






原文链接:http://arxiv.org/abs/2312.10160
源码链接:https://khuangaf.github.io/CHOCOLATE/
Abstract
研究对象:图表
研究问题:图表摘要生成中存在的事实性错误问题
研究方法:建立了图表摘要事实性纠错的任务,并引入了 CHARTVE,这是一种视觉蕴涵模型(基于视觉信息的推理模型,用于理解图像并进行推理),在评估摘要事实性方面优于当前的 LVLM。此外,我们提出了 C2TFEC,这是一个可解释的两阶段框架,擅长纠正事实错误。这项工作开辟了图表摘要事实纠错的新领域,提出了一种新的评估指标,并展示了一种确保生成图表摘要真实性的有效方法。
1 Introduction
LVLMs在为图片、视频、图表等视觉内容生成自然语言描述方面展现出巨大潜力。图表摘要对于图表数据分析与理解至关重要,然而之前没有工作专门研究图表摘要的事实正确性。
为了更好的了解图表摘要的事实性错误,我们对这些错误进行分类。为了完成错误分类,我们进行了大规模的人工注释研究,对各种模型生成的摘要中存在的各种错误类型进行分析,例如值错误、标签错误等,涵盖的模型如图1所示,既包含了图表任务特定模型也包含了通用LVLMs。然后我们根据模型的架构与规模,将带注释的样本分为三类,LVLM、LLM、FT(微调视觉语言模型),这些注释构成一个命名为CHOCOLATE的数据集。
(这个数据集应该是用各类模型生成的摘要以及后期人工对这些摘要进行注释来构成的,人工注释需要标注每个犯了事实性错误的摘要具体属于哪一种错误)

我们的目标是回答三个研究问题:
(1)SOTA的图表摘要生成模型是否能够生成正确的摘要?
答案是否定的,有超过80%的摘要都是事实性错误的,即使是GPT4也会产生超过40%的错误。
(2)如何自动评估图表和摘要之间的事实一致性?
我们提出CHARTVE模型来解决这个问题,该模型使用一种新颖的视觉蕴涵方法来评估图表摘要的事实一致性。它通过重新利用图表摘要和图表问答中的现有资源进行训练。结果表明,CHARTVE 的性能与专有 LVLM 相当,优于最先进的开源 LVLM,并且其大小小了 64 倍。
(3)如何有效纠正图表摘要中的事实错误?
我们提出了C2TFEC,这是一个可解释的两步框架,可将视觉推理分解为图像到结构的渲染和基于文本的推理。C2TFEC 首先将输入图表转换为结构化数据表表示形式。以这些提取的表格数据为基础,第二个组件通过可解释的推理过程识别并修复生成的摘要中的事实性错误。我们的实验表明,与端到端方法相比,这种显式分解可以实现更可靠的事实性更正。中间结果表示充当图表和摘要之间的桥梁,使 C2TFEC 能够优于包括 GPT-4V 在内的基线。
总的来说,我们的贡献如下:
- 我们使用一种新的错误类型分类对各种规模的模型产生的摘要中的事实错误进行了人工标注,从而得到了 CHOCOLATE 数据集。
- 我们引入了图表摘要事实纠错任务,该任务要求模型纠正生成的图表摘要中的事实错误。
- 我们提出了 CHARTVE,这是一种基于视觉蕴涵的无参考评估指标,与 LVLM 相比,它更贴近人类评估。
- 我们提出了 C2TFEC,这是一种可解释的两阶段纠错框架,其性能优于所有现有的 LVLM。
2 Analyzing Factual Errors
为了了解现有模型从图表中总结关键信息的能力,我们对 VisText (Tang et al., 2023a) 和 Pew (Kantharaj et al., 2022) 数据集上的六个最先进的图表摘要模型进行了分析。为了促进此过程,我们引入了各种错误类型,2.1会介绍。
2.1 Error Typology
Value Error 图表中的定量数据值在摘要中表示不正确。这包括表示轴、百分比或其他数值数据点上的值的数字。
Label Error 图表中的非数字标签、类别或文本元素在摘要中被错误引用。这包括轴上的标签、图例项、分类变量等。
Trend Error 摘要中错误地描述了随时间变化的总体趋势或组间比较,例如在实际减少的情况下陈述了增加的趋势。(描述整体变化趋势)
Magnitude Error 为趋势描述的差异程度或数量与图表不符,例如,当图表显示它实际上是“平滑的”时,却表示增加“急剧”。(描述趋势变化的程度)
Out-of-context Error 概念、变量或摘要中引入的某个信息在图表内容中根本不存在。摘要包含不以实际图表内容为基础的事实陈述。
Nonsense Error 摘要包含不完整的句子、不连贯且不合逻辑的短语,或者根本没有连贯意义的单词序列。
Grammatical Error 摘要的结构或语法存在错误。
2.2 Captioning Model Analysis
基线模型选择方面:
(1)FT:选择了ChartT5、MatCha、UniChart,在Pew和VisText数据集上进行微调。
(2)LLM-based:选择了Deplot+GPT4
(3)LVLM:GPT-4V和Bard
