






 本文介绍了Spark与Hadoop集群的搭建过程。包括master节点的文件下载、解压移动、配置文件修改,如修改 /etc/profile、$SPARK_HOME/conf/spark-env.sh等;slave节点则是复制配置好的spark文件并修改 /etc/profile。最后启动hadoop和spark,还提及了可能出现的问题及解决办法。
本文介绍了Spark与Hadoop集群的搭建过程。包括master节点的文件下载、解压移动、配置文件修改,如修改 /etc/profile、$SPARK_HOME/conf/spark-env.sh等;slave节点则是复制配置好的spark文件并修改 /etc/profile。最后启动hadoop和spark,还提及了可能出现的问题及解决办法。
在第一节中也讲了部分的spark的搭建,这里再提一下。
master节点:
1.下载文件:
wget -O "spark-2.1.0-bin-hadoop2.7.tgz" "http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.7.tgz"
2.解压并移动至相应的文件夹;
tar -xvf spark-2.1.0-bin-hadoop2.7.tgz mv spark-2.1.0-bin-hadoop2.7 /opt
3.修改相应的配置文件:
(1)修改 /etc/profie
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin
激活环境 source /etc/profile
(2)修改 $SPARK_HOME/conf/spark-env.sh
首先复制模版配置文件
cp spark-env.sh.template spark-env.sh
进行修改刚才复制的模板配置文件
export SCALA_HOME=/usr/lib/scala
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_25
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=2g
export HADOOP_HOME=/opt/hadoop-2.7.3
export HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_WEBUI_PORT=8088
#定义master域名和端口
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
#定义master的地址slave节点使用
export SPARK_MASTER_IP=master
#定义work节点的管理端口.work节点使用
export SPARK_WORKER_WEBUI_PORT=8088
#每个worker节点能够最大分配给exectors的内存大小
export SPARK_PID_DIR=/home/ap/spark/app/pids
#export PYSPARK_PYTHON=/root/anaconda3/bin/python3
#export PYSPARK_DRIVER_PYTHON=/root/anaconda3/bin/python3
(3)修改 $SPARK_HOME/conf/slaves
首先复制模版配置文件
cp slaves.template slaves
配置内容如下
master
slave1
slave2
(3)修改 $SPARK_HOME/conf/spark-defaults.conf
spark.eventLog.enabled=true
spark.eventLog.compress=true
#保存在本地
#spark.eventLog.dir=file://opt/hadoop-2.7.3/logs/userlogs
#spark.history.fs.logDirectory=file://opt/hadoop-2.7.3/logs/userlogs#保存在hdfs上
spark.eventLog.dir=hdfs://master:9000/tmp/logs/root/logs
spark.history.fs.logDirectory=hdfs://master:9000/tmp/logs/root/logs
spark.yarn.historyServer.address=master:18080
至此,master节点修改完毕
slave节点:
将配置好的spark文件复制到workerN节点
scp -r spark-2.1.0-bin-hadoop2.7 root@slave1:/opt
scp -r spark-2.1.0-bin-hadoop2.7 root@slave2:/opt
并且修改/etc/profile,增加spark相关的配置,如master节点一样
master和slave节点配置完毕后,就可以启动spark了,
启动时,先启动hadoop下的start-all.sh
再启动hadoop下的start-all.sh,运行jps命令后出现下面的结果即为安装成功
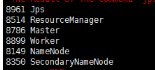
Q1:在下一节打开spark-shell后出现java.lang.IllegalArgumentException: Log directory hdfs://master:9000/tmp/logs/root/logs is not a directory.,需要在相应的目录下建立目录logs,而不是建立文件logs!!!!!!


















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











