





DDD落地的难点是“聚合”
大家好,我是范钢老师。这些年,DDD一直在挣扎中前行。诚然,DDD已经在很多团队中得到了落地。然而,面对越来越庞大的软件研发大军,成功的团队依然是凤毛麟角。很多同学告诉我,DDD确实是个好东西,但真正落实到真实项目时,依然要面临诸多的困难。在面对这些困难的时候,有些问题可以得到解决,然而有些却不能得到很好地解决,这使得一些团队坚持一段时间以后,最终选择放弃。那么,开发团队在DDD实践中,到底要面对哪些困难呢?我们需要好好地探讨一下,切实地帮助大家去解决。只有把这些问题真正地解决了,才能有越来越多的团队实践DDD,使其真正成为今后软件开发的主流。
那么,开发团队在实践DDD的时候,会遇到哪些困难呢?第一个就是DDD中的概念不好理解,在实践中困惑很多;第二个就是基于DDD的软件开发过于繁杂,编码工作量大,使得DDD的推行与维护都会变得困难。而这两个难题最集中地体现就是“聚合”。因此,我们今天再次谈谈“聚合”,争取把这块巨石推倒,让它彻底得到解决。
聚合是DDD领域驱动设计中非常重要的一个概念,我在前面的文章中仔细给大家解读过,大家可以往前翻。简而言之,聚合代表的是一种整体与部分的关系,部分的关系在整体之内,我们希望用整体去封装部分,从而简化整个系统的设计。然而,什么时候使用聚合,什么时候最好不用,依然是很多同学在DDD实践中的一种困惑,我们举一个示例来探讨一下。
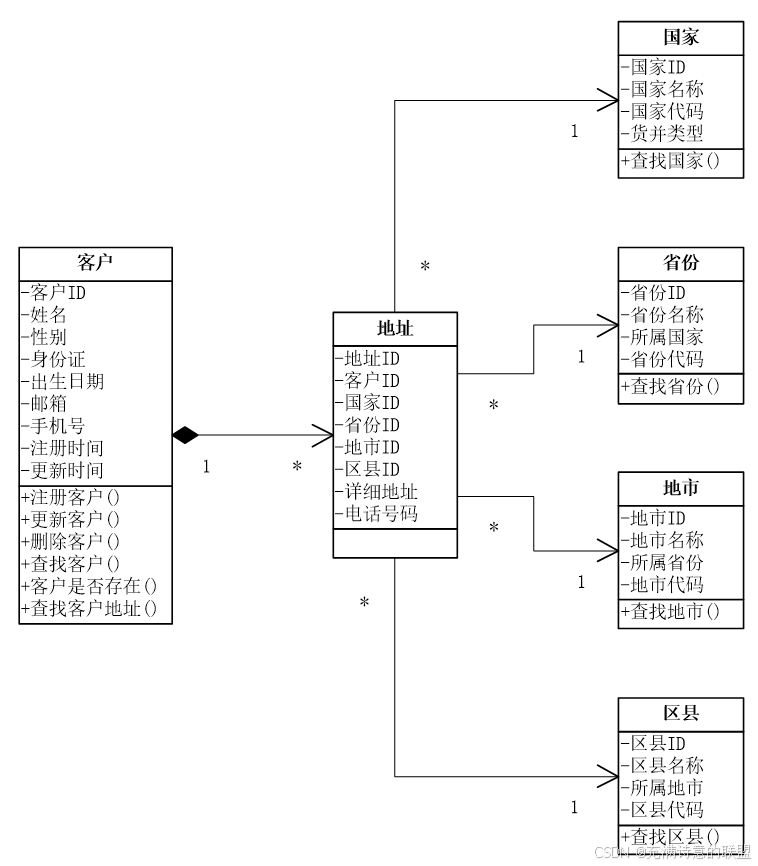
譬如,用户与地址是聚合吗?从概念上讲,它们确实是一种聚合,因此我们就把它们设计成了聚合关系,这没有问题。然而,落地到编码时就出现问题了,如果它们是聚合,就会形成一种约束,即用户封装地址,那么所有对地址的查找都必须要经过用户。然而,在查找订单时,需要带出与该订单相关的用户和地址。带出用户很简单,就直接根据用户编号查找就可以了;但要带出地址就麻烦了,聚合的约束决定了,不能直接查找地址,而是必须要经过用户才能查找地址。这时,聚合的设计就变成了一种累赘。那么,该怎么解决这个问题呢?
