






正在更新ing
一、创建conda环境
conda env create -f environment.yml
conda activate LineEX其中requirements.yaml文件结构如下:
name:#环境名称
channels:
- conda-forge
- #镜像源
dependencies:
- #python环境中的依赖项列表
- backcall=0.2.0=pyh9f0ad1d_0 #表示backcall库的版本号0.2.0, 是从pyh9f0ad1d_0渠道安装的
- pip:
- #各种pip包
prefix: root/miniconda2/envs/LineEX #conda创建的环境所在的文件夹路径,此处需要修改(1)报错1:pycocotools安装失败
Building wheel for pycocotools (setup.py) ... error
ERROR: Command errored out with exit status 1:
command: /lustre/home/chyxie/miniconda2/bin/python -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/tmp/pip-install-nC_hVs/pycocotools/setup.py'"'"'; __file__='"'"'/tmp/pip-install-nC_hVs/pycocotools/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' bdist_wheel -d /tmp/pip-wheel-bmNmoY --python-tag cp27
cwd: /tmp/pip-install-nC_hVs/pycocotools/
Complete output (29 lines):
running bdist_wheel
running build
running build_py
creating build
creating build/lib.linux-x86_64-2.7
creating build/lib.linux-x86_64-2.7/pycocotools
copying pycocotools/__init__.py -> build/lib.linux-x86_64-2.7/pycocotools
copying pycocotools/coco.py -> build/lib.linux-x86_64-2.7/pycocotools
copying pycocotools/cocoeval.py -> build/lib.linux-x86_64-2.7/pycocotools
copying pycocotools/mask.py -> build/lib.linux-x86_64-2.7/pycocotools
running build_ext
Compiling pycocotools/_mask.pyx because it changed.
[1/1] Cythonizing pycocotools/_mask.pyx
/tmp/pip-install-nC_hVs/pycocotools/.eggs/Cython-3.0.10-py2.7.egg/Cython/Compiler/Main.py:381: FutureWarning: Cython directive 'language_level' not set, using '3str' for now (Py3). This has changed from earlier releases! File: /tmp/pip-install-nC_hVs/pycocotools/pycocotools/_mask.pyx
tree = Parsing.p_module(s, pxd, full_module_name)
building 'pycocotools._mask' extension
creating build/temp.linux-x86_64-2.7
creating build/temp.linux-x86_64-2.7/pycocotools
creating build/temp.linux-x86_64-2.7/common
creating build/common
gcc -pthread -B /lustre/home/chyxie/miniconda2/compiler_compat -Wl,--sysroot=/ -fno-strict-aliasing -g -O2 -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC -I/tmp/pip-install-nC_hVs/pycocotools/.eggs/numpy-1.16.6-py2.7-linux-x86_64.egg/numpy/core/include -I./common -I/lustre/home/chyxie/miniconda2/include/python2.7 -c pycocotools/_mask.c -o build/temp.linux-x86_64-2.7/pycocotools/_mask.o -Wno-cpp -Wno-unused-function -std=c99
gcc -pthread -B /lustre/home/chyxie/miniconda2/compiler_compat -Wl,--sysroot=/ -fno-strict-aliasing -g -O2 -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC -I/tmp/pip-install-nC_hVs/pycocotools/.eggs/numpy-1.16.6-py2.7-linux-x86_64.egg/numpy/core/include -I./common -I/lustre/home/chyxie/miniconda2/include/python2.7 -c ./common/maskApi.c -o build/temp.linux-x86_64-2.7/./common/maskApi.o -Wno-cpp -Wno-unused-function -std=c99
./common/maskApi.c: In function ‘rleToBbox’:
./common/maskApi.c:135:32: warning: unused variable ‘xp’ [-Wunused-variable]