对于上述每个模型,我们都从每个数据集中随机抽样100个图表来生成摘要,然后计算每个模型在不同数据集上生成的摘要的事实性错误百分比,以及不同类别错误的细分。错误率是在句子级别而不是整个摘要级别计算的,因为不同的模型会生成不同长度的摘要。句子级别的评估有助于更公平的比较。
从图1中能够发现,首先,SOTA的FT模型基本无法生成事实一致性的摘要,有82.06的摘要包含至少一个事实性错误,即使是GPT-4V和Bard这类LVLM也会有81.27%的摘要存在错误。这些都说明了图表摘要任务的难度以及语言模型的局限。

其次,特定于图表摘要任务的模型和 LVLM 在两个数据集上显示出相反的趋势。特定于任务的模型(包括 ChartT5、MatCha 和 UniChart)在 VisText 数据集上产生的错误较少。相反,包括 GPT-4V 和 Bard 在内的 LVLM 在 Pew 数据集上产生的错误要少得多。这些数据集的主要区别有两个:(1) Pew 的图表普遍存在标记值,以及 (2) VisText 中的图表结构更简单。我们猜测 LVLM 可能更擅长利用标记好的数值,而特定于任务的模型则擅长通过坐标轴推导出数据值。
第三,LVLM 无法全方面优于特定于任务的微调模型。尽管 LVLM 具有广泛的训练数据和参数,但具有适当预训练目标和架构的任务特定模型可能会超越 LVLM。
分析生成的数据集名为 CHOCOLATE (Captions Have Many ChOsen Lies About The Evidence),其中每个实例都包含一个图表、一个生成的图表摘要和由人工注释标记的错误类型。有些类型模型产生的事实错误可能更容易识别,有些则可能更难识别,所以我们将 CHOCOLATE 分为三个部分:LVLM 类别,有来自 GPT-4V 和 Bard 的摘要;LLM 类别,具有 DePlot + GPT-4 生成的摘要;以及 FT 类别,用于 ChartT5、UniChart 和 MatCha 摘要。
2.3 Dataset Quality
数据集中有5323个句子,我们采用Fleiss’ Kappa κ 和人为投票作为评判标准,证明了我们数据集是可靠的。
3 The Chart Caption Factual Error Correction Task
3.1 Task Definition
我们任务的输入是图表 和图表摘要 C。图表摘要事实性错误更正的目标是以最少的编辑量生成更正后的标题 Cˆ。如果 C 已经事实性一致,则模型应输出原始标题(即 Cˆ = C)。继先前关于基于文本的事实错误纠正工作(Thorne 和 Vlachos,2021 年;Huang et al., 2023b;Gao et al., 2023),应使用尽可能少的替换、插入和删除操作进行更正,因为通过删除标题中的所有单词,可以轻松实现 0% 的非事实率。
3.2 Reference-free Evaluation With Chart Visual Entailment
没有确定的指标来评估图表和相应图表摘要之间的事实一致性。此外,由于我们的数据集不包含带注释的参考摘要,因此无法采用基于文本的指标。作为解决方案,我们提出了 CHARTVE,这是一种基于图表视觉蕴涵的无参考评估指标。
CHARTVE Overview 我们将不一致检测问题表述为图表可视化蕴涵任务。给定一个图表摘要句子 c 和一个图表 ,任务是预测从
到 c 的关系是 ENTAILMENT(事实一致)还是 NOTENTAILMENT(事实不一致)。这项任务学习视觉蕴涵模型的主要挑战是缺乏数据。为了克服这一挑战,我们对来自相关任务(例如图表 QA)的数据稍加修饰用作正样本。然后,我们提出了一种以表格为导向生成的负数据来作为负样本。
正样本生成 利用两个图表问答的数据集:ChartQA和PlotQA,然后使用QA2Claim模型(Zero-shot faithful factual error correction),将问答对转换成声明性语句,并将它们与原本的图表配对形成正样本。此外,来自VisText和Chart-to-Text数据集的摘要也被用作正样本。
表格引导的负样本生成 生成负样本是通过扰乱基于图表的底层数据表的正实例来实现的。对于图表 Ei 及其基础数据表 AEi,我们在 AEi 中查找与正样本摘要 c+ i 中的子字符串匹配的值。找到匹配项后,标题中的子字符串将替换为与 AEi 中同一列不同的值,从而产生一个值或标签错误注入的负句子 c− i ,在保持相关性的同时确保与 Ei 不一致。对于与趋势相关的错误,我们将 c+ i 中的趋势术语替换为它们的对立面,利用 “increase” 和 “decrease ”等术语的特定词典,从而创建趋势矛盾的陈述。此外,通过将 Ei 与另一个图表中不匹配的标题 c+ j 配对(其中 i ≠ j)来制作断章取义的错误。这将模拟填充了不相关数据的字幕。
Learning CHARTVE 我们选择 UniChart 作为基线,由于Unichart在CQA任务上进行了预训练,所以我们将以问答形式来学习CHARTVE。具体做法是设定一个模板:
Does the image entail this statement: “SENTENCE”?
