




 本文介绍了如何在HTML页面中使用XPath进行元素定位,包括路径定位、元素属性定位、属性与逻辑结合定位以及属性与层级结合定位。XPath作为一种在XML文档中查找信息的语言,同样适用于HTML。文中通过实例详细解释了各种定位方法的表达式和应用场景。
本文介绍了如何在HTML页面中使用XPath进行元素定位,包括路径定位、元素属性定位、属性与逻辑结合定位以及属性与层级结合定位。XPath作为一种在XML文档中查找信息的语言,同样适用于HTML。文中通过实例详细解释了各种定位方法的表达式和应用场景。
一、元素定位——xpath、css
在页面中,一些元素无法通过id、nam、classname…定位,需要借助Xpath和css
1.Xpath
- Xpath是XML path的简称,在XML文档中查找元素信息的语言
- XML:是一种标记语言,用于数据的存储和传递,.xml的后缀
- XML和HTML的联系?html是特殊的xml,xpath也可以在html中使用
1.1 Xpath定位
1.1.1 路径定位
Xpath表达式:
find_element_by_xpath(xpath)
- 绝对路径(一般不推荐使用)
表达式时以/html开头,元素层级用 / 隔开,相同层级的元素可以使用下标,且下标从 [1] 开始。 - 相对路径:(可以匹配任意层级元素)
表达式以 // tag_name 或者 //* 开头,可以使用下标
栗子:
则相对路径表达式://form/p/input
一定是唯一的
1.1.2 元素属性定位
表达式:
//*[@attribute = 'value']
# attribute表示的是元素的属性名,value代表对应的值,只要是元素里面的属性都可以用来定位
- //* 或者 //tag_name
栗子:使用的属性最好能是唯一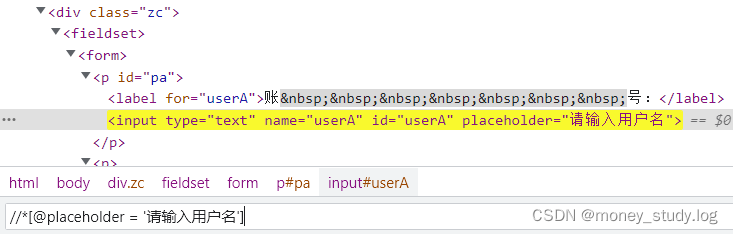
1.2.3 属性与逻辑结合定位
若是这样一组数,可以使用属性来定位吗?答案是不可以的。
[a = 'a', b = 'b'] 1
[c = 'c', a = 'a'] 2
[b = 'b', c = 'c'] 3
表达式:
//*[@attribute1='value1' and @attribute2='value2']
- //* 或者 //tag_name开头
栗子:
同时满足两个条件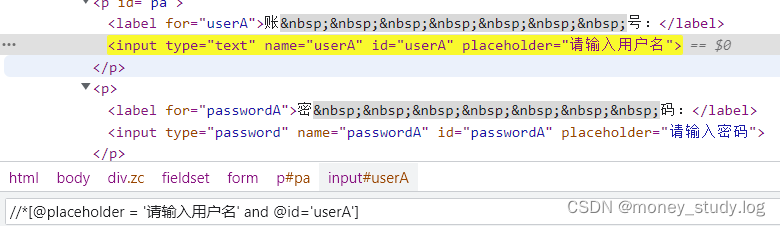
1.2.4 属性与层级结合定位
- //* 或者 //tag_name开头
栗子:
在任意层级都可以使用属性、和逻辑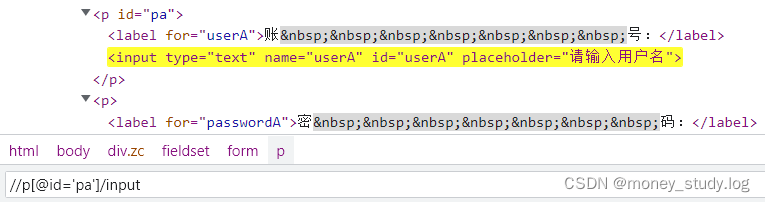
1.2.5 Xpath扩展
//*[text()="xxx"] 文本内容是xxx的元素
//*[contains(@attribute,'value')] 属性值包含value的字符串
//*[starts-with(@attribute,'value')] 属性以value开头的字符串
栗子1:
注意是双引号!!!
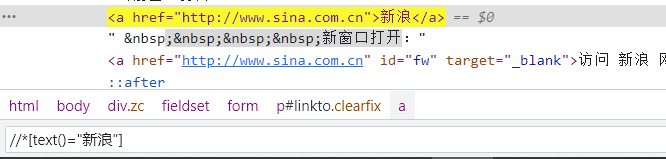
栗子2:

栗子3:

注意:xpath定位class属性,有多个值需要全部带上

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









