







 本文介绍了一种使用Python的requests库和re库爬取豆瓣电影《我不是药神》的短评数据的方法,详细展示了如何解析URL规律、设置请求头、使用正则表达式抓取评论内容、评论时间、评星数等信息,并利用pandas库将数据存储为Excel文件。
本文介绍了一种使用Python的requests库和re库爬取豆瓣电影《我不是药神》的短评数据的方法,详细展示了如何解析URL规律、设置请求头、使用正则表达式抓取评论内容、评论时间、评星数等信息,并利用pandas库将数据存储为Excel文件。
1 从url分析可以知道,每翻一页评论的话,url只是在start=的位置发生变动。因此分析出规律后,不断循环迭代即可爬取多页评论资源。
2 此次爬取的主要内容是,短评内容,有用数,评论者昵称,评论时间,评星数。这五方面的内容。下面直接上代码。
def get_info(page_num):
# 导入相应的库
import requests
import re
comment_texts = []
comment_stars = []
comment_votess = []
comment_times = []
user_infos = []
for i in range(page_num):
# 待爬取的链接
url = \
'https://movie.douban.com/subject/26752088/comments?start='+str(i*20) + \
'&limit=20&sort=new_score&status=P'
# 自定义请求头
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/73.0.3683.86 Safari/537.36 '}
# 设置cookies
cookies = {'cookie': '你自己的cookie'} # 此处需要你自己的登录cookie
res = requests.get(url, headers=headers, cookies=cookies)
# 判断请求是否正常,若不正常则抛出异常
if res.status_code != 200:
res.raise_for_status()
else:
print('请求正常,正在爬取第{}页'.format(i+1))
# 使用re库匹配相应评论内容
# 评论内容
comment_text = re.findall(re.compile('<span class=\"short\">(?s)(.+?)</span>'), res.text)
# 评论时间
comment_time = re.findall(r'<span class=\"comment-time \" title=\"(\d{4}-\d{2}-\d{2})', res.text)
# 评论星数
comment_star = re.findall(re.compile(r'(?:<span class=\"allstar\d{2} rating\" title=\"(\w+.?)\">'
r'</span>)*(?:\s*?)<span class=\"comment-time \"'), res.text)
# 评论用户昵称
user_info = re.findall(re.compile(r'<a title=\"(.+?)\" href'), res.text)
# 评论有用数
comment_vote = re.findall(re.compile(r'<span class=\"votes\">(.+?)</span>'), res.text)
# 扩展一下信息
comment_times.extend(comment_time)
comment_texts.extend(comment_text)
comment_stars.extend(comment_star)
comment_votess.extend(comment_vote)
user_infos.extend(user_info)
# 综合一下信息
comment_info = dict(评论者昵称=user_infos, 评论时间=comment_times, 评论星数=comment_stars,
评论点赞数=comment_votess, 评论内容=comment_texts)
return comment_info
def savedata(data):
import pandas as pd
dataframe = pd.DataFrame(data)
dataframe.to_excel(r'E:\douban.xlsx')
print('一共抓取了{}条数据'.format(dataframe.shape[0]))
def main():
"""
设计要求:
1 使用requests库+re库爬取豆瓣电影《我不是药神》的短评
2 数据存储用pandas库存储在本地磁盘
"""
# 导入相应模块
from spider_douban import get_info, savedata
# 设置爬取的页数
page_num = 50
# 获取数据
data = get_info.get_info(page_num)
# 保存数据
savedata.savedata(data)
print('数据已经保存完毕')
if __name__ == '__main__':
main()
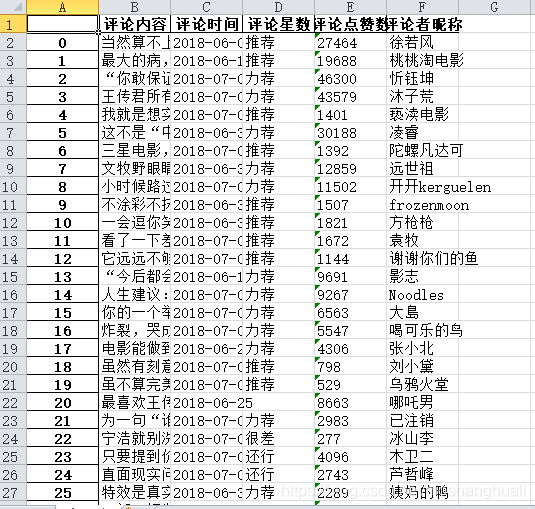
3 爬取结果:
4 经验总结:
1 如果只是简单的设置了请求头user_agent。只能爬取10页的内容。超过10页,出现403.服务器拒绝响应,这是豆瓣的反爬虫措施之一。
2 传入cookie,可以爬取500条数据,即25页数据。(自己手动正常浏览也是25页)可以看出豆瓣为了反爬虫,直接一刀切,不让用户看到过多的数据。
3 在获取评论内容的时候。需要注意,有些评论内容中带有换行符,如果只是简单的(.+?)这种表达式,没有办法匹配到,因此可能会出现有的页面你只能匹配到19或者18条数据。解决办法就是,带上扩展符号,re.s(即申明,. 可以匹配包括换行符在内的所有字符)
4 匹配评星数的时候,有的用户没有评星。因此在源码中就可以看到,用户评论信息中没有这一条。此时编写正则表达式,就不是仅仅依靠span标签那一行的内容。而是将表达式扩展一些(可以包含下面相邻的字段信息)
比如:



















 2630
2630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









