







图神经网络一
图机器学习需要解决的任务有:
- 节点分类 (Node classification) :预测每个节点的类型
- 链接预测 (Link prediction):预测两个节点是否相连
- 社区检测 (Community detection):检测密集连接的节点聚类
- 网络相似性检测 (Network similarity):计算两个网络的相似程度
前面章节介绍的是解决这些问题的传统机器学习方法,本节主要介绍图神经网络 (GNN) 的基本思路和训练基本流程。
基本方法:消息传递和聚合
图给我们的信息有:
- V V V 节点集合
- A \bf A A 节点的邻接矩阵
- X ∈ R m × ∣ V ∣ \bf X \in \R^{m \times |V|} X∈Rm×∣V∣ 节点特征
- N ( v ) N(v) N(v) 节点的的邻域节点集合
回顾之前的节点嵌入的内容,传统机器学习方法构造的是浅层次的节点嵌入,而深度学习可以看作是设计深层提取器 (Deep Encoder) 计算深层嵌入。一个比较直观的想法是将邻接矩阵 A \bf A A 输入一个多层神经网络来提取节点嵌入,示意图如下。这种方法缺点有:参数过多;不适用于不同大小的图;对节点顺序敏感(一旦改变节点顺序,预测结果就会不同)。
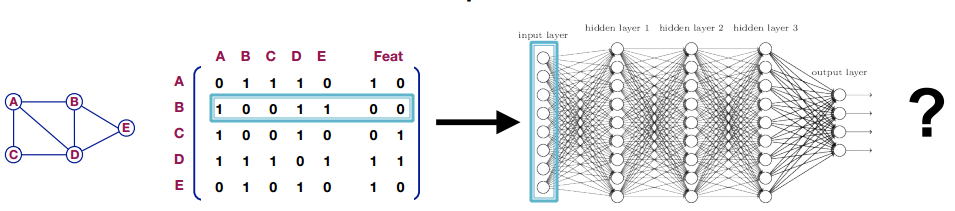
我们希望构建的神经网络参数量适当,能够泛化到不同大小的图,并且对节点顺序不敏感,也就是对节点有置换不变性 (Permutation invariant)。在卷积神经网络 (CNN) 中,每一个卷积核的参数对于当前特征图的每个像素是共享的,卷积操作实际上实对某个像素领域做加权平均,整个神经网络获取的信息是随着网络的加深而从局部逐渐扩展到全局。同样地,在图神经网络中,节点的特征也可以是由局部邻域节点和自身特征计算而来,在每一层图神经网络的节点嵌入都是通过某种方式综合节点及其邻域节点特征而得到的。
如下图所示,节点之间的虚线表示消息传递,方框内表示消息聚合,聚合方式使用神经网络。
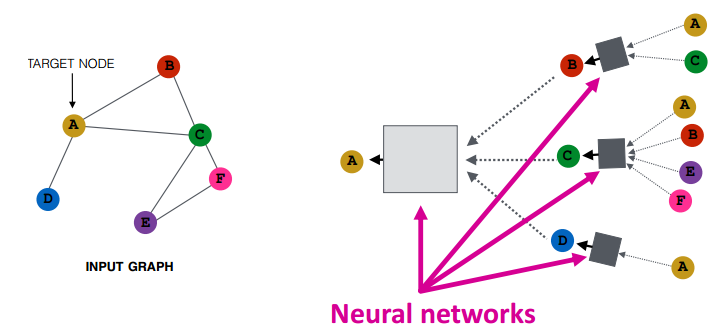
一种比较简单的聚合方式是对领域节点消息做平均,并加上节点自身的特征,得到当前层神经网络的节点嵌入。公式如下
h
v
(
l
+
1
)
=
σ
(
W
l
∑
u
∈
N
(
v
)
h
u
(
l
)
∣
N
(
v
)
∣
+
B
l
h
v
(
l
)
)
,
∀
l
∈
{
0
,
1
,
2
,
.
.
.
