




一个Agent都需要哪几个模块?如何从0-1搭建一个Agent?从一个简单的聊天机器人到一个真正的智能体(Agent),核心在于从“被动响应”变为“主动规划和使用工具”。
下面是详细分解一个Agent所需的模块,并提供一个从0到1的搭建路线图。
第一部分:一个Agent的核心模块
一个功能完整的Agent通常包含以下五个核心模块,它们共同协作,形成“感知-思考-行动”的循环。
1. 规划模块(Planning Module / "大脑")
-
功能:这是Agent的“大脑”,通常由一个大语言模型(LLM)驱动。它的核心任务是理解和规划。
-
任务分解:将用户的复杂指令拆解成一系列可执行的子任务或步骤(Chain of Thought)。
-
战略思考:决定下一步该做什么,是调用工具,还是直接回答,或者需要向用户澄清问题。
-
自我反思:对执行结果进行评估,判断是否解决了问题,若未解决,是否需要调整计划(ReAct模式中的
Thought)。
-
-
技术实现:主要通过精心设计的提示词(Prompt Engineering) 来引导LLM完成上述工作。
2. 工具模块(Tools Module / "手脚")
-
功能:这是Agent与外部世界交互的“手脚”。它扩展了LLM的能力边界,使其不再局限于文本生成。
-
工具集合:一个注册了各种外部工具的“工具箱”,例如:
-
搜索引擎(如Serper API、Google Search)
-
代码解释器(执行Python代码进行数学计算、数据分析)
-
RAG知识库(从内部文档检索信息)
-
API连接器(操作数据库、发送邮件、控制智能家居)
-
专用软件(如Photoshop、AutoCAD的插件)
-
-
-
技术实现:每个工具都是一个函数或API接口。现代最佳实践是使用像MCP(模型上下文协议) 这样的标准来管理和调用工具,实现安全性和解耦。
3. 记忆模块(Memory Module / "经验")
-
功能:让Agent拥有“记忆”,使其能在长时间的互动中保持上下文一致性。记忆分为两种:
-
短期记忆:通常指当前会话的上下文,即聊天记录。LLM的上下文窗口限制了其短期记忆容量。
-
长期记忆:指超越当前会话的、需要被持久化存储和 recalled(召回)的信息。这通常通过外部向量数据库来实现。
-
** recall**:根据当前对话,从向量数据库中搜索相关的历史信息,并将其作为上下文注入到本次对话中。
-
-
-
技术实现:短期记忆由LLM的上下文窗口管理;长期记忆则使用像ChromaDB、Pinecone、Weaviate这样的向量数据库来存储和检索嵌入(Embeddings)后的对话历史。
4. 执行模块(Execution Module / "小脑")
-
功能:这是连接“大脑”和“手脚”的“神经系统”和“小脑”。它负责调度和协调。
-
调用工具:接收“规划模块”的指令,具体地去调用“工具模块”中的某个工具函数,并传入正确的参数。
-
处理结果:接收工具返回的结果(可能是成功的数据、也可能是错误信息),并将其格式化后返回给“规划模块”进行下一步决策。
-
-
技术实现:这是一个控制循环(如ReAct循环),通常用Python等编程语言编写逻辑,负责在LLM推理和工具调用之间来回切换。
5. 用户交互模块(User Interface Module / "面孔")
-
功能:与用户进行交互的界面。这可以是非常灵活的形式。
-
命令行界面:最简单直接的形式。
-
Web应用:基于Streamlit、Gradio、FastAPI构建的聊天窗口。
-
集成到现有平台:作为Slack、Discord、Teams的一个机器人。
-
语音接口:与语音识别和合成技术结合
-
第二部分:从0到1搭建一个Agent的路线图
搭建一个Agent是一个迭代过程,建议从简单开始,逐步增加复杂性。
阶段一:设计与规划(第0步)
-
明确目标:你的Agent要解决什么具体问题?它的边界在哪里?
-
例子:“我要一个能帮我分析公司财报的Agent,它能从网上获取最新股票代码,能读取我上传的PDF财报,并能回答关于营收、利润和增长率的问题。”
-
-
定义能力:基于目标,决定它需要哪些工具?
