







 本文介绍如何使用爬虫获取新浪财经期货的最新数据,包括分钟数据、日K线数据,并解析数据字段含义。同时建议在爬取数据时伪装User-Agent,提醒读者此方法适用于历史数据回测和应急数据补充,不适合高频交易。
本文介绍如何使用爬虫获取新浪财经期货的最新数据,包括分钟数据、日K线数据,并解析数据字段含义。同时建议在爬取数据时伪装User-Agent,提醒读者此方法适用于历史数据回测和应急数据补充,不适合高频交易。
目录
最新数据(当日)
代码
import arrow
import requests
import traceback
def sina_future_request(ctrid):
# 请求
url = "http://hq.sinajs.cn/list=" + 'nf_' + ctrid
# 伪装一下浏览器,写一下referer
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'Referer': 'https://finance.sina.com.cn/'}
stock_info = ""
result = {}
try:
page = requests.get(url, headers=headers)
stock_info = page.text
# print(stock_info)
except Exception as e:
errorWord = traceback.format_exc()
print(errorWord)
else:
# 爬取到数据信息
if stock_info != "":
mt_info = stock_info.split(",")
result = mt_info[5]
else:
result = 0
return result
result = sina_future_request('SR2209')
print(result)这里要记住新浪财经的郑商所是6码而真正CTP接口,郑商所是5码。然后这里商品期货要加前缀nf_ 不知道为啥。里面的referer一定要这样写,否则就报错,也不知道为啥
字段释义:
['var hq_str_nf_SR2209="白糖2209', ——代码
'145959',————可能是14:59:59的意思
'5862.000',————开盘价
'5879.000',————最高价
'5818.000',————最低价
'5847.000',————不知道什么价格
'5847.000',————收盘价
'5848.000',————卖一价
'5847.000',————买一价
'5853.000',————今日结算价(一直在变)
'5856.000',————昨日结算价
'16',————买一量
'31',————卖一量
'410278.000',————持仓量
'255137',————总手(成交量)
'郑',
'白糖',
'2022-06-24', ————日期
'1',
'',
'',
'',
'',
'',
'',
'',
'',
'5853.000',————今日均价
'0.000',
'0',
'0.000',
'0',
'0.000',
'0',
'0.000',
'0',
'0.000',
'0',
'0.000',
'0',
'0.000',
'0',
'0.000',
'0";\n']
分钟数据
代码
周期有1,5,10,15,30,60,每一批大小都是1mb,每一个数据是1kb,所以1023条数据,还有1kb可
能是别的什么数据。最后格式整理成列表。
import arrow
import requests
import traceback
import re
# 1,5,10,15,30,60
def sina_future_request_min(ctrid,freq:int):
# 13位时间戳
unix_timestamp = int((arrow.now().timestamp +
arrow.now().microsecond / 1000000)*1000)
# 请求
# 一次给1mb的数据,也就是1023条,1条1kb
url = "https://stock2.finance.sina.com.cn/futures/api/jsonp.php/" + \
"var%20_" + ctrid.upper() + "_" + str(freq) + "_" + str(unix_timestamp) + \
"=/InnerFuturesNewService.getFewMinLine?symbol=" + ctrid.upper() + "&type=" + str(freq)
# 表头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'Referer': 'https://finance.sina.com.cn/'}
stock_info = ""
result = []
try:
page = requests.get(url, headers=headers)
stock_info = page.text
# print(stock_info)
except Exception as e:
errorWord = traceback.format_exc()
print(errorWord)
else:
# 爬取到数据信息
if stock_info != "":
mt_info = stock_info.split("(")
mt_info = mt_info[1]
mt_info = re.sub("\)|;","",mt_info)
mt_info = eval(mt_info)
