






由于linux栈的空间相对较小,默认是8M,容易因为递归深度过大,函数调用嵌套深度过大,局部变量开辟过大导致栈溢出,从而使程序崩溃,有必要监控栈在程序运行情况的变化
linux没有专门的接口获取当前栈的使用率,只能通过间接计算得出
linux通常使用pthread创建线程,线程的属性也是可以设置的,包括了线程的栈空间大小
pthread_t my_thread;
pthread_attr_t thread_attr;
size_t stack_size = 8192; // 设置栈大小为8MB
// 初始化线程属性
pthread_attr_init(&thread_attr);
// 设置线程栈大小
pthread_attr_setstacksize(&thread_attr, stack_size);
// 创建线程
if (pthread_create(&my_thread, &thread_attr, &thread_function, NULL) != 0) {
fprintf(stderr, "Failed to create thread\n");
exit(EXIT_FAILURE);
}
我们目的是求栈的使用率,首先由下列公式计算
usage = used/total*100%
ps:
usage–当前线程栈空间使用率
used–当前线程栈空间使用量
total–线程栈空间总大小,也就是上文的stack_size
所以未知量为used,接下来说一下怎么求used
我们可以通过下方接口,获取到栈的基地址
void *stack_addr;
size_t stack_size;
memset(&attr, 0, sizeof(pthread_attr_t));
pthread_getattr_np(pthread_self(), &attr);
pthread_attr_getstack(&attr, &stack_addr, &stack_size);
根据linux进程的内存模型,栈是向下增长的,高地址往低地址生长
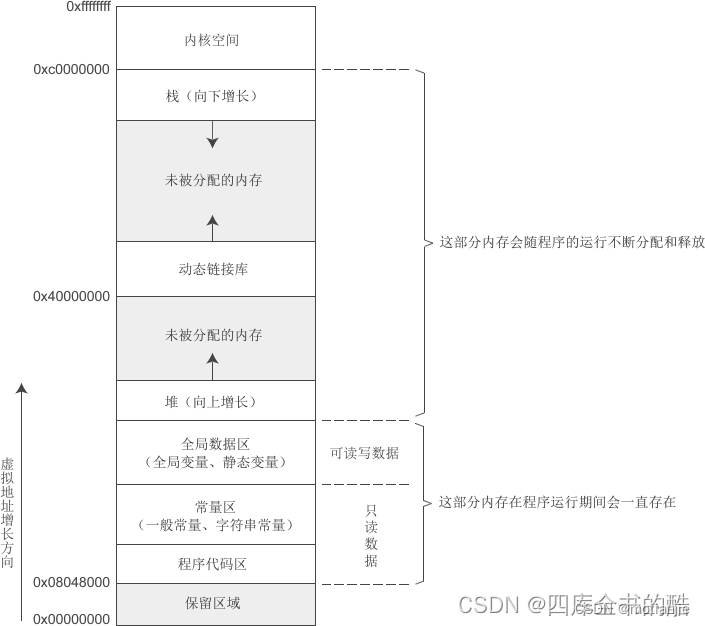
图片出处:https://blog.youkuaiyun.com/weixin_46535567/article/details/124628100
根据分析得出下方的栈空间具体布局
/*
----------------------------------- thread stack bottom
s-----------------------------------
i-----------------------------------
z----------------------------------- rsp
e
----------------------------------- thread stack top==base addr
*/
rsp栈指针(sp指针)表示当前栈指针的地址
stack bottom栈底=stack top + stack_size
所以栈底地址也知道了,接下来要求rsp的值
使用到了内联汇编技术
以下来自gpt的介绍
内联汇编是在高级语言代码中直接嵌入汇编代码的一种技术,通常用于需要对底层硬件进行精确控制或者进行高性能优化的情况。在C语言中,可以使用内联汇编来编写一些特定的汇编指令,这些指令会与C代码混合在一起编译成最终的可执行程序。
关于内联汇编的更多细节可以看下方的详细介绍
其实就一行代码,实现将rsp寄存器的值赋值给了rsp_value
size_t rsp_value;
asm volatile ("movq %%rsp, %0" : "=rm" (rsp_value));
至此,所有未知量已求得,具体计算如下
float thread_stack_usage_cal()
{
size_t rsp_value;
asm volatile ("movq %%rsp, %0" : "=rm" (rsp_value));
pthread_attr_t attr;
void *stack_addr;
size_t stack_size;
memset(&attr, 0, sizeof(pthread_attr_t));
pthread_getattr_np(pthread_self(), &attr);
pthread_attr_getstack(&attr, &stack_addr, &stack_size);
pthread_attr_destroy(&attr);
auto avail = rsp_value - (size_t)stack_addr; //计算距离最高栈顶的距离为剩余栈空间
auto used = stack_size - avail; //总空间-剩余空间=已使用的栈空间
auto usage = (float)((float)used / (float)stack_size)*100;//计算使用率
printf("thread stack info: used = %ld, avail = %ld, total = %ld usage = %lf%%\n",
used,
avail,
stack_size,
usage);
return usage;
}
测试:
void test()
{
static unsigned long stack_size = 1024*1024*1;
while(1)
{
unsigned char test[stack_size];
thread_stack_usage_cal();
stack_size+=1024*1024*1;
}
}
int main()
{
std::thread thread1(test);
thread1.join();
return 0;
}

我们通过逐渐扩大局部变量的大小来测试栈使用率计算接口的正确性
初始是1M,逐渐以1M的速度递增,可以看到每次计算的增量是12.5%
栈总大小为8M,所以达到最大值后栈溢出发生coredump
可以证明计算的正确性,可以监控到栈的使用率变化,当然可能会说为什么看不到100%,因为thread_stack_usage_cal还未压栈,就因为局部变量过大溢出了
那么我们放缓增速再看看
void test()
{
static unsigned long stack_size = 1024*1024*1;
while(1)
{
unsigned char test[stack_size];
thread_stack_usage_cal();
stack_size+=1024;
}
}
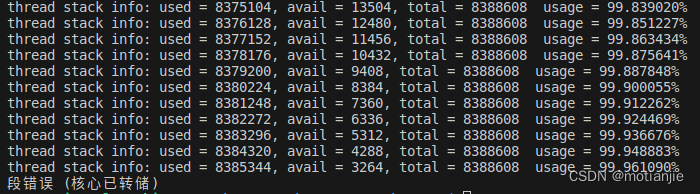
可以看到栈使用率增长到99.96%后溢出,已经很精确了
回到这里,为什么我的局部变量是1M的时候,总容量是8M,为什么使用率是12.55%,多了0.05%,这部分是因为我们thread_stack_usage_cal()函数也需要压栈占用一部分的栈空间,导致计算不是最准确的,但是相对可以反应出准确大小了

总结:
开发过程中可以增加对栈的使用率监控,做到心中有数,可以在压测的时候加上,防止特殊情况下栈溢出的风险
如果实在需要更大的栈空间,也是可以调整的
如果是全局调整,直接命令行输入ulimit -s <stack_size>,默认是8192
当然也不能直接设的很大,因为进程中每个线程的栈是独立的,随着线程数量增长,内存会呈线性增长,使得内存使用率上升,严重的情况下可能导致内存交换到硬盘,导致整体性能下降
如果仅对某个线程设置大小,可以在线程创建前,通过pthread_attr_setstacksize接口设置


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