uint h, w, xs, ys, xe, ye, xp, cc; siz j, m;
^
gcc -pthread -B /lustre/home/chyxie/miniconda2/compiler_compat -Wl,--sysroot=/ -fno-strict-aliasing -g -O2 -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC -I/tmp/pip-install-nC_hVs/pycocotools/.eggs/numpy-1.16.6-py2.7-linux-x86_64.egg/numpy/core/include -I./common -I/lustre/home/chyxie/miniconda2/include/python2.7 -c ../common/maskApi.c -o build/temp.linux-x86_64-2.7/../common/maskApi.o -Wno-cpp -Wno-unused-function -std=c99
gcc: error: ../common/maskApi.c: No such file or directory
error: command 'gcc' failed with exit status 1经检查,虚拟环境中的python版本并没有按照配置文件中的设置安装3.8.12版本,而是安装了默认的2.7版本。
所以重新安装python3.8,然后执行:pip install pycocotools
二、关键点检测模块
KP_detection
--modules
--__init__.py
--position_encoding.py
--transformer.py
--transformer_vit.py
--my_model.py
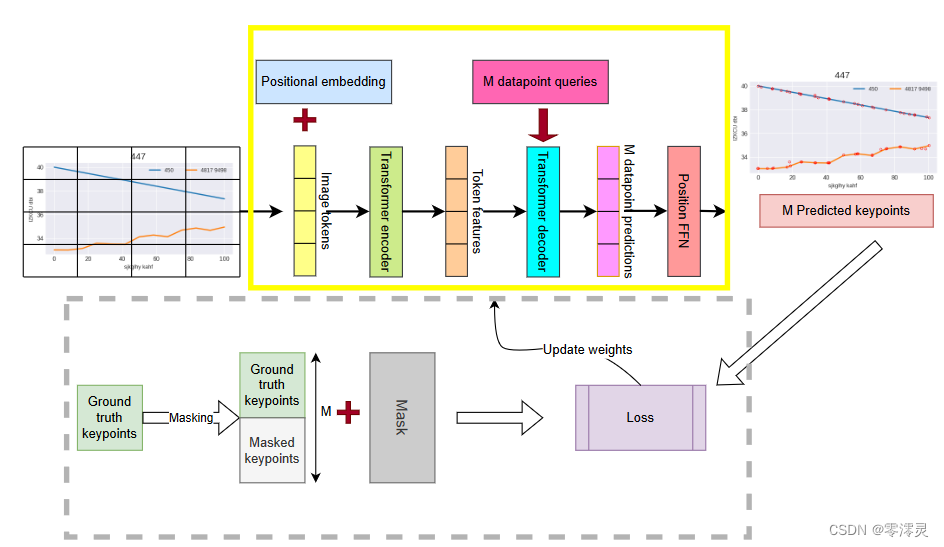
1、__init__.py文件
作用是将文件夹变为一个Python模块,python项目的每个文件夹内都应该有一个__init__.py文件,否则跨文件导入函数时会报错。 __init__.py可以为空,此时只起到声明作用。
具体参考文章:Python __init__.py 作用详解 - Data&Truth - 博客园 (cnblogs.com)
2、position_encoding.py
(1)绝对位置嵌入
生成一个位置矩阵,在训练过程中不改变矩阵值。
与处理文本时的位置嵌入类似,都采用三角函数:
不同之处在于,文本的位置是一维的,而图像中像素的位置是二维的,所以需要分别对坐标x和坐标y进行位置嵌入,然后拼接结果。代码如下:
def positon_encoding(batch_size, H, W, pos_dim):
"""
b: batch size
(H, W): 图像大小
pos_dim: 位置向量的维度
最终得到的绝对位置嵌入矩阵维度为:(b, H, W, pos_dim*2)
"""
pos_index = torch.ones(batch_size, H, W)
y_embed = torch.cumsum(pos_index, dim=1, dtype=torch.float32) # (batch_size, H, W)
x_embed = torch.cumsum(pos_index, dim=2, dtype=torch.float32) # (batch_size, H, W)
dim_t = torch.arange(pos_dim)
dim_t = 10000**(2*(dim_t//2)/pos_dim)
x_embed = x_embed[:, :, :, None] / dim_t # (batch_size, H, W, pos_dim)
y_embed = y_embed[:, :, :, None] / dim_t # (batch_size, H, W, pos_dim)
# stack()函数用于将list或tuple中的多个张量沿着维度dim进行堆叠,例如两个(3,3)维度的张量在dim=1上堆叠,就得到一个(3,2,3)的张量
# flatten(dim)的作用是保留dim之前的维度,将dim之后的维度展开至dim维度上,例如(3,2,3).flatten(1) -> (3,6)
pos_x = torch.stack((x_embed[:, :, :, 0::2].sin(), y_embed[:, :, :, 1::2].cos()), dim=4).flatten(3) # (batch_size, H, W, pos_dim)
pos_y = torch.stack((y_embed[:, :, :, 0::2].sin(), y_embed[:, :, :, 1::2].cos()), dim=4).flatten(3) # (batch_size, H, W, pos_dim)
pos = torch.cat((pos_x, pos_y), dim=3).permute(0,3,1,2) # (batch_size, pos_dim*2, H, W)
return pos(2)可学习位置嵌入
使用nn.init.uniform_()方法初始化位置嵌入矩阵,然后在训练过程中会不断更新位置嵌入矩阵的值。
def position_encoding(batch_size = 32, H = 5, W = 6, num_pos_feats = 256):
row_embed = nn.Embedding(50, num_pos_feats)
col_embed = nn.Embedding(50, num_pos_feats)
# 初始化Embedding层参数
nn.init.uniform_(row_embed.weight)
nn.init.uniform_(col_embed.weight)
x = torch.arange(W)
y = torch.arange(H)
# 通过Embedding生成初始化的位置嵌入矩阵
pos_x = row_embed(x) # (W, num_pos_feats)
pos_y = col_embed(y) # (H, num_pos_feats)
# 复制至维度统一为(H, W, num_pos_feats)
pos = torch.cat((pos_x.unsqueeze(0).repeat(H, 1, 1), pos_y.unsqueeze(1).repeat(1,W,1)), dim = 2) # (H, W, num_pos_feats*2)
# 复制batch_size份
pos = pos.permute(2,0,1).unsqueeze(0).repeat(batch_size, 1, 1, 1) # # (batch_size, num_pos_feats*2, H, W)