result = mt_info
else:
result = []
# 列表里最后一个其实不是分钟数据,而是下一个交易日的日线数据,大家记得要去掉它
if result != []:
result = result[0:len(result) - 1]
return result
result = sina_future_request_min('AG2212',30)
print(result)列表里最后一个其实不是分钟数据,而是下一个交易日的日线数据,大家记得要去掉它
数据释义
列表中其中一串数据为例
{'d': '2022-03-31 14:45:00',————时间
'o': '5067.000',————开
'h': '5070.000',————高
'l': '5060.000',————低
'c': '5064.000',————收
'v': '133',————成交量
'p': '25999'}————持仓量
当日1分钟K线(分时线)
代码
import arrow
import requests
import traceback
def sina_future_request_intraday_1minute(ctrid):
# 请求
url = "https://stock2.finance.sina.com.cn/futures/api/jsonp.php/var%20t1nf_" + \
ctrid.upper() + "=/InnerFuturesNewService.getMinLine?symbol=" + ctrid.upper()
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'Referer': 'https://finance.sina.com.cn/'}
stock_info = ""
result = []
try:
page = requests.get(url, headers=headers)
stock_info = page.text
# print(stock_info)
except Exception as e:
errorWord = traceback.format_exc()
print(errorWord)
else:
# 爬取到数据信息
if stock_info != "":
mt_info = stock_info.split("(")
mt_info = mt_info[1]
mt_info = re.sub("\)|;", "", mt_info)
mt_info = eval(mt_info)
result = mt_info
else:
result = []
return result
result = sina_future_request_intraday_1minute('SR2209')
print(result)
数据释义
['22:59', '5868.000', '5836.000', '1470', '408779']
时间,最新价,均价,分时成交量,总持仓量
历史+当日日K线
代码
import arrow
import requests
import traceback
def sina_future_request(ctrid):
# 请求
ctrid = ctrid.upper()
nowDateStr = arrow.now().format('YYYY_M_DD')
url = "https://stock2.finance.sina.com.cn/futures/api/jsonp.php/var%20_" + \
ctrid + nowDateStr + \
"=/InnerFuturesNewService.getDailyKLine?symbol=" + \
ctrid+ "&_=" + nowDateStr
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'Referer': 'https://finance.sina.com.cn/'}
stock_info = ""
result = {}
try:
page = requests.get(url, headers=headers)
stock_info = page.text
# print(stock_info)
except Exception as e:
errorWord = traceback.format_exc()
print(errorWord)
else:
# 爬取到数据信息
if stock_info != "":
mt_info = stock_info.split("(")
mt_info = mt_info[1]
mt_info = re.sub("\)|;", "", mt_info)
mt_info = eval(mt_info)
result = mt_info
else:
result = []
return result
result = sina_future_request('SR2209')
print(result)数据释义
{'d': '2022-06-24', 'o': '5862.000', 'h': '5879.000', 'l': '5818.000', 'c': '5847.000', 'v': '255137', 'p': '410278', 's': '5853.000'}
日期,开,高,低,收,成交量,持仓量,昨日结算价
授人以鱼不如授人以渔
其实说到底这个就是一个小爬虫, 为了防爬虫或者优化之类的,新浪财经已经更换了url的格式,网络上大部分的新浪期货的api文章都是过时的。我这篇文章也会有过时的时候,到时大家怎么办呢?
