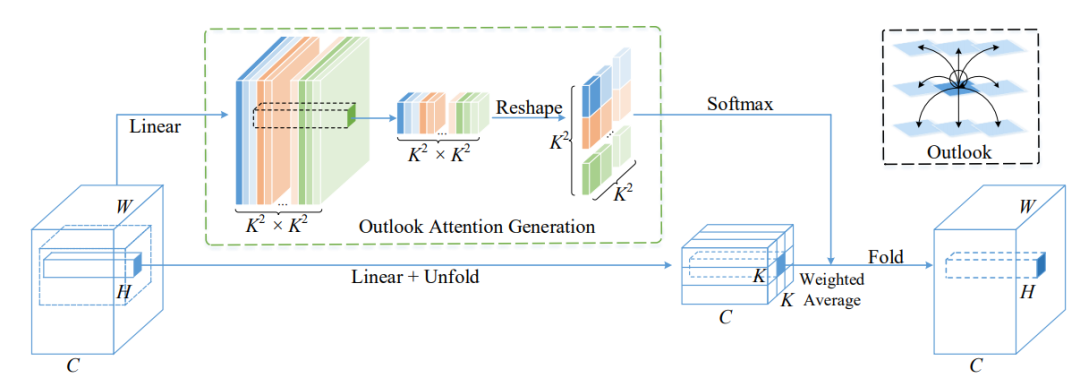
17.3. Code
from attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
18. ViP Attention Usage
18.1. Paper
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"
https://arxiv.org/abs/2106.12368
【论文解析】https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q
18.2. Overview
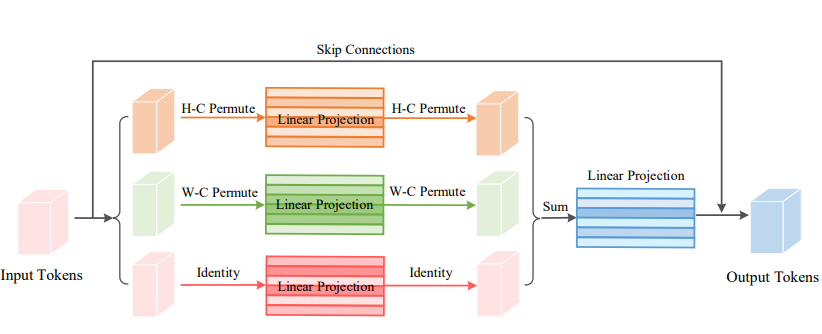
18.3. Code
from attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
19. CoAtNet Attention Usage
19.1. Paper
CoAtNet: Marrying Convolution and Attention for All Data Sizes"
https://arxiv.org/abs/2106.04803
【论文解析】https://zhuanlan.zhihu.com/p/385578588
19.2. Overview
None
19.3. Code
from attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
20. HaloNet Attention Usage
20.1. Paper
Scaling Local Self-Attention for Parameter Efficient Visual Backbones"
https://arxiv.org/pdf/2103.12731.pdf
【论文解析】https://zhuanlan.zhihu.com/p/388598744
20.2. Overview
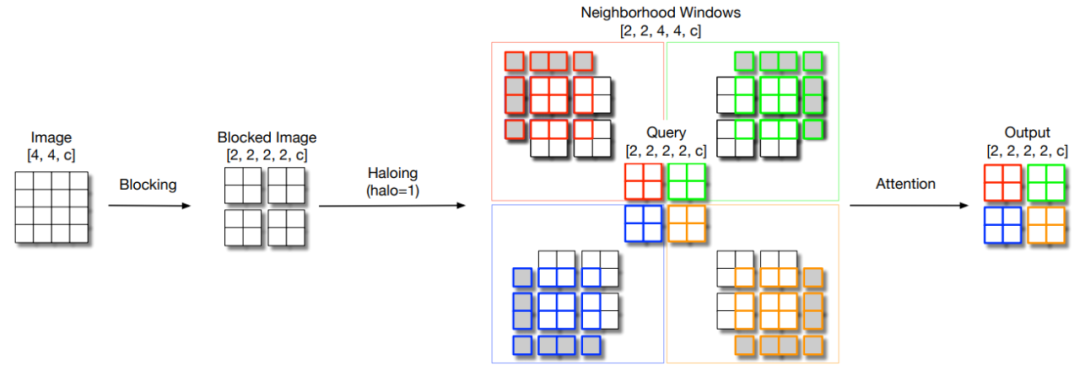
20.3. Code
from attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
21. Polarized Self-Attention Usage
21.1. Paper