-
必备工具:RAG工具(用于解析PDF)、网络搜索工具(获取股票实时价格)、代码解释器(计算增长率等指标)。
-
-
选择技术栈:
-
LLM API:OpenAI GPT-4o, Anthropic Claude 3, 开源模型(Llama 3, DeepSeek-V3等)。
-
开发框架:LangChain或LlamaIndex(它们提供了大量Agent相关的内置组件和模板,极大简化开发流程)。如果你追求极致的控制和最新协议(如MCP),也可以直接用SDK(如Anthropic的Python SDK)从头构建。
-
记忆存储:对于简单应用,内存就够了;对于需要长期记忆的,选择ChromaDB(轻量)或Pinecone(云端、强大)。
-
工具:根据需求选择,例如SerperAPI用于搜索,Apify用于爬虫。
-
阶段二:基础搭建(第1-3步)
第1步:搭建一个“哑巴”聊天机器人
-
使用你选择的LLM API和框架(如LangChain),先做一个能连贯对话的基础聊天机器人。这是你的“大脑”基础。
-
目标:实现简单的多轮对话。
第2步:集成第一个工具(如RAG)
-
选择一个最简单的工具开始集成,比如RAG。
-
实现流程:用户提问 -> 触发RAG工具 -> 从向量库检索文档 -> 将文档片段加入Prompt -> LLM生成答案。
-
目标:让Agent学会“查资料”,而不是仅凭内部知识回答。
第3步:实现最简单的Agent循环(ReAct模式)
-
这是最关键的一步,从“工具调用”升级到“Agent”。
-
实现一个ReAct循环:
-
将用户问题和一个提示词模板(Prompt Template)一起发给LLM。模板要求LLM输出
Thought,Action,Action Input。-
Thought: LLM分析当前情况,决定下一步。 -
Action: 它决定要调用哪个工具(例如search_web)。 -
Action Input: 调用该工具所需的参数(例如"Apple Inc. Q2 2024 earnings")。
-
-
你的代码(执行模块)解析LLM的输出,调用指定的工具。
-
获取工具返回的
Observation(观察结果),将其和之前的历史一起再次喂给LLM。 -
LLM进行下一步
Thought,如果认为信息足够,则最终输出Final Answer。
-
-
目标:实现“思考-行动-观察”的循环,让Agent能自主决定何时、如何使用工具。
阶段三:迭代与增强(第4-5步)
第4步:增加更多工具和记忆
-
根据阶段一的设计,逐步加入更多工具(如计算器、API连接器等)。
-
集成长期记忆系统,让Agent能记住跨会话的重要信息。
-
使用MCP:如果你的技术栈支持(如Claude),开始用MCP Server来标准化你的工具,提升安全性和可维护性。
第5步:优化提示词与测试
-
提示词工程:这是Agent智能度的关键。不断优化你的核心提示词模板,让LLM更好地进行任务分解和工具调用。提供清晰的示例(Few-shot learning)非常有效。
-
全面测试:用大量不同且刁钻的用例测试你的Agent,观察它在边缘情况下的表现,修复错误的工具调用和逻辑循环。
阶段四:部署与监控(第6步)
-
选择部署方式:打包成Docker容器,部署到云服务器(AWS, Azure, GCP),或发布为应用。
-
构建用户界面:为你的Agent创建一个友好的UI,例如用Gradio或Streamlit快速构建一个Web界面。
-
添加监控:记录日志,监控Token消耗、工具调用延迟和成功率,以便持续优化。
总结:从简单开始
不要想着一口吃成胖子。你的第一个Agent可以简单到:
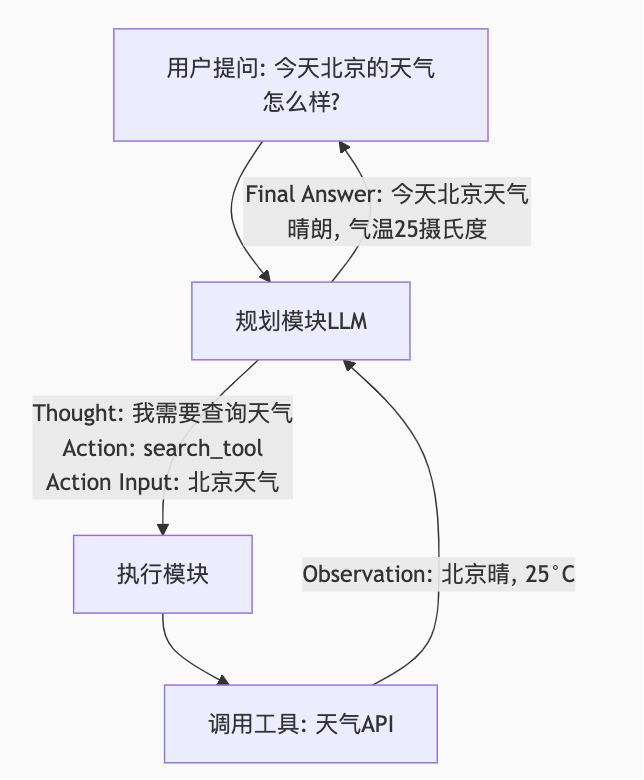
从这个最小可行产品(MVP)开始,一步一步地添加RAG、记忆、更多工具,你就会逐渐构建起一个功能强大的智能体。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