其中SENTENCE替换成图表摘要的句子c,以模板t和图表作为输入,如果图表中包含摘要句子c,则Unichart返回“yes”。在推理期间,我们使用相同的输入格式并探测对应于 “yes” (l_yes) 和 “no” (l_no) 解码器的 logits。之后,我们应用 softmax 函数将这些 logits 转换为范围从 0 到 1 的蕴涵分数 s(E, c):
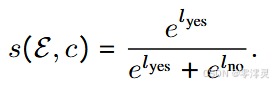
(第一个公式计算的是模型预测句子c与图表事实性一致的概率)
我们计算摘要中所有句子的蕴涵分数的最小值,用 S(E, C) 表示,其中 C 表示图表 E 的所有摘要句子的集合:
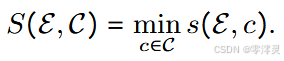
(第二个公式计算的是模型预测摘要C与图表事实性一致的概率,原理是取摘要C的所有句子c中事实性一致概率的最小值作为摘要C的概率,也就是说只要摘要C中有一个句子c的事实性一致概率低,就会导致整个摘要的事实性一致概率低)
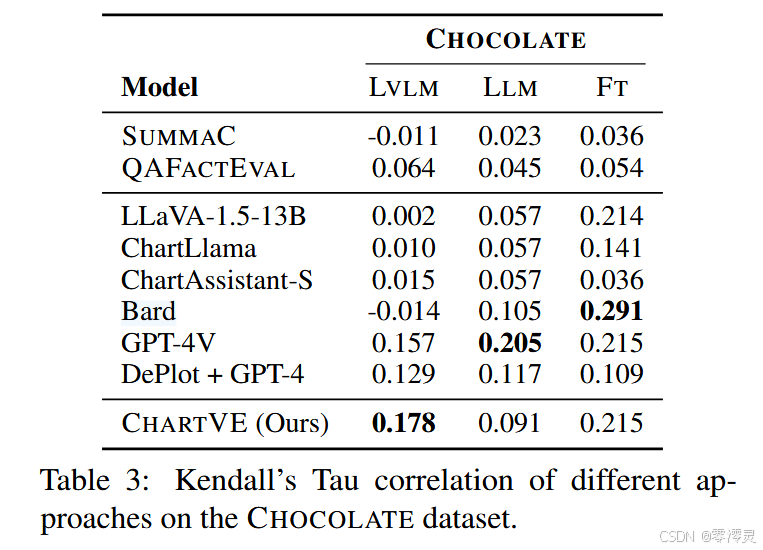
Meta-evaluation of Different Evaluation Metrics 为了评估不同方法在评估 CHOCOLATE 数据集方面的有效性,我们采用 Kendall 的 Tau(A new measure of rank correlation)来计算这些方法与人类判断之间的相关性。鉴于之前缺乏图表标题的事实不一致检测方法的工作,我们将 CHARTVE 与支持零镜头的方法进行了比较,包括 DePlot + GPT-4、Bard、GPT-4V 和领先的开源 LVLMs,LLaVA-1.5-13B(Liu et al., 2023c)、ChartLlama(Han et al., 2023)和 ChartAssistant-S(Meng et al., 2024)。基于文本的事实性指标 SUMMAC (Laban et al., 2022) 和 QAFACTEVAL (Fabbri et al., 2022b) 也包括在内,用于计算参考摘要和生成的摘要之间的事实一致性。