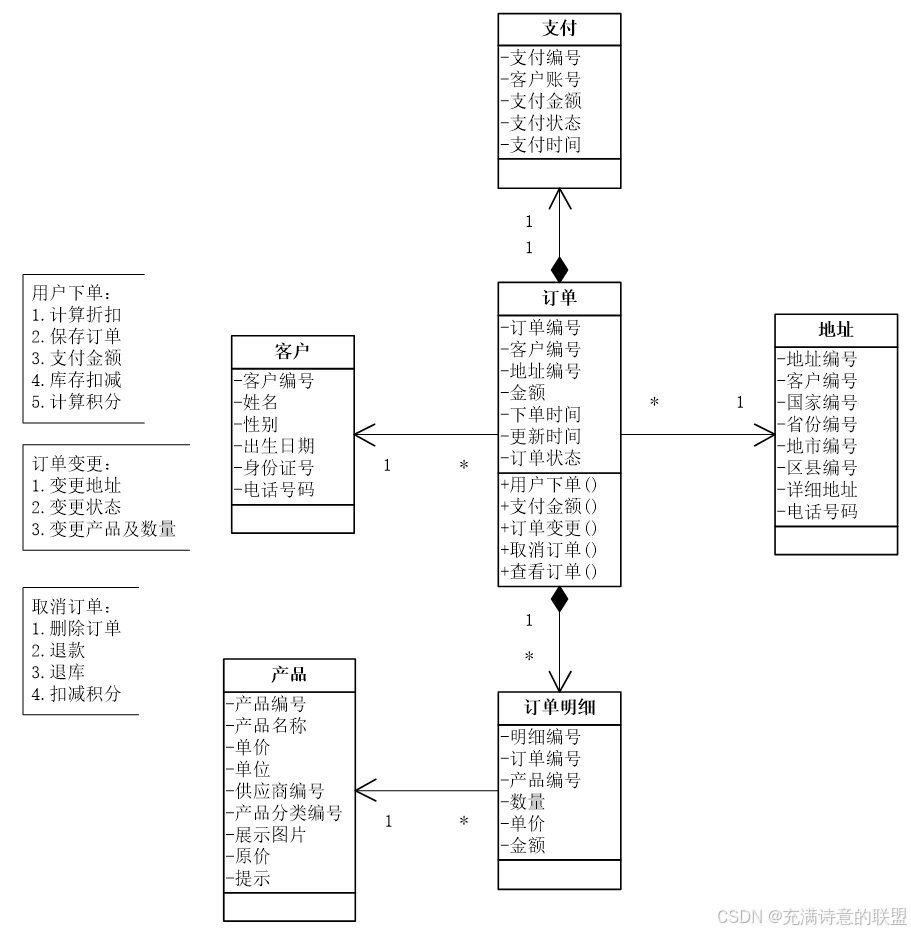
DDD的另外一个核心设计是限界上下文,通过它将一个复杂的系统划分成很多个子域,彼此独立地进行各自的设计。在用户上下文中,用户与地址都是实体,需要对其进行增删改操作,采用聚合就能够很好地发挥它的作用,因此采用聚合的设计。然而,同样是用户与地址,在订单上下文中是值对象,对它们只有查询操作,聚合没有其发挥的作用,因此就不采用聚合的设计。这样,就没有聚合的约束,地址不必通过用户就能查找,设计就变得顺畅了。
此外,即使是在用户上下文中,采用了聚合的设计,那么用户和地址的增删改又该如何设计实现呢?用户封装了所有对地址的操作,因此只有用户Service而没有地址Service,在增删改用户的同时,就要完成对地址的增删改,并且这两个操作还要在同一事务中进行。因此,在以往的设计实现时,就需要写一个用户仓库,来实现保存用户的同时,保存用户地址。这样,所有需要聚合的功能,都必须要分别去编写各自的仓库,用户要编写用户仓库,订单要编写订单仓库……这无疑就加大了DDD落地编码的难度与工作量。还是那句话,采用DDD应当使得编码变得简单而不是更加复杂。要解决这个问题的关键就是通过底层平台的封装,设计实现一个通用的仓库。所有的Service在持久化的时候,都注入这个通用仓库。我们只要在DSL中定义某些关系是聚合关系,通用仓库就会将它们的增删改按照聚合的方式进行持久化。
譬如,在以上案例中,将用户与地址设计成聚合关系,那么对应地就会编写这样的实体对象:
@EqualsAndHashCode(callSuper = true)
@Data
public class Customer extends Entity<Long> {
private Long id;
private String name;
private String gender;
private String email;
private String identification;
private Date birthdate;
private String phoneNumber;
private Date createTime;
private Date modifyTime;
private List<Address> addresses;
}地址在用户对象中是一个集合属性,但它并没有表达清楚它们是聚合关系,因此需要在DSL中进行如下配置,说明它们的聚合关系:
<do class="com.edev.emall.customer.entity.Customer" tableName="t_customer">
<property name="id" column="id" isPrimaryKey="true"/>
<property name="name" column="name"/>
<property name="gender" column="gender"/>
<property name="email" column="email"/>
<property name="identification" column="identification"/>
<property name="birthdate" column="birthdate"/>
<property name="phoneNumber" column="phone_number"/>
<property name="createTime" column="create_time"/>
<property name="modifyTime" column="modify_time"/>
<join name="addresses" joinKey="customerId" joinType="oneToMany"
isAggregation="true"