return pos综合上述两种方法,整合代码如下:
import torch
import math
from torch import nn
class PositionEmbeddingSine(nn.Module):
"""
使用三角函数实现绝对位置嵌入
与处理文本时不同,因为图像中像素点的位置由二维坐标决定
"""
def __init__(self, num_pos_feats = 64, temperature=10000, normalize=False, scale=None) -> None:
super().__init__()
"""
num_num_pos_featss: 位置特征向量的维度
temperature: 位置嵌入计算公式中的参数,通常是10000
normalize: 是否需要对位置序号归一化
scale: 限制角度的取值范围
"""
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2*math.pi
self.scale = scale
def forward(self, batch_size, H, W, device):
"""
(H, W): 图像大小
最终得到的绝对位置嵌入矩阵维度为:(batch_size, H, W, num_pos_feats*2)
"""
pos_index = torch.ones(batch_size, H, W)
y_embed = torch.cumsum(pos_index, dim=1, dtype=torch.float32) # (batch_size, H, W)
x_embed = torch.cumsum(pos_index, dim=2, dtype=torch.float32) # (batch_size, H, W)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=device)
dim_t = self.temperature**(2*(dim_t//2)/self.num_pos_feats)
x_embed = x_embed[:, :, :, None] / dim_t # (batch_size, H, W, num_pos_feats)
y_embed = y_embed[:, :, :, None] / dim_t # (batch_size, H, W, num_pos_feats)
# stack()函数用于将list或tuple中的多个张量沿着维度dim进行堆叠,例如两个(3,3)维度的张量在dim=1上堆叠,就得到一个(3,2,3)的张量
# flatten(dim)的作用是保留dim之前的维度,将dim之后的维度展开至dim维度上,例如(3,2,3).flatten(1) -> (3,6)
pos_x = torch.stack((x_embed[:, :, :, 0::2].sin(), y_embed[:, :, :, 1::2].cos()), dim=4).flatten(3) # (batch_size, H, W, num_pos_feats)
pos_y = torch.stack((y_embed[:, :, :, 0::2].sin(), y_embed[:, :, :, 1::2].cos()), dim=4).flatten(3) # (batch_size, H, W, num_pos_feats)
pos = torch.cat((pos_x, pos_y), dim=3).permute(0,3,1,2) # (batch_size, num_pos_feats*2, H, W)
return pos
class PositionEmbeddingLearned(nn.Module):
def __init__(self, num_pos_feats = 256) -> None:
super().__init__()
self.num_pos_feats = num_pos_feats
self.row_embed = nn.Embedding(50, num_pos_feats)
self.col_embed = nn.Embedding(50, num_pos_feats)
# Embedding权重初始化
nn.init.uniform_(self.row_embed.weight)
nn.init.uniform_(self.col_embed.weight)
def forward(self, batch_size, H, W):
x = torch.arange(W)
y = torch.arange(H)
x_embed = self.row_embed(x) # (W, num_pos_feats)
y_embed = self.col_embed(y) # (H, num_pos_feats)
x_embed = x_embed.unsqueeze(0).repeat(H, 1, 1) # (H, W, num_pos_feats)
y_embed = y_embed.unsqueeze(1).repeat(1, W, 1) # (H, W, num_pos_feats)
pos = torch.cat((x_embed, y_embed), dim=-1) # (H, W, num_pos_feats * 2)
pos = pos.permute(2,0,1).unsqueeze(0).repeat(batch_size, 1, 1, 1) # (batch_size, num_pos_feats*2, H, W)
return pos
def build_position_encoding(d_model, version):
if version in ['v2', 'sine']:
pos = PositionEmbeddingSine(d_model//2, normalize=True)
elif version in ['v3', 'learned']:
pos = PositionEmbeddingLearned(d_model//2)
else:
raise ValueError("There is not a version:{}".format(version))
return pos3、transformer.py
基础的transformer模型
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
"""
DETR Transformer class.