结果如表3所示,总体而言,各个指标对FT类别摘要的判断与人类判断最为接近,对LVLM类别的判断与人类判断差别最大。这种趋势符合预期:FT 标题中充斥着更明显的错误,例如断章取义和无意义的错误,而源自 LVLM 的错误更难检测,因为它们通常需要对数据点相对于轴的位置进行复杂的推断。同时结果还表明了我们的CHARTVE在LVLM类别是表现最为出色,但是在LLM类别上表现不佳,这可能是由于token分布的变化,因为 DePlot + GPT-4 偶尔会使用 CHARTVE 训练数据中不存在的以表为中心的术语(例如,“列”和“条目”)。
4 Methodology
为了纠正生成的摘要中的事实错误,我们提出了 C2TFEC,这是一个两步可解释的框架,如图 2 所示。C2TFEC 首先将输入图表转换为数据表,然后使用表格数据纠正摘要中的错误。该框架的思路来自我们对 “DePlot + GPT-4” 的分析,分析表明,摘要生成中很大一部分错误源于 DePlot 组件。为了缓解这种情况,我们基于 UniChart 开发了一个更强大的图表到表格模型,并通过广泛的微调数据集进行了显著改进。C2TFEC 的优势在于它能够利用 GPT-4 的推理优势来纠正错误,提高摘要的真实性。
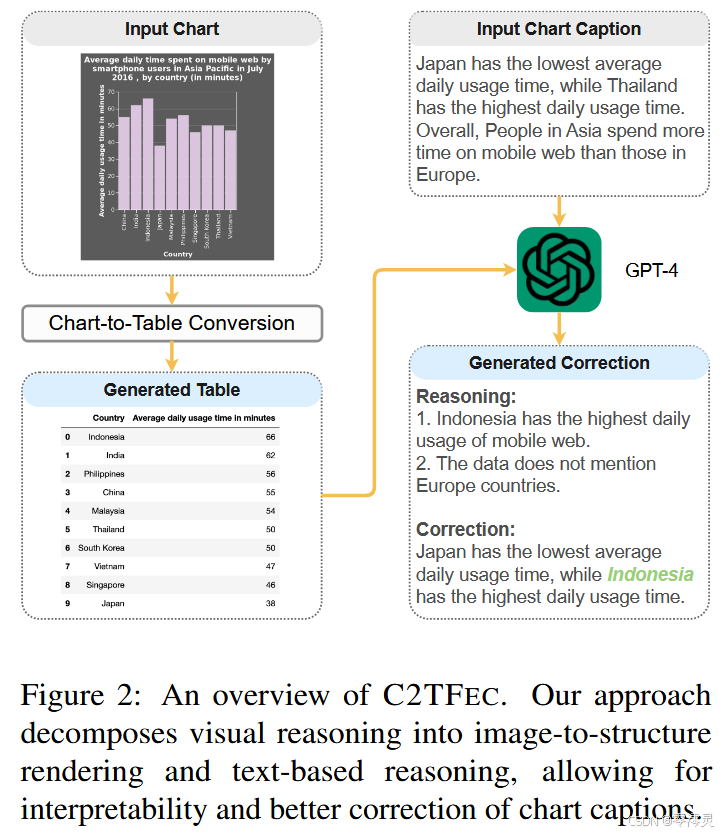
4.1 Chart-To-Table Conversion
我们的图表到表格模型的训练数据来自包括 VisText、Chart-toText、ChartQA 和 PlotQA 在内的数据集,我们在其中重新利用原始图表和基础数据表进行模型的训练。我们总共收集了 65K 个实例,train:dev:test 拆分为 61:2:2。与 DePlot (Liu et al., 2023a) 类似,我们的模型也被训练为生成图表标题,增强了其将表格形式表示的数据置于上下文中的能力。设 M 表示我们提出的模型。对于给定的图表图 E,模型自回归生成一个图表摘要 T 和相应的表 A(即 T , A = M(E))。
4.2 Table-based Error Rectification
随着输入图表转换为结构化表格数据,第二阶段使用 LLM 的推理能力来解决摘要C 和生成的表 A 之间的事实不一致。在这里,我们使用 GPT-4 作为 LLM。GPT-4 首先根据输入的表格内容以及摘要C来reasoning摘要中存在的事实性错误。然后,它根据reasoning生成更正后的标题 Cˆ。这个过程使用户能够验证每次更正背后的原因。C2TFEC 将事实验证与语言生成分开,利用了为各自领域量身定制的独立视觉和语言模型的互补优势。线性表形式充当桥梁,以增强和验证图表标题中的事实一致性。
5 Experimental Settings
Datasets CHOCOLATE dataset 包含1187图表-摘要对,分成LVLM、LLM、FT三个类别。
