







 Redis源码主要涉及对象创建、持久化策略(RDB和AOF)、主从复制、哨兵模式及集群模式。RDB通过fork子进程实现快照持久化,可能造成短暂阻塞;AOF记录写操作日志,提供数据安全性。哨兵模式监控主从服务器,自动故障转移。集群模式实现数据分布式存储,通过slot分片管理。
Redis源码主要涉及对象创建、持久化策略(RDB和AOF)、主从复制、哨兵模式及集群模式。RDB通过fork子进程实现快照持久化,可能造成短暂阻塞;AOF记录写操作日志,提供数据安全性。哨兵模式监控主从服务器,自动故障转移。集群模式实现数据分布式存储,通过slot分片管理。
Redis
源码大概做了哪些事情?
- 设置默认参数
- 创建对象、持久化定时器回调
- 加载文件参数 (使用配置文件替代部分默认参数)
- 加载文件数据写入字典
- 创建client connect事件handler(accept后,写入读写事件select(),最新的版本用epoll)
- 遍历网络事件链表以及定时器链表
- 退出
三种集群
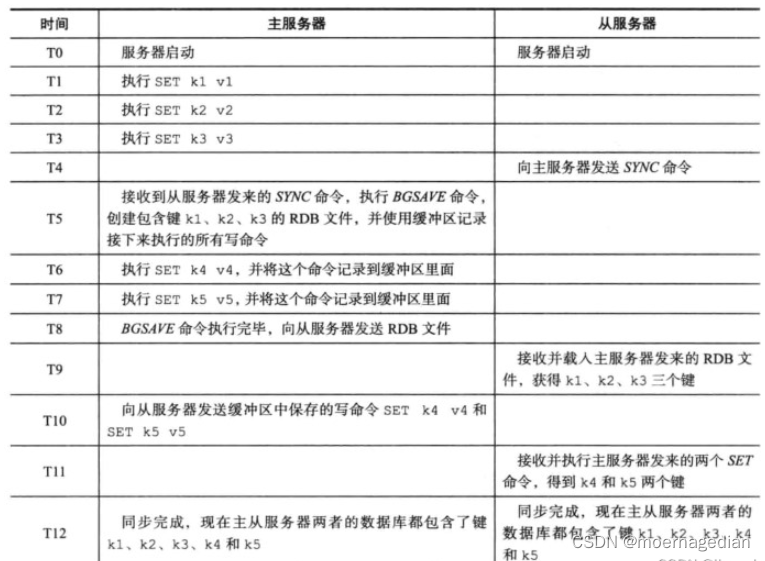
1.主从复制
从服务器主动获取 主服务器的数据
2.哨兵模式
一个或多个Sentinel实例(instance)组成的Sentinel系统(system)可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在主服务器下线时可以自动切换从服务器升级为主服务器。
过程:主观下线->客观下线->选举 Leader
缺点:
- Redis主机宕机后,哨兵模式正在投票选举的情况之外,因为投票选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机。
- 只有一个主节点对外提高服务,没办法支持很高的并发
- 单个主节点的内存不宜设置得过大,否则会导致持久会文件过大,影响数据恢复。
3.集群模式
哨兵模式基本已经实现了高可用,但是每台机器都存储相同内容,很浪费内存,所以集群模式实现了分布式存储。每台机器节点上存储不同的内容。
集群模式要求至少需要3个master才能组成一个集群,同时每个master至少需要有一个slave节点。各个节点之间保持TCP通信。当master发生了宕机, Redis Cluster自动会将对应的slave节点提拔为master,来重新对外提供服务。
Redis Cluster 使用分片机制,在内部分为 16384 个 slot 插槽,分布在所有 master 节点上,每个 master 节点负责一部分 slot。数据操作时按 key 做 CRC16 来计算在哪个 slot,由哪个 master 进行处理。数据的冗余是通过 slave 节点来保障
持久化
RDB
Redis RDB持久化是对某一时刻的内存中的全量数据进行拍照。
父进程在保存RDB文件时唯一要做的就是fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无需执行任何磁盘I/O操作。
快照的时候数据修改
Redis 借助了操作系统提供的写时复制技术,bgsave fork子进程的时候只复制必要的虚拟数据结构,并不为其分配真实的物理空间,它与父进程共享同一个物理内存空间。
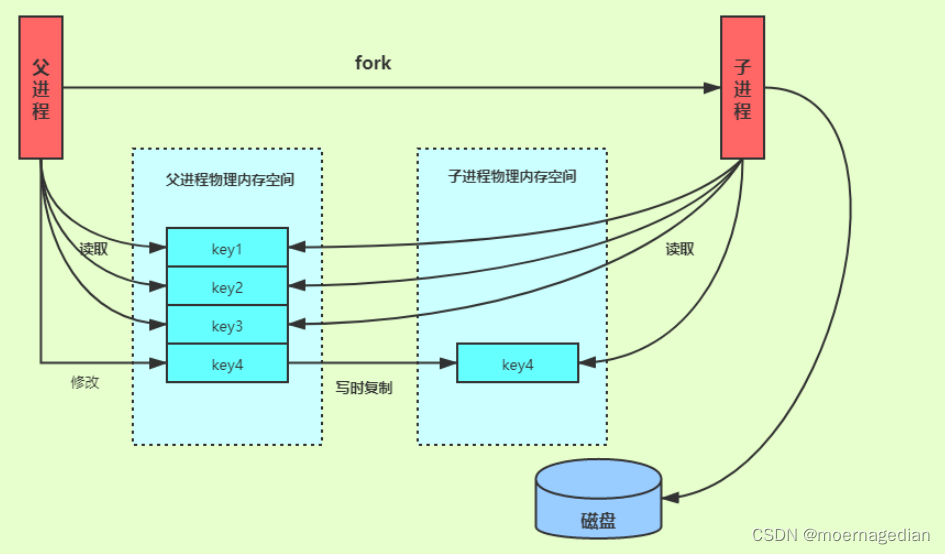
主线程要修改一块数据,此时会给子进程分配一块物理内存空间,把要修改的数据复制一份,生成该数据的副本到子进程的物理内存空间。然后,bgsave 子进程会把这个副本数据写入 RDB 文件。
缺点
-
1.bgsave所fork出来的子进程执行操作虽然并不会阻塞父进程的操作,但是fork出子进程的操作却是由主进程完成的,会阻塞主进程,fork子进程需要拷贝进程必要的数据结构,其中有一项就是拷贝内存页表(虚拟内存和物理内存的映射索引表),这个拷贝过程会消耗大量CPU资源,拷贝完成之前整个进程是会阻塞的,阻塞时间取决于整个实例的内存大小,实例越大,内存页表越大,fork阻塞时间也就越久。
-
2.Redis异常退出,就会丢失最后一次快照以后更改的所有数据。
RDB文件的载入
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
RDB 在恢复大数据集时,速度比 AOF 的恢复速度要快。
AOF
AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍,就这么简单。
AOF重写
- redis会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
- 主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
- 当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中。
- 当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