Polarized Self-Attention: Towards High-quality Pixel-wise Regression"
https://arxiv.org/abs/2107.00782
【论文解析】https://zhuanlan.zhihu.com/p/389770482
21.2. Overview
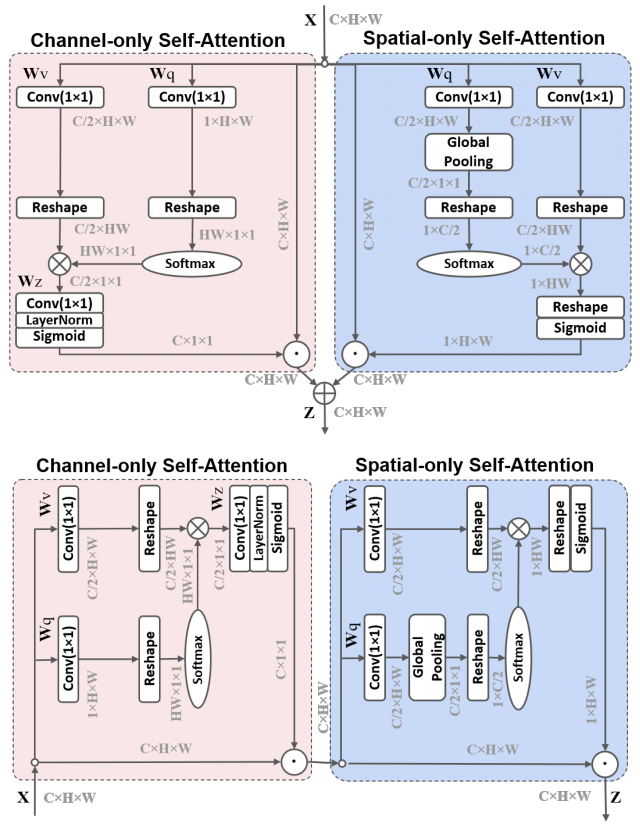
21.3. Code
from attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
22. CoTAttention Usage
22.1. Paper
Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26
https://arxiv.org/abs/2107.12292
22.2. Overview
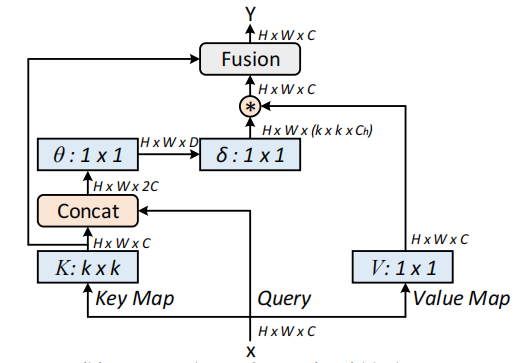
22.3. Code
from attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
▊ MLP Series
Pytorch implementation of "RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"
Pytorch implementation of "MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"
Pytorch implementation of "ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"
Pytorch implementation of "Pay Attention to MLPs---arXiv 2021.05.17"
1. RepMLP Usage
1.1. Paper
"RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"
https://arxiv.org/pdf/2105.01883v1.pdf
1.2. Overview
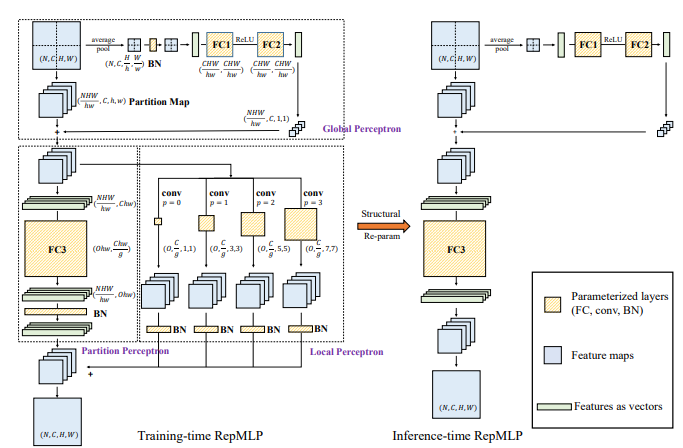
1.3. Code
from mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
2. MLP-Mixer Usage
2.1. Paper