很简单,以白糖期货为例打开新浪财经白糖期货比如SR209页面,按你的F12,然后找到netWork,然后仔细观察下面的name列,多点击页面,就可以知道最新的请求格式是什么样的了。或者ctrl+f,搜索关键字,比如周期或者方法名
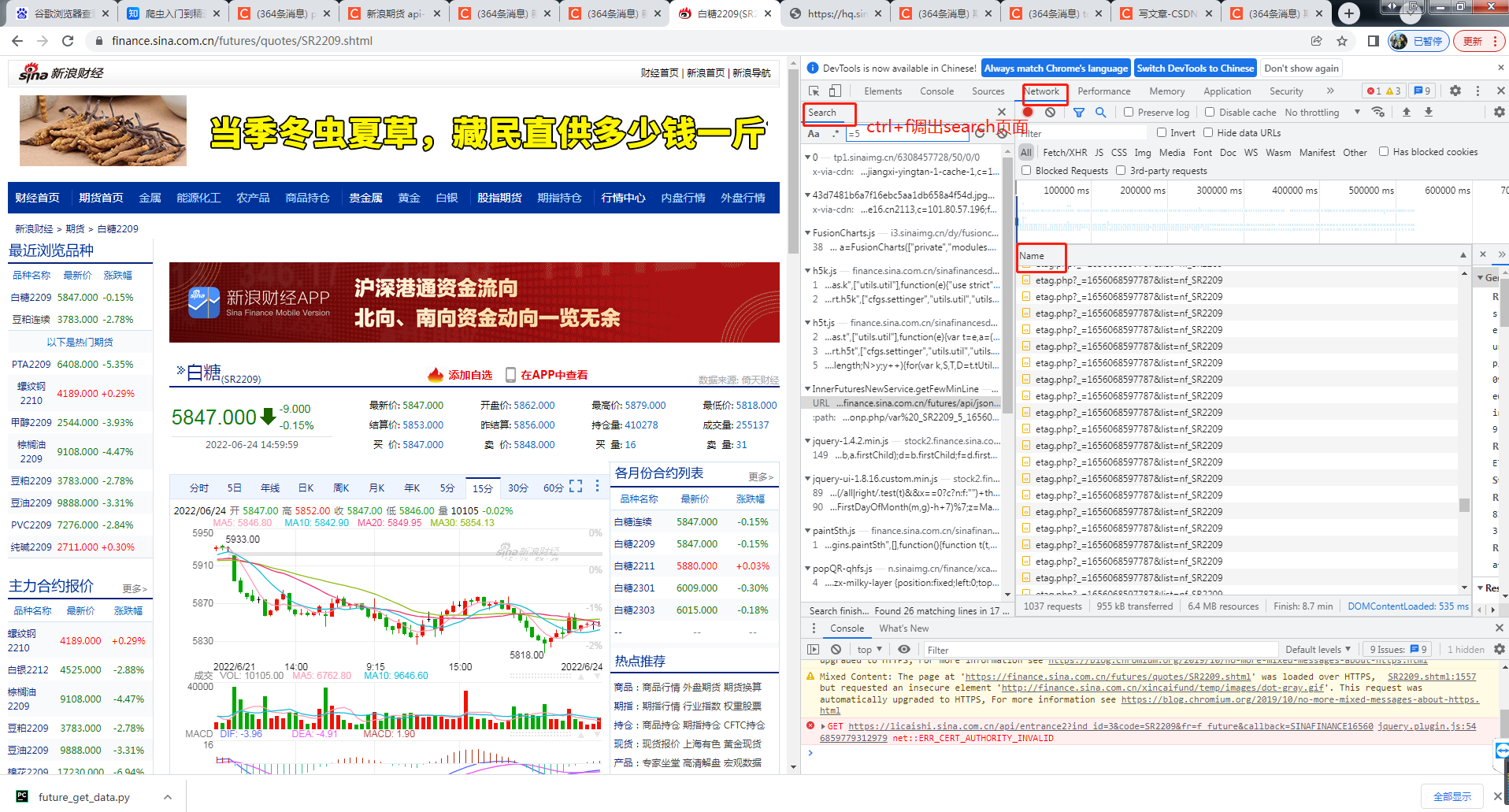
大家在写爬虫的时候记得伪装一下自己的user-agent,保险起见装成浏览器,方法的话见最后的连接。
但是大家要记住,这个只适合记录历史数据到本地做回测,或者拉一下最新数据(策略频率不高的话,高频还是自己用ctp吧),日内分钟数据,大家还是尽可能的自己利用免费的ctp接口聚合来得好,新浪的可以作为一个数据备份应急手段,如果自己的日内聚合停了,可以做免费的数据补充。毕竟网页都是有延时的,而且,如果有一天新浪突然又改变了数据请求结构,那你又不在电脑前,如果大面积数据依靠的是新浪,那到时候岂不是gg?
如果大家最新价数据愿意用爬虫拉的话,最好再在项目里做一个应急数据备用,我的话本地也有,就是懒得频繁连接数据库了,我是准备如果新浪有天突然拉不到了,我就去访问本地聚合好的最新价,或者腾讯的接口大家也可以依法炮制,我要是有空我也可以写一个。
历史数据推荐使用米匡的3000一年的包,他里面有一个current_minute很好用,比起万德这种动辄几十万的鸡肋要实惠多了。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