class="com.edev.emall.customer.entity.Address"/>
</do>这样,在用户Service中,当增删改用户时,就会注入一个通用仓库来完成持久化,编码如下:
public class CustomerServiceImpl implements CustomerService {
private final BasicDao dao;
public CustomerServiceImpl(BasicDao dao) {
this.dao = dao;
}
private void valid(Customer customer) {
isNull(customer, "customer");
isNull(customer.getId(), "id");
isNull(customer.getName(), "name");
}
@Override
public Long register(Customer customer) {
valid(customer);
customer.setCreateTime(DateUtils.getNow());
return dao.insert(customer);
}
@Override
public void modify(Customer customer) {
valid(customer);
customer.setModifyTime(DateUtils.getNow());
dao.update(customer);
}
@Override
public void remove(Long customerId) {
dao.delete(customerId, Customer.class);
}
@Override
public Customer load(Long customerId) {
return dao.load(customerId, Customer.class);
}
@Override
public boolean exists(Long customerId) {
return load(customerId)!=null;
}
}这里进行持久化的是BasicDao,它仅仅是一个接口,在装配的时候就会注入通用仓库repository:
@Configuration
public class OrmConfig {
@Autowired @Qualifier("basicDao")
private BasicDao basicDao;
@Autowired @Qualifier("basicDaoWithCache")
private BasicDao basicDaoWithCache;
@Autowired @Qualifier("repository")
private BasicDao repository;
@Autowired @Qualifier("repositoryWithCache")
private BasicDao repositoryWithCache;
@Bean
public CustomerService customer() {
return new CustomerServiceImpl(repositoryWithCache);
}
@Bean
public AccountService account() {
return new AccountServiceImpl(repository);
}
@Bean
public JournalAccountService journalAccount() {
return new JournalAccountServiceImpl(basicDao);
}
@Bean
public CountryService country() {
return new CountryServiceImpl(basicDaoWithCache);