Copy-paste from torch.nn.Transformer with modifications:
* positional encodings are passed in MHattention
* extra LN at the end of encoder is removed
* decoder returns a stack of activations from all decoding layers
"""
class Transformer(nn.Module):
def __init__(self, vit_dim=512, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self.lin_proj_src = nn.Linear(vit_dim, d_model)
self.lin_proj_mem = nn.Linear(vit_dim, d_model)
self.lin_proj_pos = nn.Linear(vit_dim, d_model)
self.proj_mem_dropout = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten BxCxHxW to HWxBxC
# bs, c, h, w = src.shape
# src = src.flatten(2).permute(2, 0, 1)
# pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
bs = src.shape[0]
# B, N, C to N, B, C
src = src.permute(1, 0, 2)
pos_embed = self.lin_proj_pos(pos_embed.permute(1, 0, 2))
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)
if mask is not None:
mask = mask.flatten(1)
tgt = torch.zeros_like(query_embed)
memory = self.encoder(self.lin_proj_src(src), src_key_padding_mask=mask, pos=pos_embed)
memory = memory + self.lin_proj_mem(self.proj_mem_dropout(src))
memory = self.norm1(memory)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
# return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
return hs.transpose(1, 2), memory.permute(1, 2, 0)
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
def _get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
def build_transformer(args):
return Transformer(
vit_dim=args.vit_dim,
d_model=args.hidden_dim,
dropout=args.dropout,
nhead=args.nheads,
dim_feedforward=args.dim_feedforward,
num_encoder_layers=args.enc_layers,
num_decoder_layers=args.dec_layers,
normalize_before=args.pre_norm,
return_intermediate_dec=True,
)
def _get_activation_fn(activation):
"""Return an activation function given a string"""
if activation == "relu":
return F.relu
if activation == "gelu":
return F.gelu
if activation == "glu":
return F.glu
raise RuntimeError(F"activation should be relu/gelu, not {activation}.")
4、transformer_vit.py
构建TransformerVit(Vision Transformer)模型
(1)与transformer比较
相同点:都采用encoder-decoder结构,引入self-attention机制,需要位置嵌入。
不同点:处理对象不是序列,而是图像。首先会将图像数据转换成一系列图像块(patch),然后对patch进行位置嵌入。
(2)模型架构
encoder:使用timm.models的create_model方法来构建。
decoder:使用传统transformer的TransformerDecoder模块。
pos_embedding:需要指定pos_embed_version,‘sine’代表绝对位置嵌入,‘learned’代表可学习位置嵌入。
class TransformerVit(nn.Module):
def __init__(self, encoder, decoder, vit_dim=512, d_model=512, nhead=8, pos_embed_version='sine'):
"""
vit_dim: Output token dimension of the VIT
d_model: 中间层维度
pos_embed_version: 表示采用的位置嵌入方法
"""
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.lin_proj_mem = nn.Linear(vit_dim, d_model, bias=False)
self.vit_norm = nn.LayerNorm(d_model)
num_patches = math.prod(self.encoder.dim_patches)
self.pos_embed_version = pos_embed_version
# 选定位置嵌入方法
if pos_embed_version in ['learned', "sine"]:
self.pos_encoder = build_position_encoding(d_model=d_model, version=self.pos_embed_version)
elif pos_embed_version == "none":
self.pos_encoder = None
else:
raise ValueError("No support version:{}".format(self.pos_embed_version))
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
# self可视作模型,self.named_parameters()返回(name, param)二元组,分别对应权重名称和权重值,是一种参数遍历方法
for n, p in self.named_parameters():
if p.dim() > 1 and "encoder" not in n:
# 进行xavier初始化,其目标是使每一层输出的方差相等
nn.init.xavier_uniform_(p)
def forward(self, src: torch.Tensor, query_embed, return_attn = False):
"""
src: (batch_size, 3, 224, 224)
query_embed:
"""
batch_size, c, h, w = src.shape
if type(self.encoder) == torch.nn.Sequential:
memory, attn_list = self.encoder(src) # (batch_size, c, encoder_output_size)
memory = memory.permute(0,2,1) # (batch_size, c, encoder_output_size) -> (batch_size, encoder_output_size, c)