Baselines 由于 CHOCOLATE 不包含训练数据,我们将 C2TFEC 与支持zero-shot的 LVLM 和 LLM 进行比较,包括 LVLM、LLaVA-1.5-13B、GPT-4V、Bard 以及 DePlot + GPT-4。为了更公平地比较我们的方法和 DePlot,我们使用 VisText 的额外微调 DePlot,这种方法已被证明可以有效地使模型适应看不见的领域(Huang et al., 2023b)。我们将此模型表示为 DePlotCFT。
Evaluation Metrics 根据我们在 §3.2 中的实验结果,我们使用 CHARTVE、GPT-4V 和 Bard 评估不同类别的更正后的摘要和输入图表之间的事实一致性。此外,由于应使用尽可能少的编辑次数完成摘要校正,因此我们使用 Levenshtein 距离来测量编辑次数。
6 Results
6.1 Main Results
实验结果表明,C2TFEC(Correcting Factual Errors in Chart Captions)模型在LVLM(大型视觉语言模型)和FT(特定任务微调模型)数据集上实现了最佳的事实一致性性能,并在LLM(大型语言模型)数据集上排名第二。这表明,首先将图表转换为结构化数据表,然后使用表格-标题对齐来纠正事实不一致的两步过程是一种有效的策略。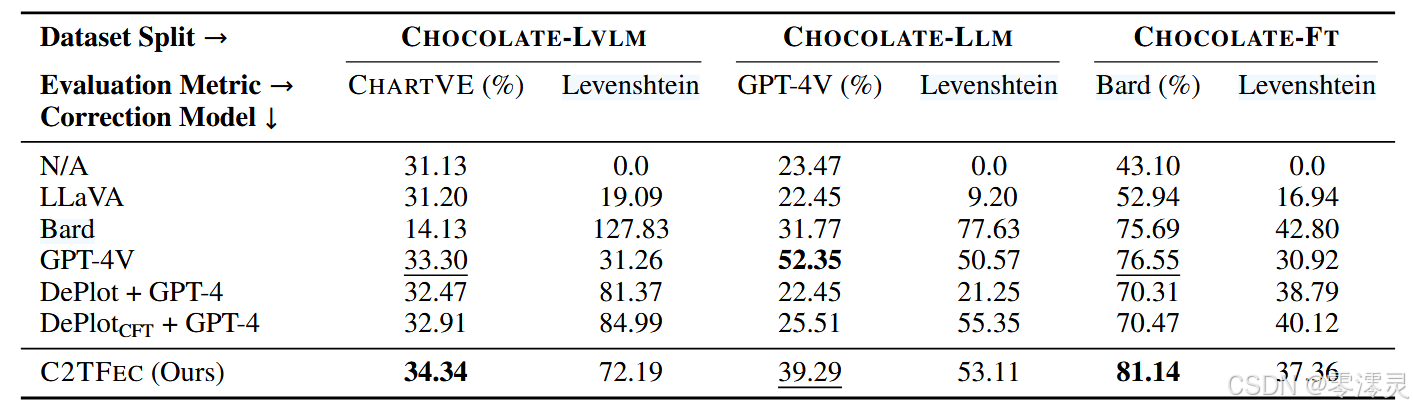
6.2 Human Evaluation
C2TFEC 在多个误差类别中都有提升,尤其是值误差大幅减少,并几乎消除了趋势误差。
8 Conclusion
我们的研究揭示了各种图表标题模型生成的图表标题中普遍存在的事实错误问题,并引入了 CHOCOLATE 来仔细检查这些错误。我们建立了图表字幕事实纠错任务,以推动创建值得信赖的摘要系统,并提出 CHARTVE,这是一种在反映人工对字幕事实的评估方面超越 LVLM 的评估模型。我们的两阶段更正框架 C2TFEC 通过将视觉数据转换为结构化表格以实现更忠实的纠错,提供了一种可解释的方法来提高字幕真实性。我们的工作标志着确保图表标题可验证和可信的重要一步。未来的方向包括将我们的方法扩展到图表以外的多模态上下文,开发更复杂的错误检测和纠正算法,以及创建涵盖更广泛视觉内容的数据集。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