}
}在这里可以看到,BasicDao接口有4个实现:basicDao是一个普通的DAO,不会执行诸如聚合等DDD的操作。譬如,journalAccount对象在持久化时就只会增删改t_journal_account表;customer对象有聚合操作,因此注入了repository,在增删改用户的同时就会增删改用户地址,并放到同一事务中。此外,如果注入了basicDaoWithCache、repositoryWithCache,在查询时就会有缓存的支持。开发人员可以根据不同的场景自由地选择。
通过这种通用仓库的设计,开发人员只需要关注领域模型,然后将领域模型直接映射成领域对象、Service与DSL,其它的工作就交给底层去完成,DDD落地的设计编码就变得简单了。设计编码变得简单了,今后在越来越复杂的系统中迭代变更也就变得容易了,我们的团队就能快速交付,真正敏捷起来。通用仓库的具体设计实现,详见我的示例代码。
除此之外,关于聚合另外一个非常重要的思考是:聚合什么时候该用,什么时候不该用。聚合代表的是一种整体与部分的关系,是一种强耦合的关系。一旦将某些对象之间的关系设计成聚合关系,那么它们就变成原子的、密不可分的关系了。今后,不论系统如何变更,限界上下文的划分如何变化,拥有聚合关系的对象之间永远不能划分到不同的上下文中。这时,这种聚合的设计就会给未来的更迭带来不少麻烦,因此关于聚合的设计一定要慎重,必须要保证这种关系确实是原子的、强关联的、密不可分的,否则就不要设计成聚合,而仅仅是普通关系。
(待续)
譬如,会员与用户是聚合关系吗?从业务上你可以认为会员是用户档案的一个部分,因此你可以将用户与会员设计成聚合关系。然而,一旦将用户与会员设计成聚合关系,那么它们就变得密不可分了。随着日后业务的更迭,会员的业务变得越来越复杂,因此就希望将会员从用户上下文中拆分出来,单独形成一个会员上下文,进而在设计编码时单独拆分出一个会员微服务。然而,因为用户与会员设计成了聚合关系,它们之间就不能拆分,除非修改设计,将这种聚合关系取消。因此,在具体项目中,聚合的设计一定要谨慎,必须是强相关、牢固不可分的关系才能设计成聚合,否则宁愿设计成普通关系。订单与付款的场景也是这样的。只有“一对一”与“一对多”关系可能形成聚合,其它关系永远不可能形成聚合。
总之,聚合是DDD落地实践中最大的难点,它虽然是领域驱动设计中最独特的设计思想,但我们在实际项目中对聚合的使用一定要冷静。聚合的主要作用是解决复杂业务中增删改的问题,使其设计得到简化,所以聚合主要是运用在各业务场景中实体对象间的操作。在这些场景中,实体间一旦被设计成聚合,那么就要遵循聚合的约束,即整体封装部分,对部分的所有操作都是封装在整体之内的,而不会跳过整体直接去操作部分。一旦设计成聚合,在持久化存储的时候,整体也要封装部分,即没有单独对部分的增删改,只有对整体的增删改。对整体增删改的同时,也在增删改部分。在另外一些场景中,即使这些领域对象之间是整体与部分的关系,但它们是值对象,在该场景中没有对它们增删改的操作,只有查询的操作,也不会将其设计成聚合,也就不必遵循聚合的约束了。
除此之外,聚合关系不要滥用。在真实世界中,对象与对象之间有非常广泛的关系,但只有那些联系非常紧密的、原子的、永远密不可分的关系才能设计成聚合。设计成聚合以后,即使今后随着业务变得越来越复杂而不断拆分限界上下文,聚合关系之间的领域对象也不可能被拆分到不同的上下文。因此,在增删改时,聚合关系的增删改永远不可能出现跨库的事务操作。如果出现了跨库的事务,就需要仔细去审视我们的设计,到底应不应该拆分上下文,到底应不应该设计成聚合。
如果对以上内容感觉有用,欢迎关注、点赞、转发!
(待续)

















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