else:
memory, attn_list = self.encoder(src, return_attn, cls_only=False)
query_embed = query_embed.unsqueeze(1).repeat(1, batch_size, 1)
# torch.zeros_like(x)返回与x维度一致的全零矩阵
tgt = torch.zeros_like(query_embed)
if self.pos_embed_version in ["learned", "sine"]:
pW, pH = self.encoder.dim_patches
pos_embed = self.pos_encoder(batch_size, pH, pW).flatten(2) # (batch_size, num_pos_feats*2, H, W) -> (batch_size, num_pos_feats*2, H*W)
pos_embed = pos_embed.permute(2, 0, 1)
memory = memory[:, 1:, :]
elif self.pos_embed_version == 'none':
pos_embed = None
memory = self.vit_norm(self.lin_proj_mem(memory)) # (batch_size, 197, 384)
memory = memory.permute(1, 0, 2) # (197, batch_size, 384)
hs = self.decoder(tgt, memory, memory_key_padding_mask=None,
pos=pos_embed, query_pos=query_embed)
return hs.transpose(1,2), memory.permute(1, 0, 2), attn_list
def build_transformer_vit(args):
patch_size = args.patch_size
encoder = create_model(
args.encoder_version,
pretrained=False,
num_classes=0,
img_size=args.input_size,
drop_rate=args.vit_dropout,
drop_block_rate=None
)
# encoder处理的图像尺寸
encoder.dim_patches = [encoder.patch_embed.img_size[0] // encoder.patch_embed.patch_size[0],
encoder.patch_embed.img_size[1] // encoder.patch_embed.patch_size[1]]
# 加载预训练参数
if args.vit_weights is not None:
if args.vit_weights.startswith('https'):
# 根据链接在线加载预训练参数
checkpoint = torch.hub.load_state_dict_from_url(
args.vit_weights, map_location='cpu', check_hash=True)
else:
# 从本地加载预训练参数
checkpoint = torch.load(args.vit_weights, map_location='cpu')
checkpoint_model = checkpoint['model']
msg = encoder.load_state_dict(checkpoint_model, strict=False)
print(f"Loaded encoder weights from {args.vit_weights}. Message: {msg}")
decoder_layer = TransformerDecoderLayer(args.hidden_dim, args.nheads, args.dim_feedforward,
args.dropout, args.activation, args.pre_norm)
decoder_norm = nn.LayerNorm(args.hidden_dim)
decoder = TransformerDecoder(decoder_layer, args.dec_layers, decoder_norm, return_intermediate=True)
return TransformerVit(encoder=encoder, decoder=decoder, vit_dim=args.vit_dim, d_model=args.hidden_dim,
nhead=args.nheads,pos_embed_version=args.position_embedding)5、my_model.py
构建最终的VITDETR模型,用于关键点检测。
# 多层感知机
class MLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers) # h = [hidden_dim, hidden_dim, ..., hidden_dim] 维度为(1,num_layers-1)
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim]+h, h+[output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
# 除最后一层外,都需要经过relu激活函数
x = F.relu(layer(x)) if i < self.num_layers-1 else layer(x)
return x
class VITDETR(nn.Module):
def __init__(self, transformer, num_queries) -> None:
super().__init__()
num_points = 2 # 关键点只有两个类别:是关键点/不是关键点; 检测bounding boxes时设置为4
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.bbox_embed = MLP(hidden_dim, hidden_dim, num_points, 3)
self.query_embed = nn.Embedding(num_queries, hidden_dim)
def forward(self, samples, return_attn = False):
"""
samples:
return_attn: 是否返回注意力权重
"""
# NestedTensor是DETR模型的一种数据结构,包含tensor和mask两个组成
# if type(samples) is NestedTensor:
# samples = samples.tensors
hs, _, attn_list = self.transformer(samples, self.query_embed.weight, return_attn)
outputs_coord = self.bbox_embed(hs).sigmood()
out = {'pred_boxes': outputs_coord[-1]}
return out
class Model(nn.Module):
def __init__(self, args):
super(Model, self).__init__()
self.args = args
transformer = build_transformer_vit(args)
self.model = VITDETR(
transformer,
args.num_queries
)
def forward(self, x, return_attn = False):
return self.model(x, return_attn)
6、utils.py
获取关键点坐标,
7、xcit.py
实现XCiT模型,该模型具体原理参考https://blog.youkuaiyun.com/moment8aVry/article/details/138587080
三、图表元素检测模块
1、position_encoding.py 和 transformer.py
2、detr.py
3、


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