"MLP-Mixer: An all-MLP Architecture for Vision"
https://arxiv.org/pdf/2105.01601.pdf
2.2. Overview
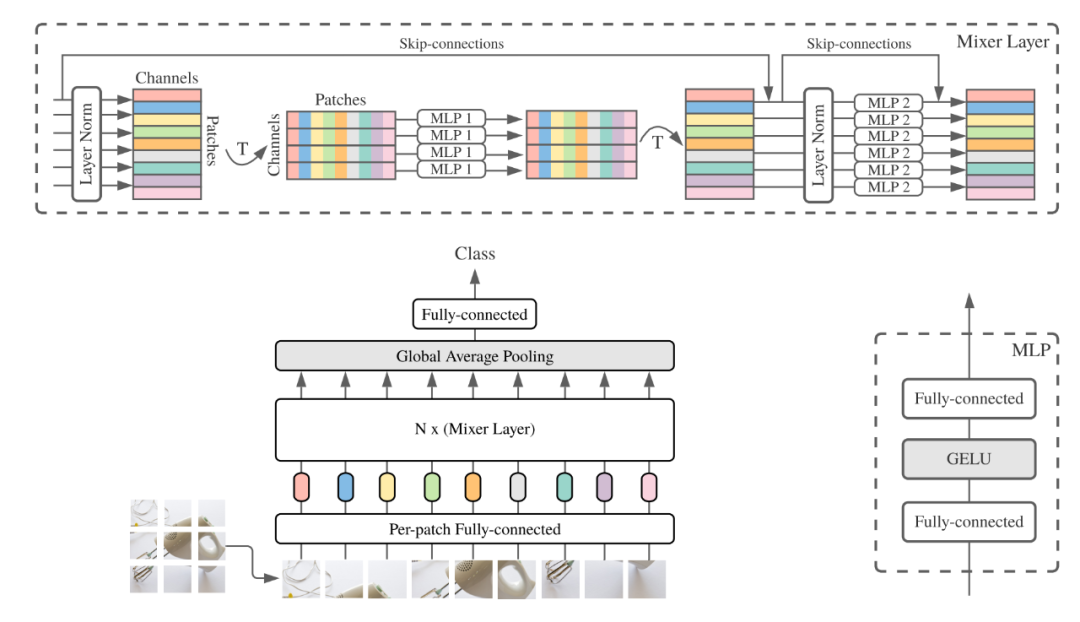
2.3. Code
from mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
3. ResMLP Usage
3.1. Paper
"ResMLP: Feedforward networks for image classification with data-efficient training"
https://arxiv.org/pdf/2105.03404.pdf
3.2. Overview

3.3. Code
from mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
4. gMLP Usage
4.1. Paper
"Pay Attention to MLPs"
https://arxiv.org/abs/2105.08050
4.2. Overview
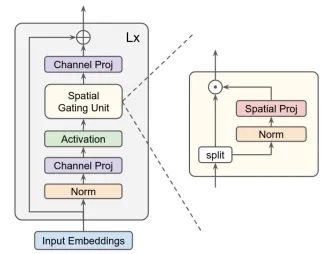
4.3. Code
from mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)▊ Re-Parameter Series
Pytorch implementation of "RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"
Pytorch implementation of "ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"
Pytorch implementation of "Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"
1. RepVGG Usage
1.1. Paper
"RepVGG: Making VGG-style ConvNets Great Again"
https://arxiv.org/abs/2101.03697
1.2. Overview
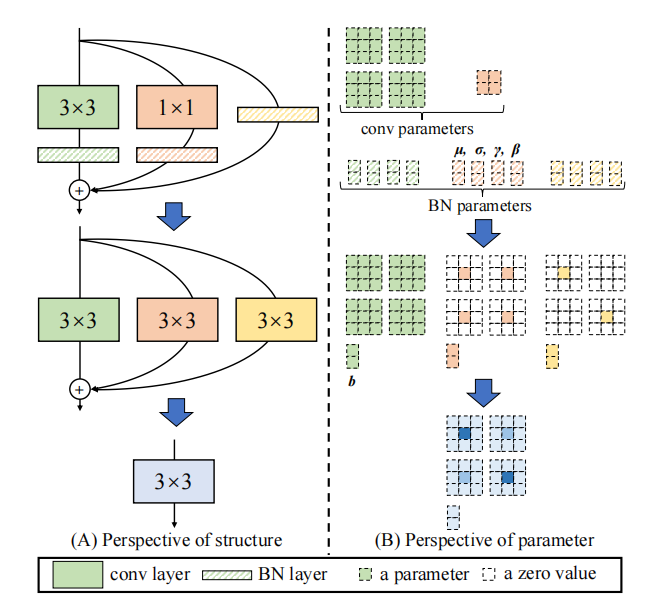
1.3. Code
from rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
2. ACNet Usage
2.1. Paper
"ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"
https://arxiv.org/abs/1908.03930
2.2. Overview
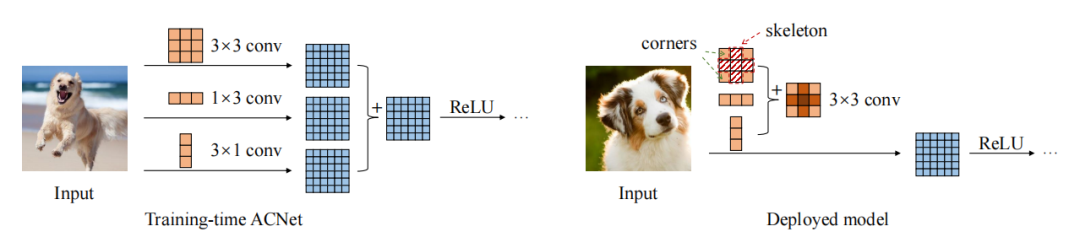
2.3. Code
from rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
3. Diverse Branch Block Usage
3.1. Paper
"Diverse Branch Block: Building a Convolution as an Inception-like Unit"
https://arxiv.org/abs/2103.13425
3.2. Overview
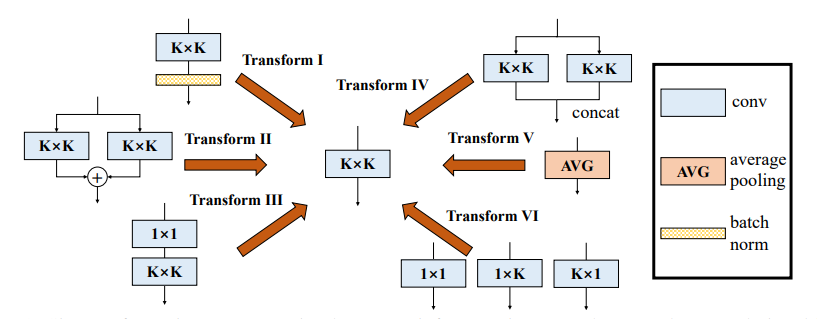
3.3. Code
3.3.1 Transform I
from rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
3.3.2 Transform II
from rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
3.3.3 Transform III
from rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
3.3.4 Transform IV
from rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
3.3.5 Transform V
from rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
3.3.6 Transform VI
from rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
▊ Convolution Series
Pytorch implementation of "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"