,
L
−
1
}
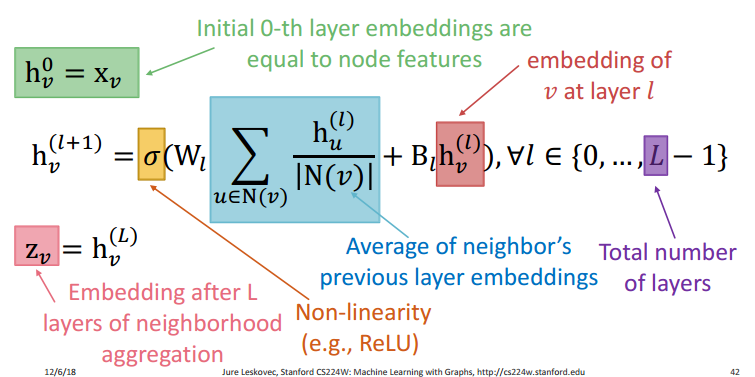
h_v^{(l+1)} = \sigma \left(\mathbf W_l \sum_{u \in N(v)} \frac {h_u^{(l)}}{|N(v)|} + \mathbf B_l h_v^{(l)} \right) , \quad \forall l \in \{0, 1, 2, ..., L-1 \}
hv(l+1)=σ⎝⎛Wlu∈N(v)∑∣N(v)∣hu(l)+Blhv(l)⎠⎞,∀l∈{0,1,2,...,L−1}
其中
h
v
(
l
)
h_v^{(l)}
hv(l) 表示第
l
l
l 层神经网络的节点嵌入,初始层节点嵌入为节点特征
h
v
(
0
)
=
x
v
h_v^{(0)} = x_v
hv(0)=xv,
W
l
\mathbf W_l
Wl 和
B
l
\mathbf B_l
Bl 为可学习参数,
N
(
v
)
N(v)
N(v) 为领域节点,
σ
\sigma
σ 为非线性激活函数。课程课件中的图可以做个参考。
对于所有节点,
W
l
\mathbf W_l
Wl 和
B
l
\mathbf B_l
Bl 的参数是共享的,用
H
(
l
)
\mathbf H^{(l)}
H(l) 表示所有节点的嵌入矩阵,
D
\mathbf D
D 为节点度矩阵,
A
\mathbf A
A为邻接矩阵,那么节点聚合的矩阵形式为
H
(
l
+
1
)
=
σ
(
A
~
H
(
l
)
W
l
T
+
H
(
l
)
B
l
T
)
\mathbf H^{(l+1)} = \sigma (\tilde{\mathbf A} \mathbf H^{(l)} \mathbf W_l^T + \mathbf H^{(l)} \mathbf B_l^T)
H(l+1)=σ(A~H(l)WlT+H(l)BlT)
其中
A
~
=
D
−
1
A
\tilde{\mathbf A} = \mathbf D^{-1} \mathbf A
A~=D−1A
训练图神经网络
对于有监督学习,以节点分类为例,GNN 最后一层输出的节点嵌入为
z
v
z_v
zv,损失函数通常为交叉熵损失函数,二分类计算公式如下
L
=
−
∑
v
∈
V
y
v
log
(
σ
(
z
v
T
θ
)
)
+
(
1
−
y
v
)
log
(
1
−
σ
(
z
v
T
θ
)
)
\mathcal L = -\sum_{v \in \mathbf V} y_v \log(\sigma(z_v^T \theta)) +(1-y_v) \log(1 - \sigma(z_v^T \theta))
L=−v∈V∑yvlog(σ(zvTθ))+(1−yv)log(1−σ(zvTθ))
对于无监督学习,节点没有标签,以结构相似性为学习目标,同样使用交叉熵损失函数,公式为
L
=
∑
z
u
,
z
v
CE
(
y
u
,
v
,
DEC
(
z
u
,
z
v
)
)
\mathcal L = \sum_{z_u, z_v} \text{CE}(y_{u, v}, \text{DEC}(z_u, z_v))
L=zu,zv∑CE(yu,v,DEC(zu,zv))
节点相似性度量方法,可以随机游走 (deep walk, node2vec, struc2vec) 或者矩阵分解的方法。
设计图神经网络
设计一个 GNN,主要分四步
- 定义节点消息聚合函数
- 定义节点嵌入损失函数
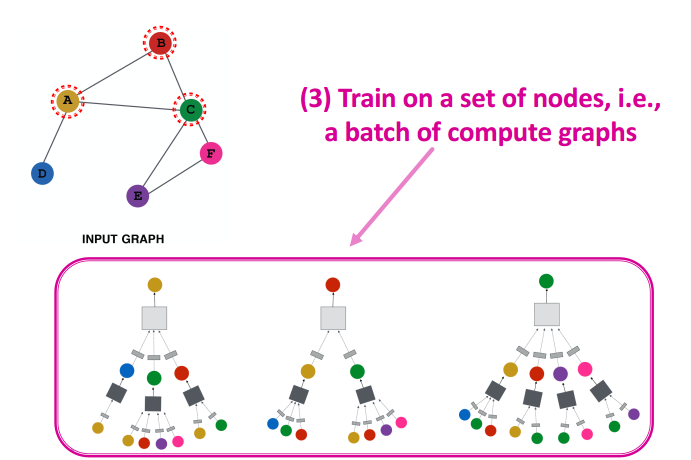
- 使用图中的部分节点训练网络
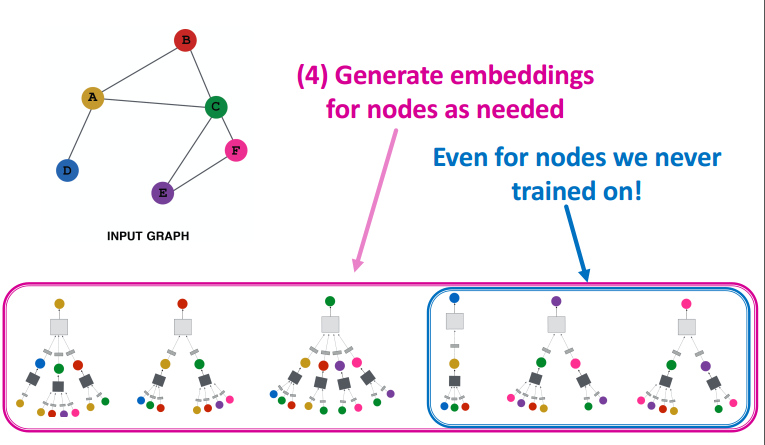
- 为每个节点生成期望的嵌入


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