Pytorch implementation of "Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"
Pytorch implementation of "Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"
1. Depthwise Separable Convolution Usage
1.1. Paper
"MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"
https://arxiv.org/abs/1704.04861
1.2. Overview
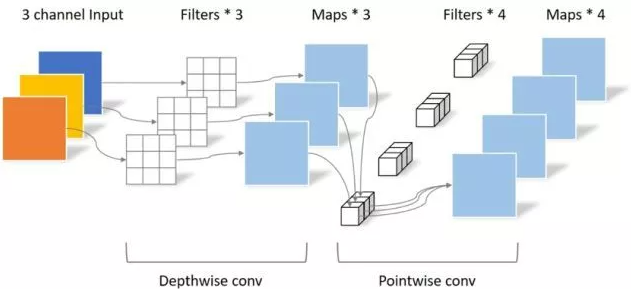
1.3. Code
from conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
2. MBConv Usage
2.1. Paper
"Efficientnet: Rethinking model scaling for convolutional neural networks"
http://proceedings.mlr.press/v97/tan19a.html
2.2. Overview
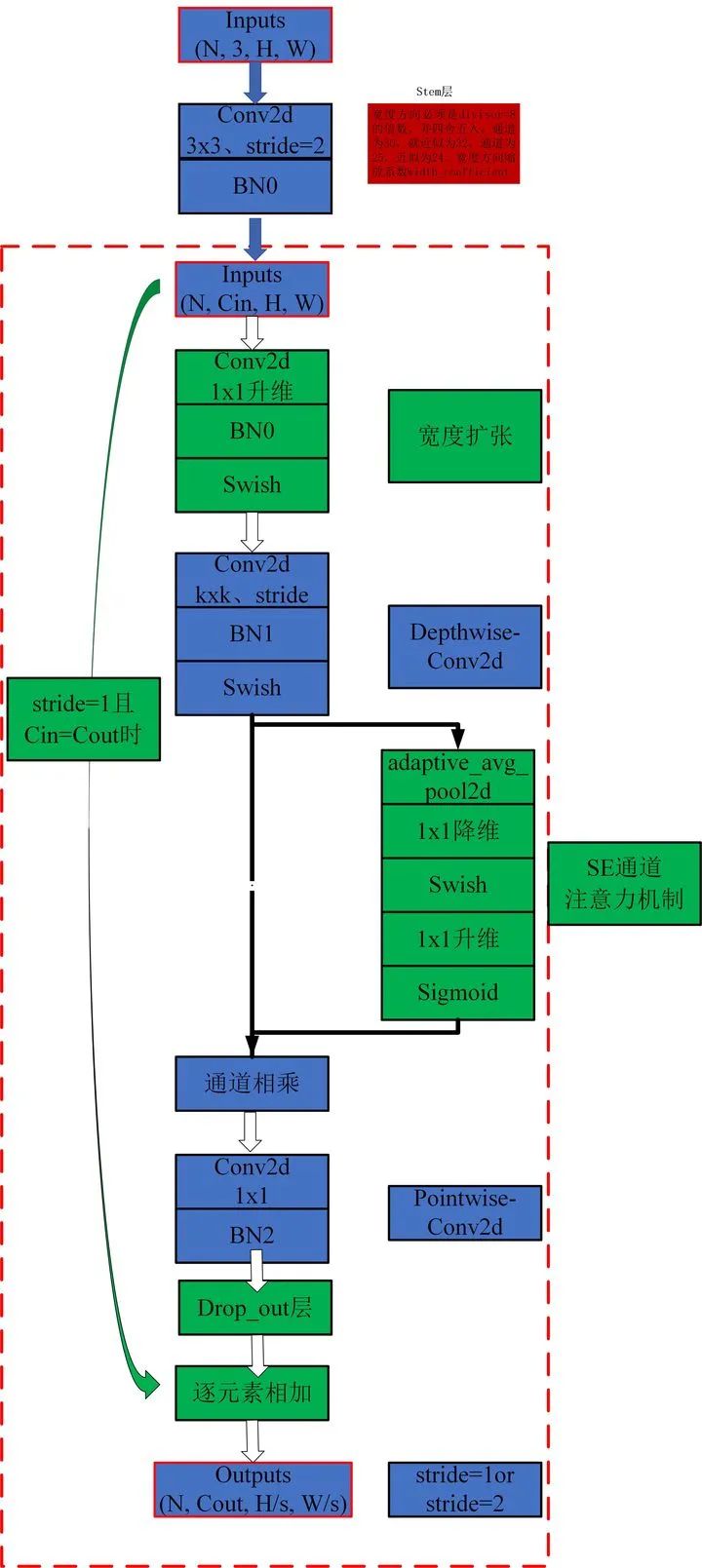
2.3. Code
from conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
3. Involution Usage
3.1. Paper
"Involution: Inverting the Inherence of Convolution for Visual Recognition"
https://arxiv.org/abs/2103.06255
3.2. Overview
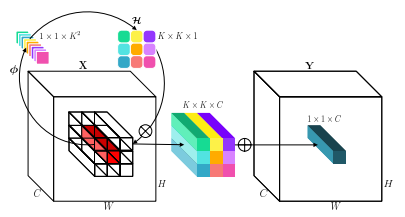
3.3. Code
from conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
在我爱计算机视觉公众号后台回复 “深度学习论文” 即可收到本文盘点的所有论文。

备注:CV

计算机视觉交流群
图像分割、姿态估计、智能驾驶、超分辨率、自监督、无监督、等最新资讯,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









